From Peec or Profound Data to AI Citations: A 5-Step Playbook (2026)
TL;DR
- Your Peec or Profound dashboard tells you where you're invisible in AI answers. Turning that into citations is a five-step job: read the gap reports (not the vanity score), turn cited sources into a target list, fix pages that are retrieved but not cited, build the off-site footprint the data points to, then re-measure on a cadence.
- The single highest-leverage move is the source/domain gap report — the third-party sites citing your competitors but not you. That's your roadmap.
- Most of the work lands off your own domain and has to recur. If you have the data but not the hands, that's the gap to close.
What your Peec or Profound dashboard is actually telling you
Both platforms give you the same core reports, under different names: a visibility / share-of-voice score (how often you appear), prompt-level gaps (the buyer questions where you're missing), competitor comparison (who gets recommended instead), and — the one most teams underuse — a source / domain report showing which sites the engines pulled from to build the answer.
The mistake is staring at the top-line visibility number. That number is an outcome, not an instruction. The reports that tell you what to do are the gap reports. Here's how to work them in 2026.
Step 1 — Read the gap report, not the vanity metric
Filter to the prompts where a competitor is cited and you aren't. That intersection is your priority list — high-intent questions your category is asking AI, where someone else owns the answer. Rank them by buying intent (a "best X for Y" comparison prompt is worth more than a top-of-funnel definition) and by how close you already are (prompts where you're retrieved but not cited are the fastest wins — see Step 3).
Ignore, for now, prompts where nobody is cited consistently or where the intent is irrelevant to your buyer. Visibility for its own sake isn't the goal; visibility on the prompts that precede a purchase is.
Step 2 — Turn the cited sources into a target list
Open the source/domain report and look at which domains the engine cited to answer your priority prompts. This is the most actionable thing in the whole dashboard, because brands are cited several times more often through third-party sources than through their own site. The domains in that report are the ones the engine already trusts for your category.
Sort them into four buckets and act on each:
| Source type | Examples | Your move |
|---|---|---|
| Reviews | G2, Capterra, TrustRadius | Claim and optimise your profile; earn recent reviews; the engines reach for these on commercial prompts |
| Community / UGC | Reddit, Quora | Show up authentically with expert answers where your category is discussed (engines lean on these heavily — Reddit alone is ~40% of AI citations) |
| Editorial / roundups | "Best X" lists, trade publications | Pitch to be included; these comparison roundups are cited disproportionately |
| Reference | Wikipedia, Wikidata | Build entity consistency; a clean Wikidata item helps Gemini and AI Overviews |
Step 3 — Fix the pages that are retrieved but not cited
Some of your pages are already being retrieved by the engines — they're in the candidate set — but not cited. That's an extraction problem, not an authority problem, and it's the cheapest fix on the board. The engine couldn't confidently pull a clean, attributable answer from the page.
The fix is content shape — the same answer-first structure that wins AEO and GEO citations: lead each section with a direct one-sentence answer, then explain; add comparison tables and FAQs; keep paragraphs tight and atomic; make sure the page renders in raw HTML, not just JavaScript, because most AI crawlers don't execute scripts. You're not writing more — you're making the existing answer extractable.
Step 4 — Build the off-site footprint the data pointed to
Steps 1–2 told you which third-party surfaces decide your category's answers. This is where the actual citation gains come from, and it's the work a dashboard can't do for you: optimised review profiles, genuine community participation, and editorial placements on the domains the engine already trusts. Don't skip it because it's slower than publishing a blog post — it's the lever with the most weight.
Step 5 — Re-measure the delta on a cadence
AI answers move. Competitors publish, engines shift their source mix, and citations decay as content ages, so the same prompts need re-checking. Set a recurring cadence — re-run the gap reports, watch the share-of-voice delta on your priority prompts, and feed what moved (and what didn't) back into the next round. This is the loop that compounds; one-off campaigns flatten out.
| Dashboard report | The action it implies |
|---|---|
| Prompt gaps (competitor cited, you aren't) | Prioritised content + off-site roadmap |
| Source / domain report | Your third-party target list (reviews, UGC, editorial, reference) |
| Retrieved-but-not-cited pages | Answer-first rewrites (extraction fixes) |
| Share-of-voice trend | Cadence + what to double down on |
A worked example: one prompt, four pieces of work
Say your dashboard shows you're absent from the prompt "best [your category] tool for [use case]" in ChatGPT, while a competitor is named. Open the answer for that prompt and read what the engine actually cited: typically a third-party "best X 2026" listicle at the top spot and a Reddit thread — and not your own site. That single prompt now generates a prioritised work queue:
- Editorial: pitch to be included in that "best X" listicle (the engine already trusts it).
- UGC: add a genuine, expert answer to the Reddit thread where your category is being discussed.
- Owned: publish or rebuild your own comparison page answer-first, so you're at least retrieval-eligible next time.
- Re-check: re-run the prompt in ~three weeks to see whether the answer moved.
One prompt, four concrete actions — none of which the dashboard does for you. Multiply that across your priority prompts and you have the whole programme.
Where this gets heavy
None of these steps is secret. The catch is that doing them — across dozens of priority prompts, on and off your domain, every month — is a standing workload most teams can't staff on top of the day job. That's the gap between having a dashboard and moving its numbers.
It's also exactly what AI Heroes runs with Schmitdy, our AI-search agent: he reads your Peec or Profound data, turns the gap reports into a prioritised plan, and ships the rewrites, new pages, community engagement and outreach — human-reviewed, in Slack/Teams. The dashboard tells you the score; Schmitdy works the list.
The bottom line
A visibility dashboard is a map, not a journey. The value is in working the gap reports — especially the source/domain report — into shipped, citable work on the third-party surfaces the engines already trust, then re-measuring and going again. Start with the source gap. Then move the answer.
The agent built for this

Schmitdy
Turns ChatGPT, Claude, Gemini, and Perplexity into your next growth channel.
Meet SchmitdyFrequently Asked Questions

Founder, AI Heroes
I build AI companies and the systems inside them. At AI Heroes, we give businesses the functional capacity to grow without the headcount growth normally demands — sales that follows up, marketing that runs, content that ships, ops that handles itself. We audit where you're leaving growth on the table, build the team that captures it, and hand it over completely.
I've built at scale before. Leading product and GTM at SlideSpeak AI (1M+ monthly users, profitable, bootstrapped). CPO at Disperse — the AI construction platform that went from 3 to 200+ people on $35M raised. I also co-founded LOBOMAR, a luxury fashion label featured in Elle, Cosmopolitan, and the LA Times, with shows at the London Design Museum, Wereldmuseum, and Amsterdam Fashion Week.
Related Articles

AI Search Tool vs Agency vs Agent: Which Do You Actually Need in 2026?
There are three ways to improve your AI search visibility, and they're layers of the same stack, not rivals: a tool (Peec, Profound) measures where you stand; an agency executes the optimisation work with people; an agent — an AI-search agent — does the recurring volume under human review. A tool changes your understanding, not the answer. An agency changes the answer but costs the most and moves at human speed. An agent does the volume at mid-market cost with humans owning quality and strategy. In 2026 most teams keep a tool and add one execution layer — the real decision is which one.
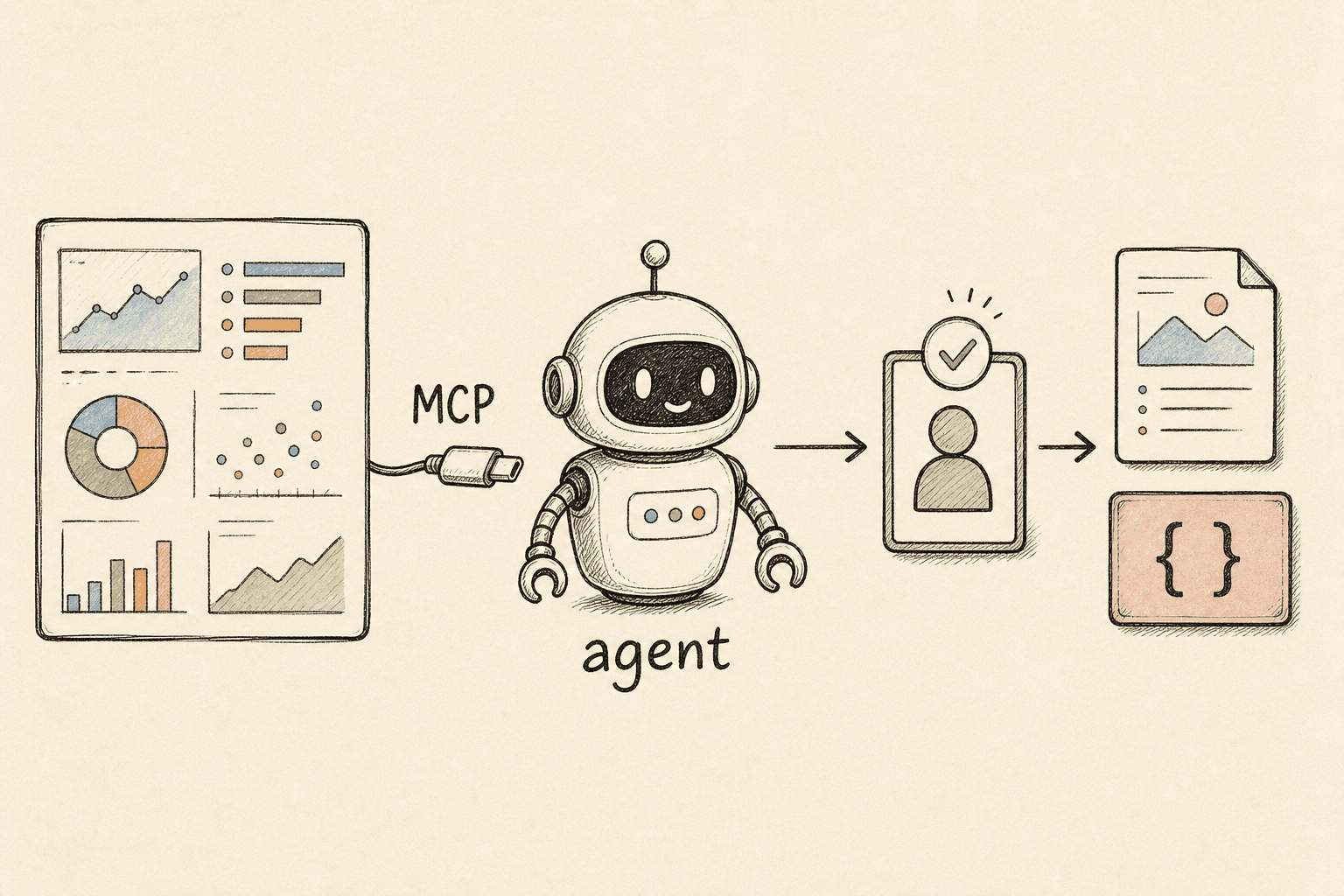
How to Build AI Agents on the Peec AI MCP for AEO and GEO (2026)
In late 2025 Peec AI shipped an official MCP server, which makes its entire AI-search measurement layer — projects, prompts, per-engine brand visibility, full AI answer transcripts, the source/citation graph and scored Actions — directly callable by an LLM agent. That means you can wire a Claude or GPT agent straight to the ground truth of how ChatGPT, Perplexity, Gemini and AI Overviews answer your category, and have it reason over the data and draft the work to close the gaps. The defensible build pattern is a read-only, five-stage loop with a human ship gate: the agent triages and drafts; a person verifies and ships.
The Best AI Search Agencies in 2026 (GEO and AEO), Compared
The agencies that get brands cited inside ChatGPT, Gemini, Perplexity, and Google AI Overviews, compared on model, market, and method, with the criteria to pick one. The most useful fact for choosing: around 85 percent of AI citations come from third party domains, not your own site, so an agency whose whole offer is on-site content is mismatched to where citations come from.