How to Build AI Agents on the Peec AI MCP for AEO and GEO (2026)
TL;DR
- In late 2025 Peec AI shipped an official MCP server, which makes its entire AI-search measurement layer — projects, prompts, brand visibility per engine, full AI answer transcripts, the source/citation graph, and scored Actions — directly callable by an LLM agent.
- That means you can wire a Claude or GPT agent straight to the ground truth of how ChatGPT, Perplexity, Gemini and AI Overviews actually answer your category — and have it reason over the data, then draft the work to close the gaps.
- The build pattern is a five-stage read-only loop: baseline → find the gap → read the answers → pull the recommendations → draft the work package, with a human ship gate before anything publishes.
- The honest part: the agent triages and drafts; a human verifies and ships. Dashboards measure; the agent + human move the number.
Written by AI Heroes — we build production agents on the Peec MCP. Last updated June 2026.
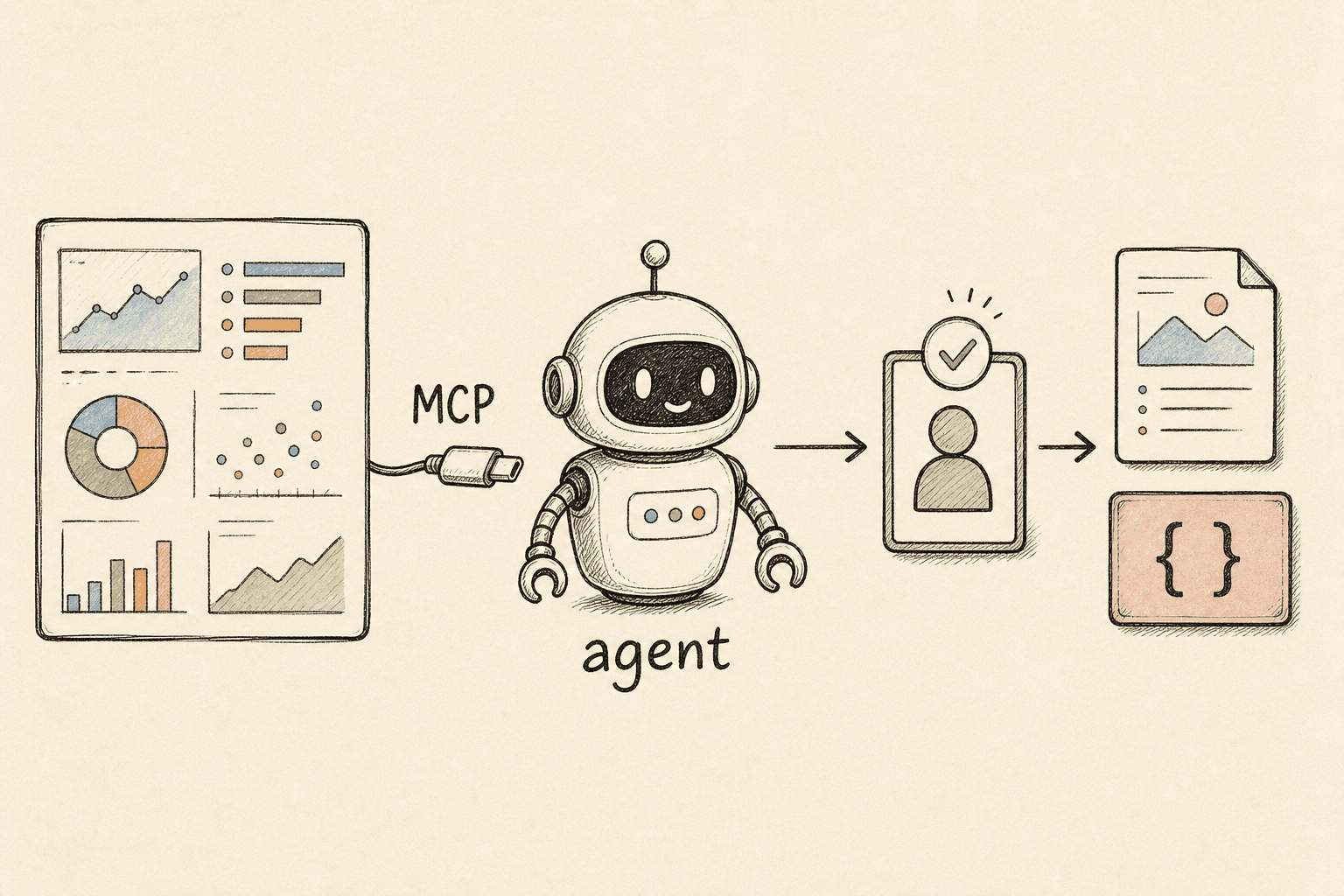
What is the Peec AI MCP, and why does it matter for GEO/AEO?
The Model Context Protocol (MCP) is an open standard for connecting AI applications to external tools and data — "a USB-C port for AI applications." Peec AI — an AI-search analytics platform that tracks how brands appear across ChatGPT, Perplexity, Gemini, Google AI Overviews and more — now ships an official MCP server. Connect it to an MCP-capable host (Claude, Cursor, your own agent) and the model can call Peec's data directly.
Why that matters: every GEO/AEO tool today is a dashboard. It measures how you show up in AI answers. But measurement isn't the work — the value is the loop from tool data → agent reasoning → shipped work (content, schema, off-site placements). Peec's own Actions feature stops at "here's the prioritised gap and an example to imitate"; you still have to create the content. The MCP is what lets an agent pick up exactly at that handoff.
What data does the Peec AI MCP actually expose?
Far more than "visibility went up or down." The server exposes a queryable data model: projects (a tracked brand + its competitors + a prompt library), prompts (questions tracked daily across engines), brands (yours + competitors), chats (one engine's verbatim answer to one prompt on one date — the atomic unit of AI-search reality), and the source/citation graph (which URLs an engine retrieved versus cited inline — these are independent, and the distinction is the whole game).
The metric semantics — get these right (most teams don't):
| Metric | Scale | Meaning |
|---|---|---|
visibility | 0–1 ratio (×100 to display) | share of AI responses that mention the brand |
share_of_voice | 0–1 ratio | brand's slice of all mentions across tracked brands |
retrieved_percentage | 0–1 ratio | share of chats that pulled ≥1 URL from a domain |
sentiment | 0–100 | how positively engines describe you (most brands 65–85; <50 = problem). Never ×100 |
position | rank (avg) | average rank when you appear; lower is better |
retrieval_rate / citation_rate | average, can exceed 1.0 | URLs pulled / inline citations per chat. Not percentages — never ×100 |
The #1 GEO-tool literacy mistake is treating
retrieval_rateandcitation_rateas percentages. They're averages and can be greater than 1.0. Onlyvisibility,share_of_voiceandretrieved_percentageare the 0–1 ratios you multiply by 100.
The key read tools:
| Tool | What it returns |
|---|---|
list_projects / list_prompts / list_brands / list_model_channels | lookup tables (resolve IDs → names first) |
get_brand_report | the scoreboard — visibility, SoV, sentiment, position; break it down by engine and by topic |
get_domain_report | the source graph at domain level + the gap filter (domains citing competitors but not you) |
get_url_report | the source graph at page level — which exact pages/formats get cited (also supports gap) |
list_chats / get_chat | the verbatim AI answers: what was said, which sources were retrieved vs cited, at what position |
get_url_content | Peec's scraped markdown of a source URL — read why a winning page wins |
get_actions | the recommendation engine: opportunity-scored gaps grouped into Owned / Editorial / Reference / UGC |
get_agent_visits / list_bots | server-log analytics — are AI crawlers actually fetching your new pages? |
There are also write tools (create_prompt, update_brand, etc.) that configure a project. An analysis agent should be read-only by default — writes mutate a live tracking project and belong behind explicit human approval.
How does MCP connect an agent to Peec?
MCP has three roles: a host (the AI app), a client (one per server, spun up by the host), and the server (Peec). Local servers talk over stdio; remote servers like Peec use Streamable HTTP. The data layer is JSON-RPC 2.0: the client runs an initialize handshake, calls tools/list to discover each tool's schema, and issues tools/call with {name, arguments} when the model picks one — feeding the result back into the conversation.
Auth is the part to get right. The MCP spec mandates OAuth 2.1 for protected servers, with PKCE always required, Protected Resource Metadata (RFC 9728) for discovery, and audience validation (RFC 8707) so a token for one server can't be replayed at another. In practice you add the Peec connector in your MCP host, complete an OAuth flow once, and the agent calls tools without ever seeing your Peec password.
This is low-effort now because MCP became infrastructure: in December 2025 Anthropic moved MCP to the Agentic AI Foundation, a Linux Foundation fund — co-founded with Block and OpenAI, and supported by Google, Microsoft and AWS. Wiring an agent to Peec is a configuration step, not an integration project.
How do you build a GEO agent on the Peec MCP?
The defensible design is a read-only analysis-and-drafting agent plus a human ship gate. The agent never publishes; it produces a ranked, evidence-backed work queue and first-draft assets. A person verifies and ships.
┌──────────────────────────────────────────────┐
│ PEEC AI MCP (read-only) │
│ get_brand_report · get_domain_report · │
│ get_url_report · get_chat · get_url_content · │
│ get_actions · get_agent_visits │
└───────────────▲───────────────┬──────────────┘
│ tool calls │ JSON
┌───────────────┴───────────────▼──────────────┐
│ GEO AGENT (LLM + MCP client) │
│ 1 BASELINE → 2 GAP → 3 READ → │
│ 4 RECOMMEND → 5 DRAFT WORK PACKAGE │
└───────────────┬───────────────────────────────┘
│ ranked queue + drafted assets
▼
┌───────────────────┐ ┌────────────────────┐
│ HUMAN SHIP GATE │ ───▶│ EXECUTION SURFACES │
│ verify·edit·sign │ │ content · JSON-LD · │
└─────────┬─────────┘ │ Reddit/PR/off-site │
│ └─────────┬──────────┘
│ after publish │
└──── re-baseline ◀───────┘
(get_agent_visits + next brand_report = did it move?)
Stage 1 — Baseline. get_brand_report broken down by model_channel_id (per engine) and again by topic_id (per cluster). Output: your visibility/SoV/position per engine, the competitor leaderboard, and where you sit at 0%.
Stage 2 — Find the gap. The most important call in the whole loop:
get_domain_report(
project_id, start_date, end_date,
filters=[{ field: "gap", operator: "gte", value: 1 }],
order_by="citation_count", limit=200
)
This returns the domains citing your competitors but not you, tagged by classification (Competitor / Editorial / Reference / UGC / You) so you know the type of gap. Run the same gap filter on get_url_report to get the exact pages.
Stage 3 — Read the answers. For the weakest high-value prompts, list_chats → get_chat to read verbatim what each engine said, which sources it retrieved vs cited, and at what position. Then get_url_content on the top gap URLs to read why those pages win (structure, answer-first intros, tables, freshness). This turns "we're losing" into "here's the exact format and source we're losing to."
Stage 4 — Pull the recommendations. get_actions(scope="overview") for opportunity scores, then drill (scope="owned" + a url_classification, or scope="ugc" + a domain). Merge Peec's text actions with the agent's own gap analysis into one prioritised list.
Stage 5 — Draft the work package. Per action, the agent emits an answer-first content brief or draft (H2s = the actual tracked prompts), the JSON-LD schema to add, and an off-site target list with a tailored pitch/comment for each gap source.
What's the gap report, and why is it the most important call?
Because most of what decides AI citations happens off your own domain. AirOps' offsite-signals analysis found brands are roughly 6.5× more likely to be mentioned via third-party sources than via their own domain on top-of-funnel commercial queries, and Otterly's 2026 citations report — across 1M+ citations — found community platforms like Reddit and Quora alone capture more than half (52.5%) of AI citations, outweighing brand-owned domains. The gap report is the one call that hands you that off-domain map directly: the specific listicles, comparison aggregators, Reddit threads and reference pages the engines already trust for your category, ranked, with the ones citing competitors but not you flagged.
Gap-domain type (classification) | The action lane it implies |
|---|---|
| Competitor / Editorial (a "best X 2026" listicle) | Earn inclusion in the roundup; pitch the publication |
| UGC (Reddit, Quora, YouTube) | Show up authentically with expert answers in those threads |
| Reference (Wikipedia, Wikidata, arXiv) | Build entity authority and citable references |
| You (your own pages, retrieved but not cited) | Re-engineer for extraction — answer-first, tables, schema |
From data to shipped work — and where the human signs off
The agent's output is a work queue, not a published change. A person stays in the loop at four points, and that's a feature, not a limitation: approve before any write or publish; check brand voice and factual accuracy on every drafted asset (the anti-AI-slop gate); send off-site contributions by hand (a Reddit comment must be a genuine, disclosed, value-adding human post, never automated spam); and re-rank by business value, because an opportunity score isn't the same as strategic importance.
How do you know it worked?
Close the loop with data. After humans ship, get_agent_visits confirms the AI crawlers (GPTBot, OAI-SearchBot, PerplexityBot, ClaudeBot) are actually fetching the new pages, and the next cycle's get_brand_report shows whether visibility and share of voice moved on the targeted prompts. The agent reports deltas, not vanity output.
Peec MCP by hand vs with an agent vs done-for-you
This is the tool vs agency vs agent decision applied to one tool — do you read Peec yourself, point your own agent at it, or have it run for you?
| Dashboard by hand | DIY + your own agent | Done-for-you (AI Heroes) | |
|---|---|---|---|
| Reads the data | You, manually | Agent, automatically | Agent + analyst |
| Drafts the work | You | Agent, you review | Agent, expert review |
| Ships + off-site outreach | You | You | Us, human-sent |
| Best for | Small scope, spare capacity | Technical teams who'll maintain the agent | Teams who want the outcome without building/running it |
The bottom line
The Peec MCP turns AI-search measurement into something an agent can act on — baseline the category, find the off-domain gaps, read the actual answers, and draft the work to close them, with a human shipping the result. The data is finally agent-callable; the execution is still where the value is. Start with the source gap. Then move the answer.
If you'd rather not build and run the agent yourself, that's exactly what AI Heroes does — Schmitdy is our AI-search agent built on this pattern, with humans on quality and outreach.
The agent built for this

Schmitdy
Turns ChatGPT, Claude, Gemini, and Perplexity into your next growth channel.
Meet SchmitdyFrequently Asked Questions

Founder, AI Heroes
I build AI companies and the systems inside them. At AI Heroes, we give businesses the functional capacity to grow without the headcount growth normally demands — sales that follows up, marketing that runs, content that ships, ops that handles itself. We audit where you're leaving growth on the table, build the team that captures it, and hand it over completely.
I've built at scale before. Leading product and GTM at SlideSpeak AI (1M+ monthly users, profitable, bootstrapped). CPO at Disperse — the AI construction platform that went from 3 to 200+ people on $35M raised. I also co-founded LOBOMAR, a luxury fashion label featured in Elle, Cosmopolitan, and the LA Times, with shows at the London Design Museum, Wereldmuseum, and Amsterdam Fashion Week.
Related Articles

AI Search Tool vs Agency vs Agent: Which Do You Actually Need in 2026?
There are three ways to improve your AI search visibility, and they're layers of the same stack, not rivals: a tool (Peec, Profound) measures where you stand; an agency executes the optimisation work with people; an agent — an AI-search agent — does the recurring volume under human review. A tool changes your understanding, not the answer. An agency changes the answer but costs the most and moves at human speed. An agent does the volume at mid-market cost with humans owning quality and strategy. In 2026 most teams keep a tool and add one execution layer — the real decision is which one.
From Peec or Profound Data to AI Citations: A 5-Step Playbook (2026)
Your Peec or Profound dashboard tells you where you're invisible in AI answers, but a visibility score is an outcome, not an instruction. Turning the data into citations is a five-step job: read the gap reports rather than the vanity metric, turn the cited sources into a third-party target list, fix the pages that are retrieved but not cited, build the off-site footprint the data points to, then re-measure the delta on a cadence. The highest-leverage move is the source/domain gap report — the third-party sites citing your competitors but not you. Most of the work lands off your own domain and has to recur, which is the gap between owning a dashboard and moving its numbers.
The Best AI Search Agencies in 2026 (GEO and AEO), Compared
The agencies that get brands cited inside ChatGPT, Gemini, Perplexity, and Google AI Overviews, compared on model, market, and method, with the criteria to pick one. The most useful fact for choosing: around 85 percent of AI citations come from third party domains, not your own site, so an agency whose whole offer is on-site content is mismatched to where citations come from.