Claude Code in Large Codebases: The 2026 Implementation Guide
TL;DR
- Claude Code works in large codebases when the setup is treated as engineering infrastructure: lean layered CLAUDE.md files, path-scoped skills, hooks, permissions, and a human-owned review loop.
- The context strategy for a million-line repo is not "load the whole codebase"; it is route the task to the smallest relevant directory, keep the root file as a map, move repeatable expertise into skills, and use LSP or MCP when text search is too noisy.
- At AI Heroes, we use worktree isolation, explicit file ownership, test gates, and review rituals before we let parallel agents touch client repos, because parallelism only helps after coordination is designed.
Claude Code does not become useful in a million-line codebase by being told to "look around and fix it." That is how teams get locally plausible edits in the wrong module and a senior engineer spending the afternoon explaining context the agent should have had before it touched a file.
The better pattern is more boring and much more powerful: build the harness first. Anthropic's own large-codebase guidance is right about the ingredients: CLAUDE.md, skills, hooks, plugins, LSP, MCP, and subagents. The missing piece is the operator layer. Someone has to decide what belongs in each file, who owns the setup, which jobs can run in parallel, and where human review stops being optional.
That is the implementation problem AI Heroes cares about. We do not sell Claude Code as a magic repo reader. We use it as a specialist agent inside a governed engineering system.
How does Claude Code work in a large codebase?
Claude Code works in a large codebase by progressively finding and using the relevant slice of the repository, not by holding every file in active context at once. The practical goal is to make the right context cheap to find and the wrong context hard to load.
Anthropic describes the core extension layer clearly: CLAUDE.md provides project context, skills load specialized workflows on demand, hooks run at session events, plugins distribute working setups, LSP integrations improve symbol navigation, MCP servers expose internal tools, and subagents split work into isolated contexts. In other words, the product is not just a coding chatbot. It is an agent runtime that can be wired into the way a serious engineering team already works.
The difference between a toy setup and a production setup is whether those pieces have ownership. A root CLAUDE.md that grew to 900 lines because every team added their favourite instruction is not memory. A subagent that edits files without a lane assignment is not leverage. A hook that blocks destructive commands is useful; a hook that tries to encode a senior engineer's entire judgment is theatre.
Our rule is simple: Claude Code should enter a repo the way a strong new engineer does. It gets a map, local conventions, the commands that prove work, and clear boundaries. Then it earns more autonomy.
What's the context-window strategy for million-line repos?
The best context-window strategy for a million-line repo is progressive disclosure. Keep the root context short, load local context only when the agent enters that area, and move repeatable expertise into skills or tools that activate only when needed.
Anthropic's docs now explicitly recommend keeping CLAUDE.md under 200 lines and moving reference material into skills. That matches our experience. The root file should answer four questions: what is this repo, where are the major systems, what must never be touched casually, and which commands prove a change. Everything else should be layered.
| Context layer | What belongs there | What does not belong there | Large-repo failure it prevents |
|---|---|---|---|
| Root CLAUDE.md | Repo map, non-negotiable rules, top-level test/build commands, critical gotchas | Long tutorials, every team's preferences, historical debates | The agent starts in the right world without dragging the whole company into every prompt |
| Directory CLAUDE.md | Local architecture, service-specific commands, naming rules, owners, fixtures | Global policy or unrelated service notes | A change in billing does not inherit irrelevant frontend guidance |
| Skills | Repeatable workflows such as security review, release notes, schema migration, documentation update | Facts needed on every request | Specialist expertise loads only when the task calls for it |
| Hooks | Automatic checks, logging, permission boundaries, reminders before risky tools | Subjective judgement that needs a human | Guardrails run reliably instead of depending on prompts |
| LSP and MCP | Symbol lookup, internal docs, issue trackers, analytics, service catalogs | Basic repo instructions | Claude asks tools for structured context instead of opening random files |
This is where most teams under-invest. They spend hours comparing models and almost no time building the repo map. In large codebases, retrieval discipline beats prompt cleverness.
How do you scaffold CLAUDE.md for an enterprise codebase?
Start with the root CLAUDE.md as a table of contents, not a handbook. If a new staff engineer would not need the detail on day one, Claude probably should not load it on every request.
A practical root file has six sections: repository purpose, top-level folder map, setup commands, verification commands, safety rules, and links to deeper docs. Each major service then gets its own local CLAUDE.md with local commands, test fixtures, ownership, and "do not break" notes. Generated code, vendor directories, build artifacts, and irrelevant data dumps should be excluded through version-controlled settings where possible, with exceptions for teams that actually work on generators.
The line between CLAUDE.md and skills matters. CLAUDE.md is persistent context. A skill is repeatable expertise. "Always run the auth package tests before touching login" belongs in local CLAUDE.md. "Perform a security review of OAuth callback changes" belongs in a skill. "Never edit generated Prisma output by hand" belongs in settings or a hook.
The maintenance rule matters too. Anthropic suggests configuration reviews every three to six months, and sooner when model releases change behaviour. We agree. Instructions written to compensate for an older model can become drag after the model improves. Your agent memory should be maintained like infrastructure, not fossilised like a wiki page.
When should you use subagents vs a single-agent flow?
Use a single Claude Code flow when the task needs one coherent line of reasoning. Use subagents or parallel lanes when the work can be separated by responsibility, file ownership, and output contract.
The mistake is treating subagents as free intelligence. They are not. They are separate contexts with coordination cost. They shine when exploration can happen away from the main session, or when independent workstreams can run in isolated worktrees. They hurt when two agents edit the same files, duplicate the same investigation, or return prose the lead agent cannot verify.
| Decision point | Single-agent Claude Code flow | Parallel worktree multi-agent flow |
|---|---|---|
| Best fit | Ambiguous refactor, architectural decision, one subsystem with tight coupling | Independent packages, separate services, research plus implementation, test generation across disjoint areas |
| Latency | Slower wall-clock, lower coordination overhead | Faster wall-clock when lanes are truly independent |
| Conflict risk | Lower because one agent owns the edit path | Higher unless each lane has file ownership and its own git worktree |
| Review overhead | One diff narrative to review | Multiple diffs plus an integration review |
| Observability | One transcript and one plan | Per-lane transcripts, branch names, verification summaries, and integration notes |
| Recovery cost | Rewind or start a fresh session | Reset the affected lane to its base ref and rerun only that lane |
| AI Heroes default | Use for most deep code-changing work | Use when ownership boundaries are explicit before launch |
Our internal orchestration rule is deliberately strict: two lanes that touch the same file are not parallel work. They are sequential work wearing a costume. If you want parallelism, give each lane its own worktree, base ref, file list, and verification contract.
Claude Code vs Cursor vs Cline - which wins in big repos?
Claude Code, Cursor, and Cline can all help in large repositories, but they optimise for different operating models. The right question is not "which one is smartest?" It is "where should the agent live, and how much orchestration do we need around it?"
| Capability | Claude Code | Cursor | Cline |
|---|---|---|---|
| Primary surface | Agentic coding runtime across terminal, IDE, web, and managed workflows | AI-first IDE with codebase index, rules, chat, and agent modes | VS Code agent with explicit Plan and Act modes |
| Large-repo context pattern | Layered CLAUDE.md, skills, hooks, plugins, LSP, MCP, subagents | Codebase indexing, rules in .cursor/rules, Ask/Chat/Agent workflows | Plan mode, file mentions, checkpoints, deep-planning for large tasks |
| Best use | Deep repo work that needs repeatable team conventions and orchestration | Everyday developer velocity inside an IDE | Developers who want a visible planning boundary before edits |
| Governance fit | Strong when a team owns skills, hooks, permissions, plugins, and review policy | Strong when rules and index settings are versioned and team-managed | Strong when Plan/Act discipline and checkpoints are enforced |
| Weak point | Bad setups become context bloat and tribal conventions | IDE-local habits can drift if rules are not curated | Large tasks can sprawl if planning artifacts are not written down |
| AI Heroes take | Best default for orchestrated engineering-agent deployments | Excellent developer cockpit, especially when codebase indexing is the win | Useful for teams that want explicit think-then-edit workflow inside VS Code |
Cursor's public large-codebase material emphasises indexing, rules, and planning with Ask mode before Agent mode. Cline's docs make the planning boundary even more explicit: Plan mode explores and discusses without file edits, Act mode executes, and large tasks should use deep planning plus checkpoints. Those are good patterns. Claude Code's advantage is that the extension layer is now broad enough to become a team-level operating system, not just an individual developer aid.
How do you onboard an engineering team to Claude Code at scale?
Onboarding a team to Claude Code at scale starts with a designated owner. Anthropic calls out the need for a DRI or team that owns settings, permissions, plugin marketplace, and conventions. Without that owner, bottom-up adoption turns into private rituals: one engineer has a great setup, another has none, and the organisation learns nothing.
Our rollout pattern is four phases.
First, pick two or three representative services, not the whole monorepo. Build the root map, local CLAUDE.md files, ignore rules, and verification commands there. Run real maintenance tasks, not demos.
Second, package the repeatable pieces. If a security review prompt works, make it a skill. If a permission rule matters, make it a hook or settings entry. If a tool connection is valuable, expose it through MCP instead of asking people to paste data into chat.
Third, teach the review habit. Every meaningful Claude Code change should arrive with a short plan, files changed, commands run, tests passed or skipped, and residual risk.
Fourth, widen access only after the setup survives boring work. The first sign of maturity is not a spectacular refactor. It is a routine bug fix that lands with the right tests, the right owner, and no senior engineer cleaning up process debt.
What implementation pattern do we use at AI Heroes?
The AI Heroes pattern is an operations layer around Claude Code: brief, scope, isolate, verify, review, then integrate. We learned this from running OpenClaw-style orchestration, Cowork plugins, and parallel agent workflows where the failure mode is not "the model is dumb." The failure mode is that the system around the model lets smart agents step on each other.
For serious client repos, we write the task like a small engineering contract. The brief names the objective, product context, constraints, acceptance criteria, verification commands, prior pitfalls, and file ownership. If more than one agent will edit, each lane gets its own worktree and branch. The lead agent does not hand two workers the same file and hope Git sorts it out later.
Hooks handle the mechanical boundaries: command logging, destructive-operation blocks, permission prompts, and reminders before risky tools. Skills handle specialist procedures: release review, documentation update, SEO/GEO checks, security audit, or proposal packaging. MCP handles structured access to outside systems. Humans handle judgement, merge decisions, and accountability.
That is the category term we think matters: large-codebase agent orchestration. It is the discipline of turning coding agents from clever sessions into a governed delivery system.
What should teams avoid overclaiming?
Do not claim Claude Code "understands the whole repo" unless you have built the context path that lets it find the right slice. Do not claim subagents multiply engineering output if they share a worktree, edit overlapping files, or return unverified prose. Do not claim hooks solve governance if they are only reminders in a prompt.
Do not migrate every workflow at once. Start with observable tasks: test generation, docs drift, dependency upgrades, narrow refactors, issue reproduction, code archaeology, PR summaries, and review support. Keep production writes, customer messaging, billing logic, and security-sensitive changes behind stronger review gates.
The high-trust version of Claude Code is not less human. It is more explicit about where the human is needed.
What is the 30-day rollout plan?
In week one, appoint the owner and map the repo. Write the root CLAUDE.md, identify generated or vendor noise, and choose pilot services.
In week two, add local CLAUDE.md files and verification commands for those services. Run read-only archaeology sessions first. Ask Claude Code to explain dependency paths, test boundaries, and likely risk areas before it edits anything.
In week three, package repeatable workflows as skills and add hooks for mechanical safety. Start with a review skill, a documentation-update skill, and a pre-tool hook for destructive commands or sensitive paths.
In week four, introduce parallel lanes only for disjoint work. Require worktrees, branch naming, file ownership, and final verification summaries. Keep a human integration owner.
If the team cannot maintain that system, it is not ready for more autonomy. If it can, Claude Code stops being a novelty and becomes part of the engineering operating model.
Authoritative sources
- Anthropic: How Claude Code works in large codebases
- Claude Code docs: Extend Claude Code
- Claude Code docs: Hooks reference
- Claude Code docs: Create custom subagents
- Cursor docs: Large codebases
- Cline docs: Plan & Act Mode
Related reading
The agent built for this

Richard
A forward-deployed AI agent that gets your software live and adopted inside every customer.
Meet RichardFrequently Asked Questions

Founder, AI Heroes
I build AI companies and the systems inside them. At AI Heroes, we give businesses the functional capacity to grow without the headcount growth normally demands — sales that follows up, marketing that runs, content that ships, ops that handles itself. We audit where you're leaving growth on the table, build the team that captures it, and hand it over completely.
I've built at scale before. Leading product and GTM at SlideSpeak AI (1M+ monthly users, profitable, bootstrapped). CPO at Disperse — the AI construction platform that went from 3 to 200+ people on $35M raised. I also co-founded LOBOMAR, a luxury fashion label featured in Elle, Cosmopolitan, and the LA Times, with shows at the London Design Museum, Wereldmuseum, and Amsterdam Fashion Week.
Related Articles
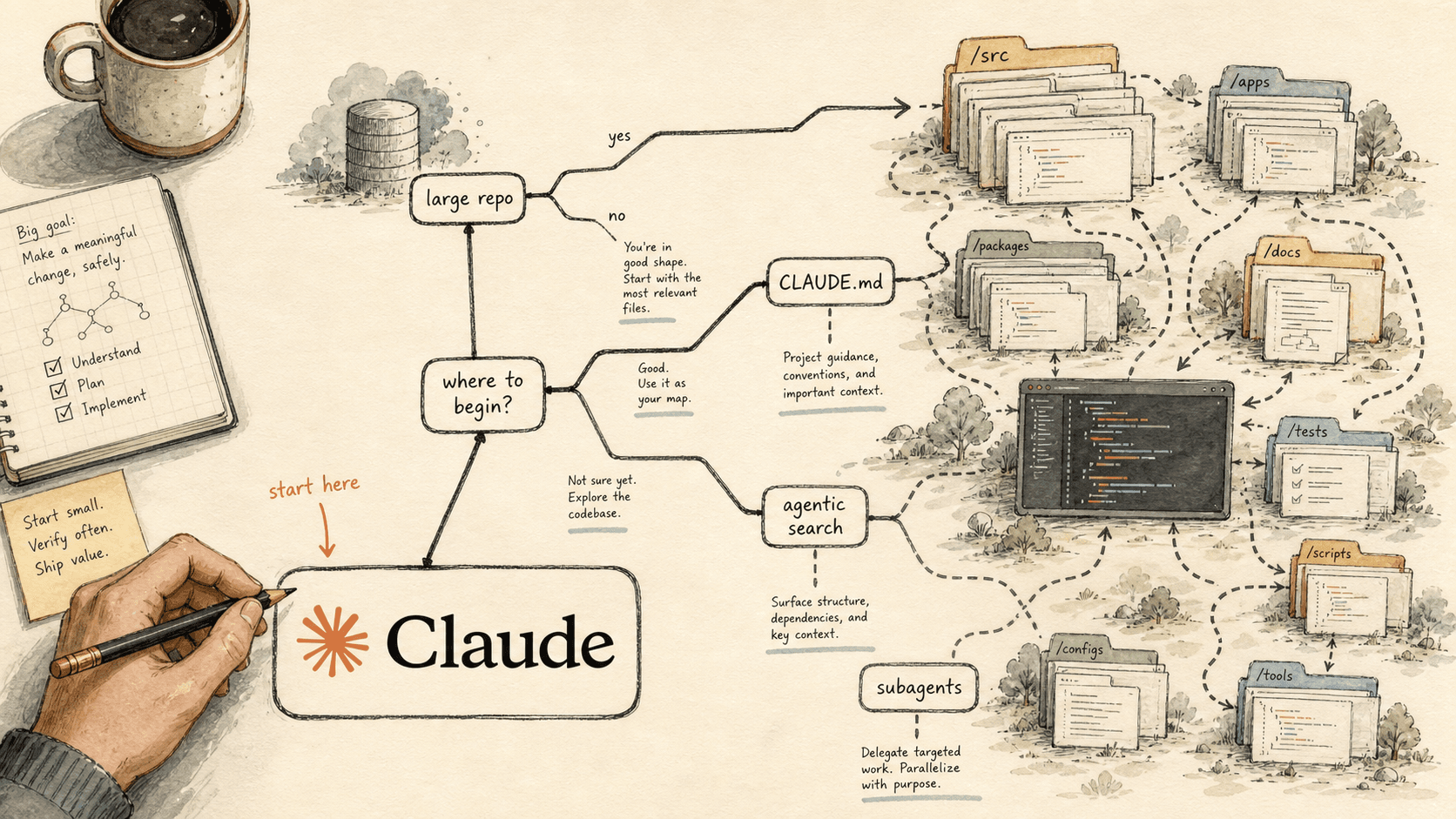
Where to Start With Claude Code in a Large Repo: A Decision Tree (2026)
You do not start a large Claude Code rollout by configuring everything. You start with the one mechanic your repo shape and your actual pain point demand — and ignore the rest until you hit them. This is the decision layer that runs before the build.

Claude Code + HTML: The 2026 Implementation Guide to the Right Output Medium
Anthropic's own engineers have moved Claude Code outputs to HTML for almost everything. The implementation question is when HTML wins, when it doesn't, and how the handoff from Claude Design to Claude Code should actually look.

The House Keys Problem: What OpenClaw and Claude Code Are Really Fighting About
There's a story about the moment OpenClaw clicked for its creator. It involves house keys, a sleeping founder, and an agent that booked a restaurant without being asked. That story still tells you everything you need to know — even now that Claude Code has started asking for a small keyring of its own.