TL;DR
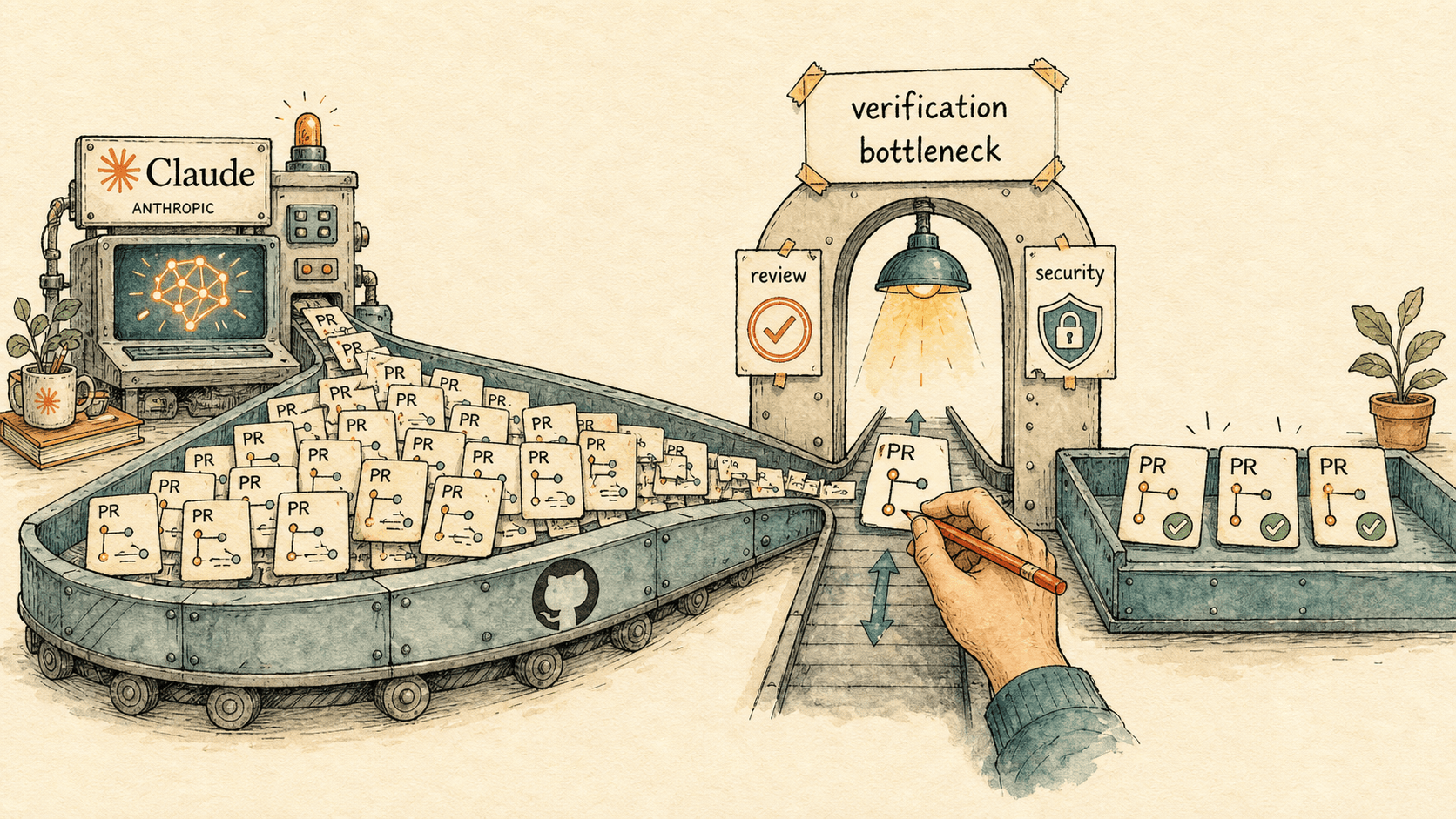
- When agentic coding becomes the default, the engineering bottleneck doesn't disappear — it moves. Writing, testing and refactoring code stop being the constraint; verification, code review and security become it. Anthropic's Claude Code team says this in plain terms, and the independent 2026 data backs it up.
- The verification bottleneck is now measurable. By Sonar's 2026 survey of more than 1,100 professional developers, AI writes roughly 42% of committed code — yet 96% of developers say they don't fully trust it is correct, and only 48% always check it before committing. Review queues, not keyboards, are where the time now goes.
- Running an AI-native engineering org is the discipline of redesigning four things around that one relocation — planning, context-gathering, code review and team makeup — then measuring leading indicators (onboarding ramp, PR cycle time, AI-assisted-commit share) without mistaking throughput for success. Bolt AI onto processes built for the old bottleneck and you get whiplash; redesign around the new one and you get the gain.
For two decades, engineering bandwidth was the expensive part of building software. Waterfall, then agile, then continuous delivery — every process leaders put in place was shaped around the cost of people writing code. Agentic coding pulls that assumption out from under the whole stack. When a model writes, tests and refactors most of the code, the question stops being "how do we ship faster?" and becomes "how do we trust what we just shipped, and who still needs to look at it?"
Anthropic's own Claude Code team has been unusually candid about this. At Code w/ Claude SF 2026, Fiona Fung — Director of Engineering for Claude Code and Claude Cowork — described how the team rewrote its norms once agentic coding became the default. Her sharpest line is the one most leaders underweight: writing code "rarely slows us down anymore. But the bottlenecks didn't go away when agentic coding took away the actual need to type code. Verification, code review, and security took their place." This article takes that observation, anchors it, and turns it into an operating model any engineering org — not just the one that builds the model — can actually run.
What is an AI-native engineering org?
An AI-native engineering org is one whose planning, review, roles and metrics have been redesigned around agentic coding as the default way of working, rather than bolted on top of processes built for the era when humans typed most of the code. The distinction matters because the failure mode is so common: teams adopt the tools, keep the old workflow, and are surprised when output goes up but outcomes don't.
The defining shift is not "we use AI now." It is that the scarce resource has changed. Code generation has become abundant and cheap; trusted verification has become the constraint. An org that has internalized that — and rebuilt its processes accordingly — is AI-native. An org that has the tools but the old shape is just an AI-assisted version of its former self, usually a slower one.
What actually changes when AI writes most of the code?
The bottleneck relocates from producing code to verifying it, and most of an organization's existing process was built to protect the wrong end of that pipeline. The 2026 numbers make the scale concrete. Sonar's State of Code survey of over 1,100 developers puts AI at about 42% of committed code, rising to an expected 65% by 2027. GitHub reports AI coding assistants now generate close to half the code on its platform, and Gartner has projected 60% of new code will be AI-generated by the end of 2026. Different methodologies, different exact figures — but every credible source points the same direction: the volume of code arriving at the review queue has stepped up sharply.
What hasn't scaled is human attention. In the same Sonar data, 96% of developers say they don't fully trust that AI-generated code is functionally correct, yet only 48% always check it before committing. Independent engineering-leadership coverage through 2026 describes the consequence as a review bottleneck: more code generated than humans can read, comprehend and validate, with the pressure landing on the most senior reviewers. Several analyses report PR review time climbing even as merge throughput rises — the pattern some have called "acceleration whiplash," where the top of the funnel speeds up and every stage below it backs up.
That is the structural change. Not "engineers are faster" — engineers are differently loaded. The expensive, judgment-heavy work moved downstream, and a process designed to ration scarce coding time now rations the wrong thing.
What is the verification bottleneck?
The verification bottleneck is the point in an AI-native software pipeline where trusted human review, security scrutiny and correctness checking — not code generation — becomes the limiting factor on how fast and how safely a team can ship. It is the agentic-coding analog of a factory whose machines suddenly produce ten times the parts while the single quality-inspection station stays the same size: total output is now capped by inspection, and adding more machines makes the queue worse, not better.
Naming it matters because it tells you where to spend. If the constraint is verification, then buying more generation capacity — more seats, more agents, more orchestration — pushes more work into the queue that is already the bottleneck. The leverage is on the other side: making verification faster and better-targeted. That means letting the model handle the verification it can do reliably (style, linting, test generation, first-pass bug-catching) and reserving human judgment for the places it actually changes the outcome. Anthropic's team routes exactly this way — Claude handles style, linting, PR-feedback requests and catching bugs before commit through its Code Review workflow, and humans are kept "where it matters": legal risk tolerance, trust boundaries and security-sensitive code, and product taste.
Which engineering processes quietly stop working?
Four norms break first, and an AI-native org rewrites each of them deliberately rather than waiting for them to fail. Fung's framing is that obsolete processes "rarely go away on their own" — they have to be actively killed. Here is what changes and why.
| Process | Built for the old bottleneck | Rebuilt for the new one |
|---|---|---|
| Planning | Six-month roadmaps and heavy design docs, because coding time was expensive and worth pre-planning. | Just-in-time planning: prototype, put internal users on it, act on feedback. Roadmaps written six months out are obsolete by month three. |
| Context-gathering | "Who wrote this code?" — find the author and ask them. | Ask the codebase, not the author. Decide what you actually need — who caused a regression, the reasoning behind a decision — then ask the model, and ask whether the question can be automated away entirely. |
| Code review | Humans review everything. | The model handles style, linting, tests and first-pass bug-catching. Humans review where domain expertise is decisive: security, legal, product taste. |
| Team makeup | Fixed roles — engineers code, PMs plan, designers design. | Roles blur. PMs prototype in code; engineers take on design and content. Hire for creative builders with product sense and engineers with deep systems expertise — not for raw throughput, which the models now supply. |
The through-line is that each old process optimized for the cost of writing code. Once that cost collapses, the process is either neutral or actively in the way. Just-in-time planning isn't "less planning" — it is planning matched to a world where the cost of changing direction is now low. "Ask the codebase" isn't laziness — it is recognizing that the fastest path to context is no longer a human's calendar.
How should code review work in an AI-native org?
Code review becomes a division of labor between the model and human experts, with the boundary moving every time the model improves. The reliable rule is "trust but verify": let the model own the mechanical and high-volume checks, and concentrate human review on the categories where being wrong is expensive and judgment is irreducible — security and trust boundaries, legal and risk tolerance, and product sense.
The part leaders miss is that this boundary is not fixed. Fung is explicit that "the right balance of trust vs. verify will keep changing as the models improve. What you need humans for today might look different with the next model." That makes the trust-but-verify boundary a thing to re-examine on a schedule, not set once. An org that hard-codes "humans review everything" wastes its scarcest resource on checks the model now does well; an org that quietly lets the model review security-sensitive code because it got good at the easy stuff is courting the 23%-higher incident rates some 2026 analyses associate with under-reviewed AI PRs. The discipline is to keep asking, release over release, which verification still needs a human — and to move the line on evidence, not vibes.
How do you roll new norms out without chaos?
You mandate a small set of non-negotiable principles and let teams own everything else. Anthropic's Claude Code team runs on three "must-dos," with wide pod autonomy inside them:
- Relentlessly dogfood your product. Every team member, including cross-functional partners, uses the product daily and looks for the next workflow to automate. You cannot redesign around AI from the outside.
- Keep the team as flat as possible. Managers start as ICs, ship real code, and support pods of work while people move to where the work is. A flat structure lets the org re-form around the work faster than the work changes.
- Don't hesitate to kill processes that no longer work. Team members have explicit permission to question and retire any process whose original gap has closed.
Within those rules, pods decide their own triage, standups, planning rituals and which workflows get automated first. This is the part that travels well to non-Anthropic orgs: you do not need to dictate every workflow centrally. You need a few load-bearing principles, permission to kill dead process, and small teams with the agency to redesign their own corner. Turning a recurring, manual ritual into something that runs as an automated routine is exactly the pod-level move that compounds.
How do you know your AI-native transition is actually working?
You track leading indicators of the new bottleneck, and you refuse to mistake throughput for success. Three numbers are worth watching from day one — but each needs a guardrail, because the obvious version of each can be gamed or misread.
| Metric | What it tells you | The guardrail |
|---|---|---|
| Onboarding ramp time | How fast a new engineer, designer or PM becomes effective. On an AI-native team this should fall sharply — new hires shipping real code within a week. | Ramp time is meaningless if early "shipped" work just adds to the review backlog. Measure ramp to reviewed, merged, stable contribution. |
| PR cycle time | Where your pipeline strains as code volume rises — often CI and review capacity, the verification bottleneck made visible. | Decompose it. Rising time-to-first-review (code waiting in the queue) is the bottleneck signal; rising review duration once picked up may be healthy scrutiny. |
| AI-assisted commit share | How deeply agentic coding has actually become the default. On a mature team this trends toward "nearly every commit." | This is the one most likely to become a vanity metric. High AI-assisted share with rising defect or churn rates means you are generating faster than you are verifying. |
The honest caveat, in Fung's words: "don't confuse throughput with success. Throughput is one metric, but the real metric is measuring the thing you're trying to solve." This is also where the standard delivery dashboards fall short. The widely-used DORA metrics still matter, but 2026 analyses are blunt that they cannot, on their own, distinguish AI-generated from human-authored code or surface the quality cost building up underneath rising velocity. The fix engineering-leadership researchers converge on is to add an AI-attribution lens — segment your metrics by how much of the change was AI-generated, and watch code-churn ratios — so that "we shipped more" can be checked against "and it held up." A verification and evaluation gate that an agent's output must pass before it counts as done is the same instinct applied at the workflow level.
Where should an engineering leader start?
Start with your noisiest workflow — the most expensive, most dreaded, or least-loved one — and ask whether it still serves its purpose, then whether it can be automated. Fung's example is the recurring status meeting where everyone sat on their laptops until it was their turn to report; one question — "why are we having this meeting?" — was enough to kill it. The point generalizes: the first move in becoming AI-native is not buying tools, it is auditing process for the gaps that have already closed.
If you want a sharper entry point, pick the workflow that sits closest to the verification bottleneck. Automating code generation when your review queue is already backed up just feeds the constraint. Automating triage, first-pass review, test generation or context-gathering relieves it. The same logic applies to where you introduce agents at all: match the first mechanic to your actual pain, the way our decision tree for large repos does, rather than standing up a surface you can't yet debug. And keep the stack lean — an over-built scaffold accumulates harness debt and quietly fights the model you are paying for.
The orgs that win the next two years won't be the ones that generated the most code. They will be the ones that noticed the bottleneck moved, and rebuilt around it before their competitors did.
Authoritative sources & related reading
-
Anthropic / Claude — Running an AI-native engineering org (primary source; Fiona Fung, Code w/ Claude SF 2026)
-
Anthropic / Claude — Code Review (Claude Code docs) (how the model handles style, linting and first-pass bug-catching)
-
Anthropic / Claude — Claude Code on the web (running agents beyond the terminal — the systems work behind "run Claude everywhere")
-
Sonar — State of Code Developer Survey 2026 (1,100+ developers: ~42% of committed code AI-generated; 96% don't fully trust it, 48% always verify)
-
GitHub / Gartner — AI now generates close to half of code on GitHub; Gartner projects 60% of new code AI-generated by end of 2026
-
DORA / engineering-leadership analyses (2026) — why DORA metrics need an AI-attribution lens to separate throughput gains from quality cost
-
AI Heroes: Harness debt: your AI agent scaffolding is quietly fighting the model — why a lean stack beats an elaborate one once the model improves.
-
AI Heroes: Where to start with Claude Code in a large repo: a decision tree — matching the first mechanic to your actual pain.
-
AI Heroes: Claude Code routines for software teams — turning a recurring manual ritual into an automated workflow.
-
AI Heroes: The long-running agent harness on the Claude Agent SDK — putting a verification-and-evaluation gate between an agent and "done."
The agent built for this

Richard
A forward-deployed AI agent that gets your software live and adopted inside every customer.
Meet RichardFrequently Asked Questions

Founder, AI Heroes
I build AI companies and the systems inside them. At AI Heroes, we give businesses the functional capacity to grow without the headcount growth normally demands — sales that follows up, marketing that runs, content that ships, ops that handles itself. We audit where you're leaving growth on the table, build the team that captures it, and hand it over completely.
I've built at scale before. Leading product and GTM at SlideSpeak AI (1M+ monthly users, profitable, bootstrapped). CPO at Disperse — the AI construction platform that went from 3 to 200+ people on $35M raised. I also co-founded LOBOMAR, a luxury fashion label featured in Elle, Cosmopolitan, and the LA Times, with shows at the London Design Museum, Wereldmuseum, and Amsterdam Fashion Week.
Related Articles
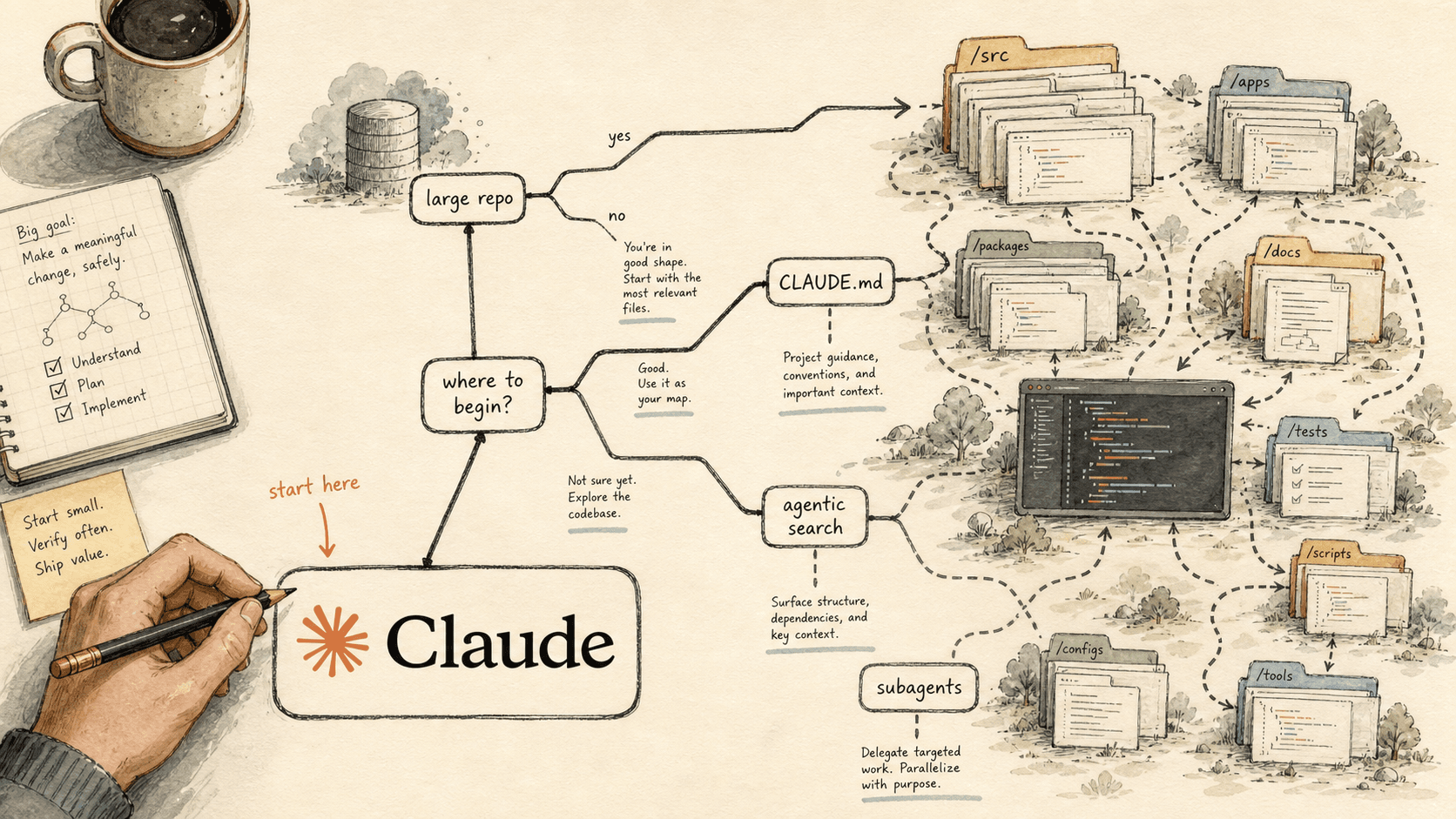
Where to Start With Claude Code in a Large Repo: A Decision Tree (2026)
You do not start a large Claude Code rollout by configuring everything. You start with the one mechanic your repo shape and your actual pain point demand — and ignore the rest until you hit them. This is the decision layer that runs before the build.

Harness Debt: Your AI Agent Scaffolding Is Quietly Fighting the Model (2026)
Your AI agent is probably worse than the model inside it — and the gap is your own scaffolding. An experimental harness scored over 2x Anthropic's standard one on the same model. The fix isn't a bigger framework; it's deleting the assumptions that went stale the day Claude Opus 4.6 shipped.

Claude Code + HTML: The 2026 Implementation Guide to the Right Output Medium
Anthropic's own engineers have moved Claude Code outputs to HTML for almost everything. The implementation question is when HTML wins, when it doesn't, and how the handoff from Claude Design to Claude Code should actually look.