AI Engineering
8 articles
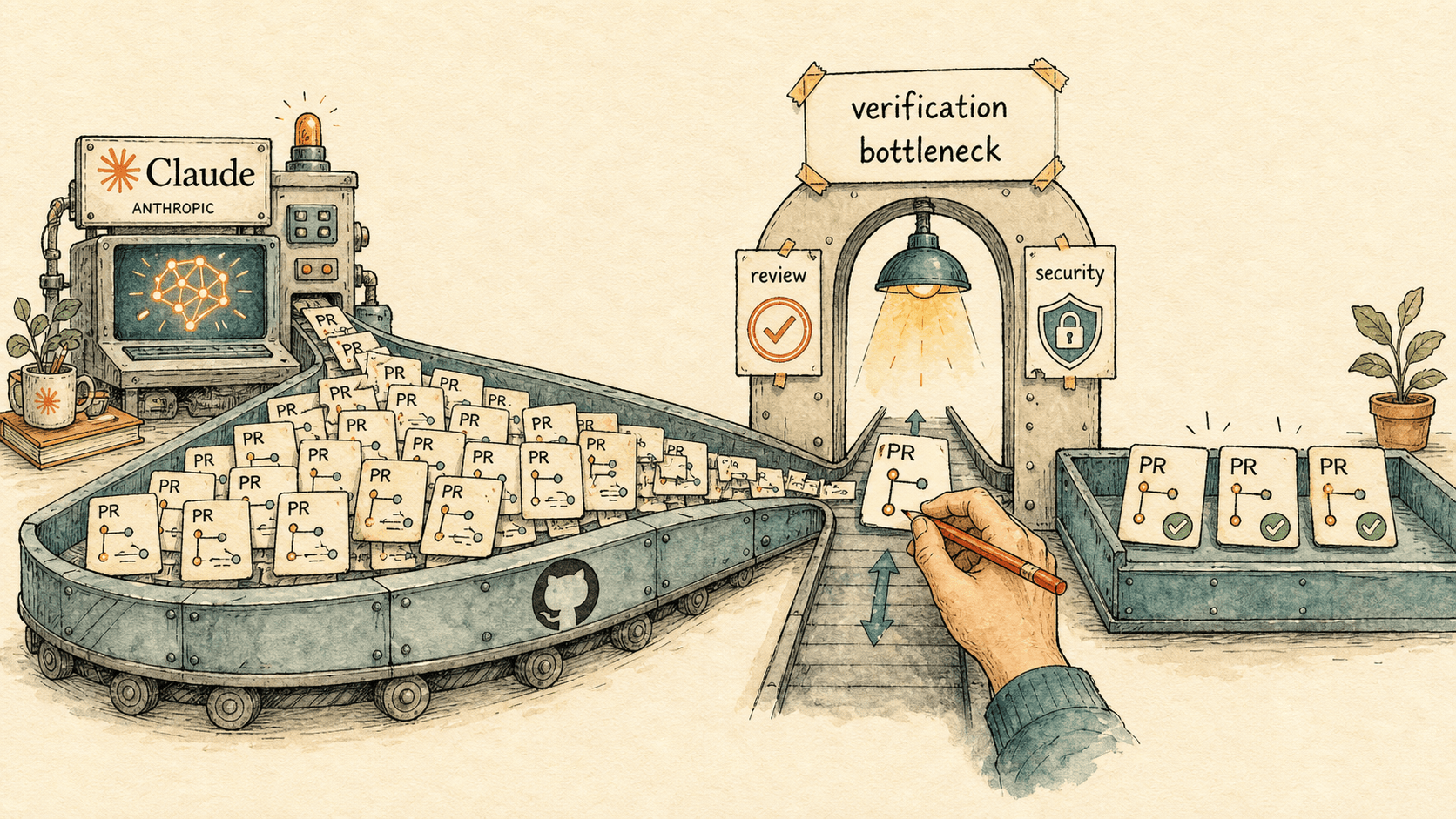
How to Run an AI-Native Engineering Org in 2026
Agentic coding doesn't remove the engineering bottleneck — it moves it from writing code to verifying it. Here's the 2026 operating model for an AI-native engineering org: the processes to rewrite, how code review changes, and the metrics that prove it's working.
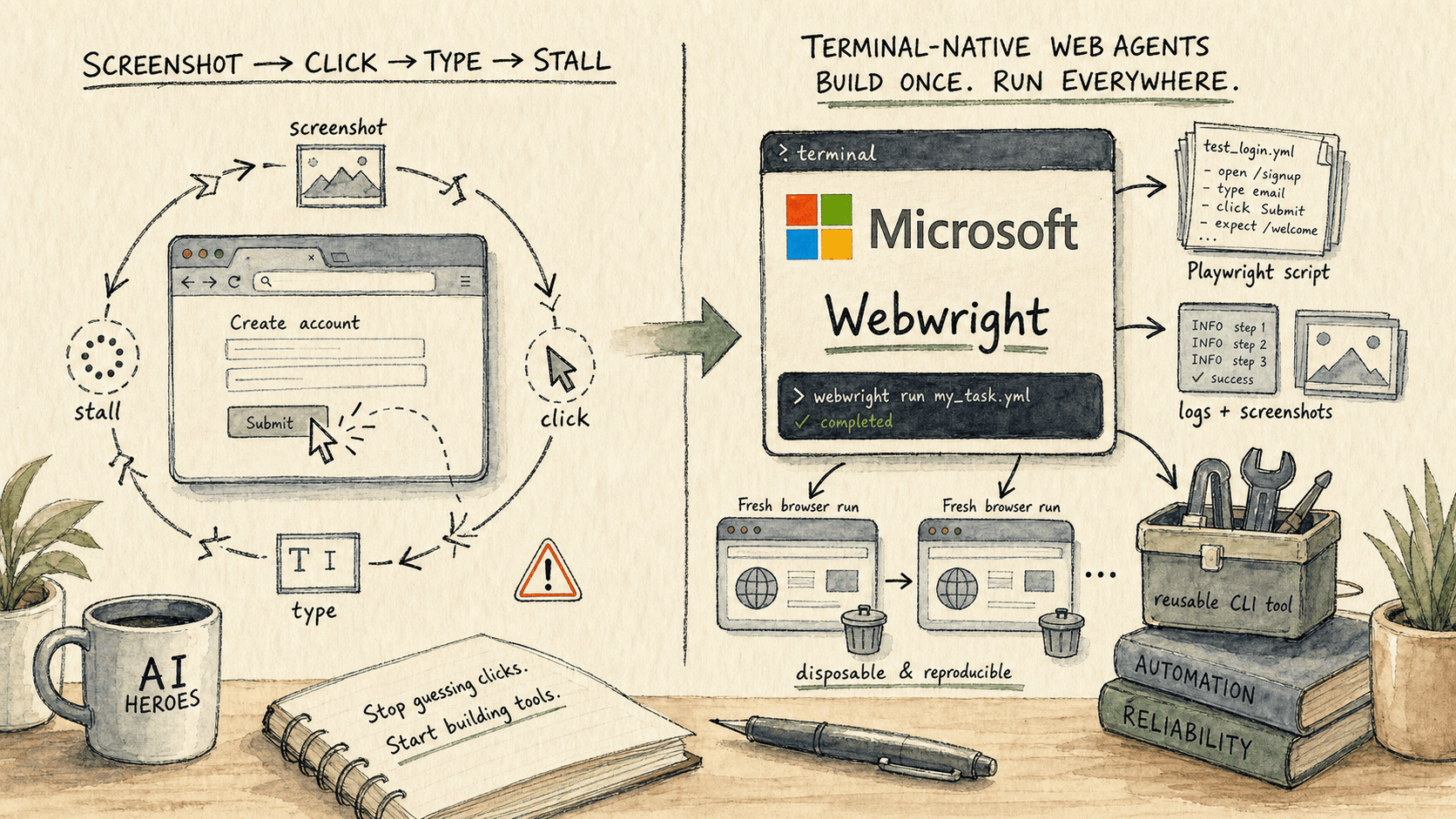
What Are Terminal-Native Web Agents? Microsoft Webwright and the End of Click-by-Click Computer Use (2026)
The next reliable web agent will not just click better. Microsoft Webwright points at the real shift: terminal-native agents that turn repeated browser work into Playwright code, logs, screenshots, fresh reruns, and reusable tools.
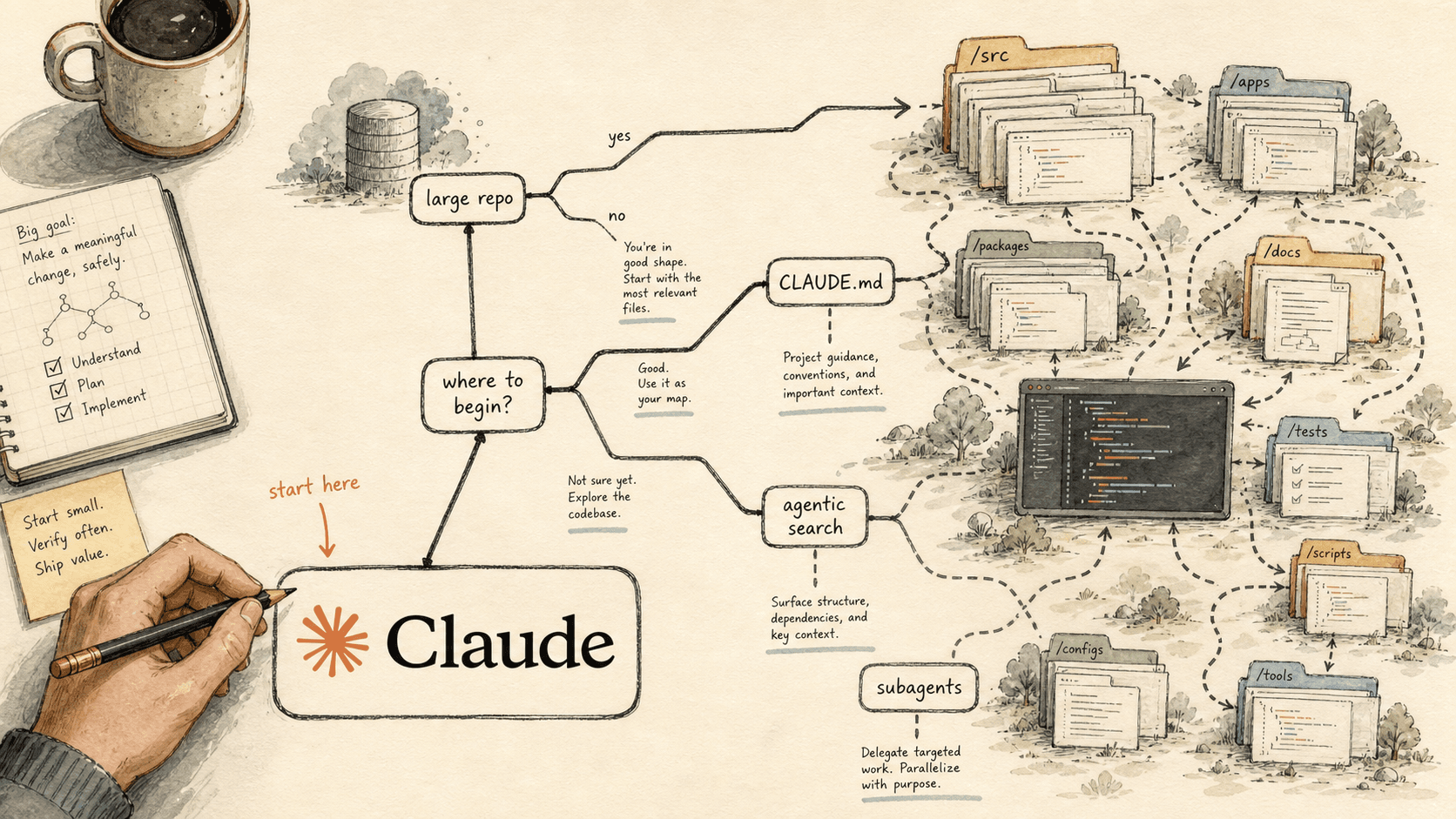
Where to Start With Claude Code in a Large Repo: A Decision Tree (2026)
You do not start a large Claude Code rollout by configuring everything. You start with the one mechanic your repo shape and your actual pain point demand — and ignore the rest until you hit them. This is the decision layer that runs before the build.

Harness Debt: Your AI Agent Scaffolding Is Quietly Fighting the Model (2026)
Your AI agent is probably worse than the model inside it — and the gap is your own scaffolding. An experimental harness scored over 2x Anthropic's standard one on the same model. The fix isn't a bigger framework; it's deleting the assumptions that went stale the day Claude Opus 4.6 shipped.
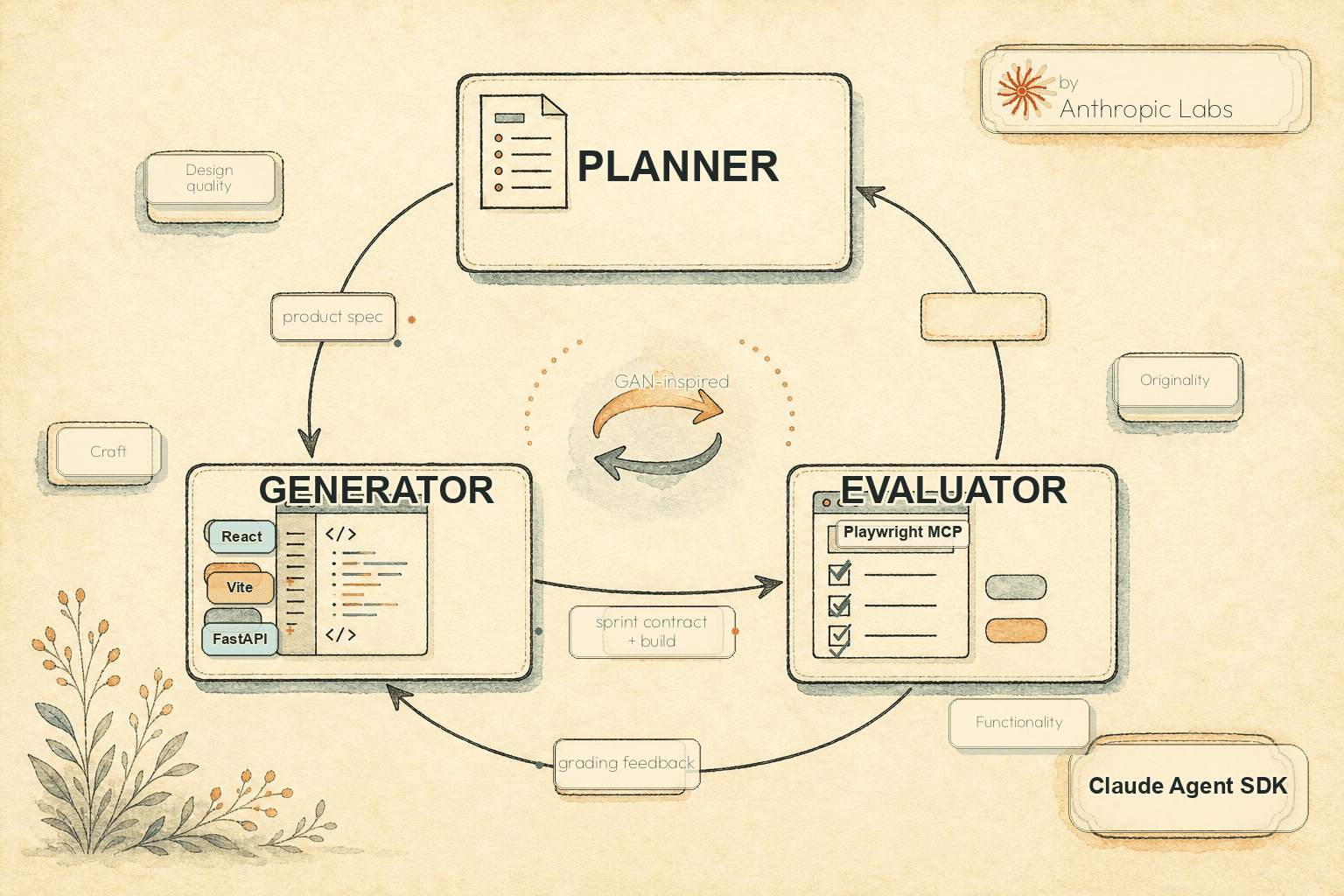
Harness Design for Long-Running AI Applications: Inside Anthropic's Generator-Evaluator Pattern (Claude Agent SDK, 2026)
On 24 March 2026 Anthropic Labs engineer Prithvi Rajasekaran published the most rigorous public account to date of how Anthropic designs harnesses for long-running AI applications — a GAN-inspired generator-evaluator pattern applied across two unusually different domains: frontend design (subjective, no binary verification) and full-stack coding (objective, machine-verifiable). The piece evolves the November 2025 Initializer + Coding Agent baseline into a three-agent planner + generator + evaluator architecture, with concrete cost-and-duration data ($200 / 6h on a retro game maker test, then $124 / 4h on a more ambitious DAW after the Opus 4.6 simplification pass). Inside the pattern, the two failure modes it fixes (context anxiety + self-evaluation bias), how it compares to LangGraph / AutoGen / OpenAI Assistants v2 / Devin, when it doesn't fit, and the canonical principle every team operating a harness should adopt: stress-test every component against the current model.

Claude Code + HTML: The 2026 Implementation Guide to the Right Output Medium
Anthropic's own engineers have moved Claude Code outputs to HTML for almost everything. The implementation question is when HTML wins, when it doesn't, and how the handoff from Claude Design to Claude Code should actually look.
Claude Code in Large Codebases: The 2026 Implementation Guide
Claude Code does not win large codebases by swallowing the repo. It wins when you build a navigation and governance layer around it.

We benchmarked Garry Tan's gbrain against our own agent memory on 150 real questions (May 2026)
A 352-file, 150-question apples-to-apples retrieval benchmark between gbrain and our existing OpenClaw qmd setup. gbrain wins 8.3x more often on hard, cross-source, and discrimination questions — but the headline is messier than the marketing.
Stay updated
Get new articles on AI implementation for business delivered to your inbox. No spam, no fluff.