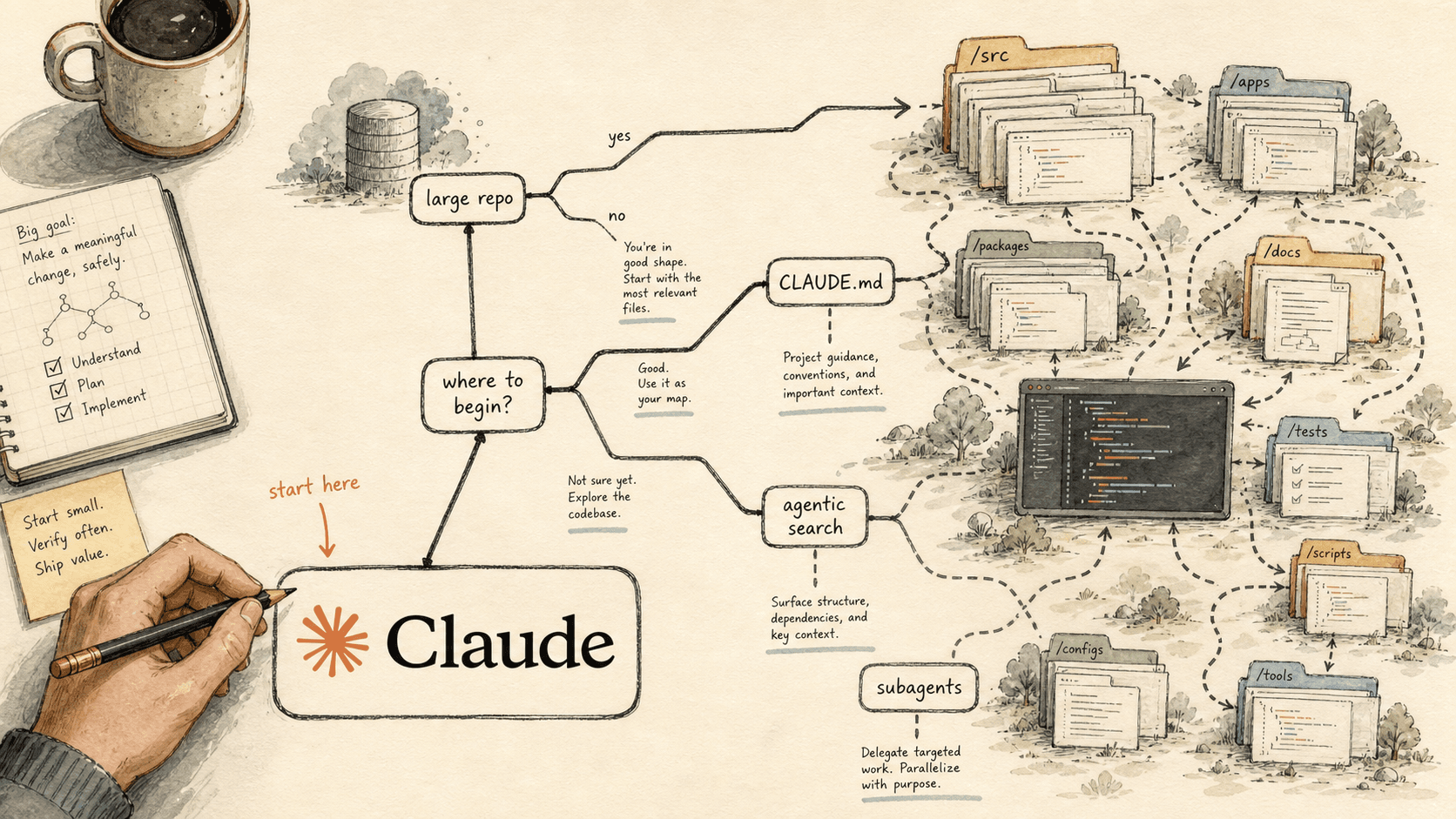
Where to Start With Claude Code in a Large Repo: A Decision Tree (2026)
TL;DR
- The first decision in a large Claude Code setup is not which features to turn on — it is which single mechanic your repo shape and pain point demand first. Configure that one, ship, then add the next only when you hit its trigger.
- The reason you can start narrow is agentic search: Claude Code explores a repo on demand by traversing files and running grep, with no embedding index to build or keep current. Repo size alone does not force a setup decision; repo shape and your actual failure do.
- Use the decision table below to map "my repo is X / my pain is Y" to one starting mechanic — scoped
CLAUDE.md, a subagent, leaning on agentic search, or a/compact-versus-fresh policy — then follow the linked implementation guide to build it.
Most teams adopting Claude Code on a serious repository try to configure everything at once — a root CLAUDE.md, nested files, skills, hooks, subagents, MCP — and end up with a large surface they do not understand and cannot debug. The faster route is to decide which one mechanic your situation requires first, stand it up, and leave the rest until a specific symptom forces it.
Anthropic's Applied AI team published its own account of running Claude Code in production "across multi-million-line monorepos, decades-old legacy systems, distributed architectures spanning dozens of repositories, and at organizations with thousands of developers." The useful part, for someone staring at a big repo on a Monday, is not the scale boast — it is that the right starting point differs by repo shape, not by line count. This is the decision layer; the implementation guide is where you build it.
How do you decide where to start with Claude Code in a large repo?
Start by matching your repo's shape and your single most painful symptom to one mechanic — not by enabling features in order. Claude Code's usefulness in a large codebase is, in Anthropic's words, "bounded by its ability to find the right context," and the failure cuts both ways: "Too much context loaded into every session degrades performance, while too little context leaves Claude to navigate blind." So the starting move is always the one that fixes your side of that imbalance.
Find the row below that matches your situation, start there, and treat every other mechanic as a later step triggered by a specific symptom.
| Your situation | Start here | Why (the mechanic) |
|---|---|---|
| Large monorepo, many services, root config feels wrong | Scoped CLAUDE.md in subdirectories, not the root | Claude "walks up the directory tree and loads every CLAUDE.md file it finds," concatenating root→cwd, so per-directory context is added without losing root context. |
| One huge repo, sessions feel slow or vague from the first prompt | A lean root CLAUDE.md (pointers + gotchas only, under ~200 lines) | A bloated context file degrades adherence — "Claude ignores half of it because important rules get lost in the noise." Lean context is the cheapest first win. |
| Investigation tasks blow up the session (reads hundreds of files) | A subagent for exploration | A subagent runs in "its own context window" and "returns only the summary," so exploration cost does not pollute the main thread. |
| You are debating whether to bolt on a vector index for "search" | Lean on built-in agentic search first | Agentic search has "no embedding pipeline or centralized index to maintain," and avoids index staleness — add a search sidecar only if you hit a measured token/latency wall. |
| Long sessions hit context limits mid-task | A /compact-versus-/clear policy | What survives /compact is rule-bound (see the survival table below); deciding when to compact versus start fresh prevents silent context loss. |
| Hundreds of thousands of folders / millions of files, or non-Git VCS | Stop and treat it as an edge case | Anthropic concedes "even the hierarchical CLAUDE.md approach breaks down" here — this is outside the conventional-repo design assumptions. |
One note before the branches: the token figures Anthropic uses to illustrate context costs (a 200,000-token window, a subagent reading 6,100 tokens and returning 420) are explicitly labelled representative in its own walkthrough — useful for intuition, not production constants.
Where should you point Claude Code first in a big repo?
Point it at the smallest directory that contains your task, and let it walk up to the root — do not start it at the repo root by default. This is the single most counter-intuitive starting move, because, as Anthropic notes, "tooling often assumes root access." Claude Code does not need that: "Claude automatically walks up the directory tree and loads every CLAUDE.md file it finds along the way, so root-level context is never lost."
Claude Code's memory documentation states the load algorithm precisely: it reads CLAUDE.md files "by walking up the directory tree from your current working directory," all discovered files are "concatenated into context rather than overriding each other," and content is "ordered from the filesystem root down to your working directory." Subdirectory files are not loaded at launch — they are "included when Claude reads files in those subdirectories."
So the starting decision for a monorepo is: put a CLAUDE.md in each major service directory, keep the root one as a thin map, and start your sessions inside the service you are actually working on. You get the root rules plus the local rules and nothing from the twelve services you are not touching — the cheapest way to give Claude Code the right context without drowning it.
How big does your repo have to be before CLAUDE.md scoping matters?
Scoping matters the moment a single root CLAUDE.md can no longer stay both complete and lean — which is a shape threshold, not a line-count threshold. Anthropic's guidance is to "target under 200 lines per CLAUDE.md file," because "longer files consume more context and reduce adherence." A small, single-purpose repo can keep everything it needs in one file under that ceiling. A monorepo cannot: the moment "complete" forces the root file past ~200 lines, you have crossed the line where scoping pays for itself.
The deeper reason lean context wins is independent of Anthropic. Chroma's "context rot" study tested 18 frontier models and found every one gets measurably worse as input length grows. Stanford's "Lost in the Middle" research adds the shape: models attend well to the start and end of their context and poorly to the middle, so rules buried in a long file are the ones most likely to be ignored. A 200-line CLAUDE.md is not a style preference — it puts your most important rules where the model actually reads them.
One non-obvious mechanic worth knowing before you over-invest in CLAUDE.md: it is advisory, not enforced. Claude Code's memory documentation states the content "is delivered as a user message after the system prompt, not as part of the system prompt itself," so "there's no guarantee of strict compliance." If a rule must hold every time — never touch this file, always run this command — that is a hook's job, not a CLAUDE.md line's.
So the rule of thumb is: one repo whose essential context fits under ~200 lines → a single lean CLAUDE.md. The moment completeness pushes you past that → scope into directories. Line count is a proxy; the real trigger is when one file can no longer be both complete and lean.
When should you reach for a subagent versus the main thread?
Reach for a subagent when a task would flood your main context with reading you will not keep — exploration, search, investigation — and stay on the main thread for the continuous editing work itself. Anthropic frames the split cleanly: "Subagents split exploration from editing." The mechanic underneath it is that a subagent is "an isolated Claude instance with its own context window" that does the heavy reading and "returns only the summary."
Claude Code's subagents documentation confirms the isolation: each subagent "runs in its own context window with a custom system prompt, specific tool access, and independent permissions," and "the subagent does that work in its own context and returns only the summary." It also names the boundary — subagents cannot spawn subagents, "to prevent infinite nesting" — so you cannot lean on them recursively.
The reason this is a starting decision and not an advanced one is the worked example Anthropic gives. In its illustrative walkthrough, "the subagent read 6,100 tokens of files" and "you got a 420-token result." Treat those exact numbers as representative rather than guaranteed — the source labels them so — but the ratio is the point: the expensive reading happens somewhere your main session never pays for. If your symptom is investigations ballooning the session — Anthropic's own failure pattern, "Claude reads hundreds of files, filling the context" — a subagent for exploration is your first move, before any CLAUDE.md tuning.
The decisive split:
- Start with a subagent when the work is read-heavy and separable — exploring an unfamiliar package, finding every caller of a function, investigating a bug across modules. The cost stays in the subagent's window.
- Stay on the main thread when the work needs one continuous architectural judgment, or the reading you do is what you will keep editing against. Isolating that just throws away the context you wanted.
What is agentic search, and when does it beat an index?
Agentic search is how Claude Code finds context: it explores on demand — traversing files, reading them, running grep, following references — rather than querying a pre-built vector index, and it beats an index whenever freshness and zero setup matter more than raw query volume. Anthropic describes the navigation directly: Claude Code "traverses the file system, reads files, uses grep to find exactly what it needs, and follows references across the codebase," the way an engineer would. The trade it makes explicit: "There's no embedding pipeline or centralized index to maintain."
That is the decision criterion. A retrieval-augmented (RAG) index has to be rebuilt as code changes, and a stale index, in Anthropic's framing, "reflects the codebase as it previously existed weeks, days, or even hours before." Agentic search reads the code as it is right now — no rebuild, no drift, nothing to maintain — so for most teams the starting answer is "use what's built in and add nothing."
The claim is contested, so know the counter before you commit. Zilliz/Milvus — a vector-database vendor that ships a claude-context index — argues that grep-only retrieval "just burns too many tokens" at high query volume and that semantic search is more efficient on large, stable codebases; that commercial interest is itself worth weighing. On the other side, a Claude engineer (quoted via SmartScope) reported the opposite from testing — "agentic search outperformed [it] by a lot, and this was surprising" — and independent write-ups confirm Claude Code dropped a local vector DB in favour of Glob/Grep/Read.
The decision rule:
- Start with agentic search (add no index) when the repo is actively edited and you value freshness and zero infra — most product teams. You avoid both index staleness and setup cost.
- Only consider a search sidecar when you have measured a token or latency wall on a high-volume, relatively stable codebase. That is the narrow case the vendor critique describes — not the default.
When should you /compact versus start fresh?
Use /compact when you want to keep going on the same task and need to reclaim room; start fresh with /clear when you are moving to an unrelated task — and know exactly what /compact keeps before you trust it. Anthropic's best-practices guidance is blunt that "the context window fills up fast, and performance degrades as it fills," and that you should "use /clear frequently between tasks to reset the context window entirely." /clear is the clean break between jobs; /compact is the mid-task squeeze.
The decision hinges on what actually survives a compaction. Claude Code's context-window documentation specifies it, and these are stated as hard caps, not illustrative figures:
| What you have in context | Survives /compact? |
|---|---|
| System prompt and output style | Unchanged — not part of message history |
Project-root CLAUDE.md and unscoped rules | Re-injected from disk |
| Auto memory | Re-injected from disk |
Path-scoped rules (paths: frontmatter) and nested CLAUDE.md | Lost until a matching file is read again |
| Invoked skill bodies | Re-injected, but capped at 5,000 tokens per skill and 25,000 tokens total — oldest dropped first |
The trap is in row four. If your session's working knowledge came from a nested CLAUDE.md or a path-scoped rule, /compact silently drops it until you re-open a file in that directory. So the decision rule is: /compact to continue the same task — but if it depends on a deep directory's scoped context, re-touch a file there afterward so the rules reload. /clear whenever you switch to something unrelated. The survival table is what turns /compact from a gamble into a tool.
What's the minimum you should configure on day one?
The minimum is a thin root CLAUDE.md plus whichever single branch above matches your loudest pain — nothing more. Anthropic's own caveat sets the boundary: Claude Code is "designed around conventional software engineering environments where engineers are the primary codebase contributors, the repo uses Git, and code follows standard directory structures." Inside that envelope you do not need a large initial setup; you need the right first mechanic.
If you want an adoption path beyond day one, keep it tight: a 2-week build sprint to stand up the starting mechanic and the thin root map, then a 2-week test-and-iterate sprint where you watch real sessions and add the next mechanic only when a symptom demands it. Avoid multi-month "rollout pilot" framing — the decision here is small and fast, and over-planning it just delays the first real session. When you are ready to build the full hierarchy, scope skills, add hooks, and govern it across a team, that is what the implementation guide is for.
Authoritative sources & related reading
Primary and supporting sources
- Anthropic's Applied AI team, How Claude Code works in large codebases: Best practices and where to start (claude.com blog, published May 14, 2026) — the primary source for repo-shape framing, agentic search, the
CLAUDE.mdwalk-up algorithm, and the subagent split. (No individual byline; attributed to Anthropic's Applied AI team.) https://claude.com/blog/how-claude-code-works-in-large-codebases-best-practices-and-where-to-start - Claude Code documentation — How Claude remembers your project (memory /
CLAUDE.mdload order, ~200-line target, advisory-not-enforced). https://code.claude.com/docs/en/memory - Claude Code documentation — Explore the context window (the representative 200K-token figures, the 6,100→420 subagent example, the
/compactsurvival caps). https://code.claude.com/docs/en/context-window - Claude Code documentation — Create custom subagents (separate context window, returns only a summary, no nesting). https://code.claude.com/docs/en/sub-agents
- Claude Code documentation — Best practices for Claude Code (context as the primary constraint,
/clearbetween tasks, the infinite-exploration failure pattern). https://code.claude.com/docs/en/best-practices - Chroma, Context Rot — independent measurement that all 18 frontier models tested degrade as input length grows. https://www.understandingai.org/p/context-rot
- Liu et al., Lost in the Middle: How Language Models Use Long Contexts (Stanford et al., arXiv 2307.03172) — the U-shaped attention curve behind keeping context lean. https://arxiv.org/abs/2307.03172
- Zilliz/Milvus, Why I'm Against Claude Code's Grep-Only Retrieval — the vector-DB vendor counter-argument to agentic search (commercial interest noted). https://milvus.io/blog/why-im-against-claude-codes-grep-only-retrieval-it-just-burns-too-many-tokens.md
Related reading from AI Heroes
- Claude Code in Large Codebases: The 2026 Implementation Guide — once you know where to start, this is how to build the full CLAUDE.md hierarchy, skills, hooks, subagent patterns, and team rollout.
- The AI Agent Harness Debt You're Quietly Taking On — why the harness around the model accrues maintenance cost, and how to keep it lean.
- AI Agent Workflow Automation — turning repeatable engineering tasks into governed agent workflows.
- Claude for Small Business: The 2026 Implementation Guide — the same start-narrow discipline applied to a small team adopting Claude.
The agent built for this

Richard
A forward-deployed AI agent that gets your software live and adopted inside every customer.
Meet RichardFrequently Asked Questions

Founder, AI Heroes
I build AI companies and the systems inside them. At AI Heroes, we give businesses the functional capacity to grow without the headcount growth normally demands — sales that follows up, marketing that runs, content that ships, ops that handles itself. We audit where you're leaving growth on the table, build the team that captures it, and hand it over completely.
I've built at scale before. Leading product and GTM at SlideSpeak AI (1M+ monthly users, profitable, bootstrapped). CPO at Disperse — the AI construction platform that went from 3 to 200+ people on $35M raised. I also co-founded LOBOMAR, a luxury fashion label featured in Elle, Cosmopolitan, and the LA Times, with shows at the London Design Museum, Wereldmuseum, and Amsterdam Fashion Week.
Related Articles
Claude Code in Large Codebases: The 2026 Implementation Guide
Claude Code does not win large codebases by swallowing the repo. It wins when you build a navigation and governance layer around it.

Claude Code + HTML: The 2026 Implementation Guide to the Right Output Medium
Anthropic's own engineers have moved Claude Code outputs to HTML for almost everything. The implementation question is when HTML wins, when it doesn't, and how the handoff from Claude Design to Claude Code should actually look.
How to Run an AI-Native Engineering Org in 2026
Agentic coding doesn't remove the engineering bottleneck — it moves it from writing code to verifying it. Here's the 2026 operating model for an AI-native engineering org: the processes to rewrite, how code review changes, and the metrics that prove it's working.