MCP
4 articles
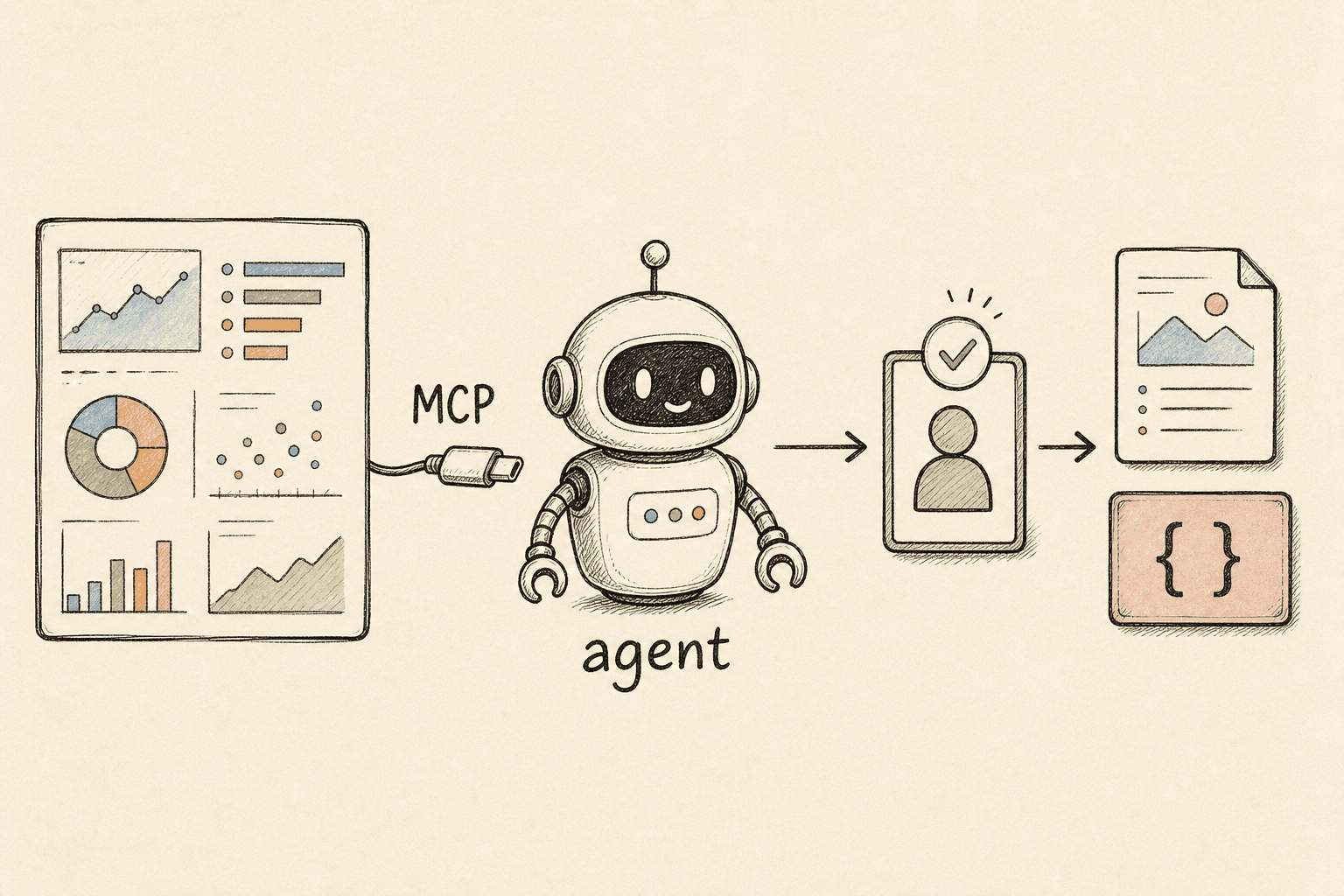
How to Build AI Agents on the Peec AI MCP for AEO and GEO (2026)
In late 2025 Peec AI shipped an official MCP server, which makes its entire AI-search measurement layer — projects, prompts, per-engine brand visibility, full AI answer transcripts, the source/citation graph and scored Actions — directly callable by an LLM agent. That means you can wire a Claude or GPT agent straight to the ground truth of how ChatGPT, Perplexity, Gemini and AI Overviews answer your category, and have it reason over the data and draft the work to close the gaps. The defensible build pattern is a read-only, five-stage loop with a human ship gate: the agent triages and drafts; a person verifies and ships.

How Claude Managed Agents Actually Work: Dreaming, Outcomes, Multiagent Orchestration, and Webhooks (2026)
Anthropic gave Claude Managed Agents four new mechanics at Code w/ Claude: Dreaming, Outcomes, Multiagent Orchestration, and Webhooks. The one that changes how you build is Outcomes — a separate grader that loops the agent until a rubric is met. Here is how each one works, and when to reach for it.
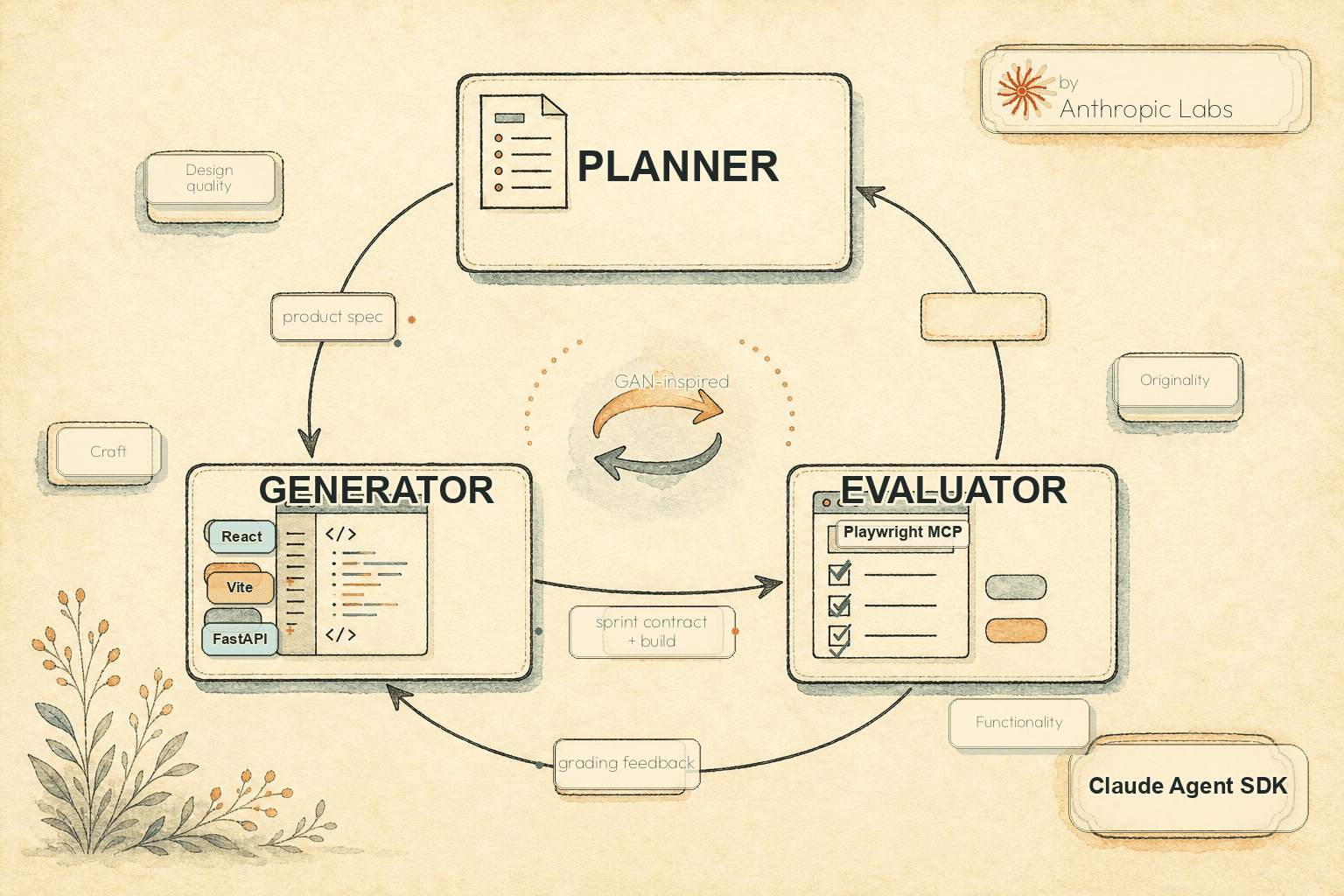
Harness Design for Long-Running AI Applications: Inside Anthropic's Generator-Evaluator Pattern (Claude Agent SDK, 2026)
On 24 March 2026 Anthropic Labs engineer Prithvi Rajasekaran published the most rigorous public account to date of how Anthropic designs harnesses for long-running AI applications — a GAN-inspired generator-evaluator pattern applied across two unusually different domains: frontend design (subjective, no binary verification) and full-stack coding (objective, machine-verifiable). The piece evolves the November 2025 Initializer + Coding Agent baseline into a three-agent planner + generator + evaluator architecture, with concrete cost-and-duration data ($200 / 6h on a retro game maker test, then $124 / 4h on a more ambitious DAW after the Opus 4.6 simplification pass). Inside the pattern, the two failure modes it fixes (context anxiety + self-evaluation bias), how it compares to LangGraph / AutoGen / OpenAI Assistants v2 / Devin, when it doesn't fit, and the canonical principle every team operating a harness should adopt: stress-test every component against the current model.
Building AI Agents in the Enterprise: Implementation Patterns for 2026
Anthropic's playbook is right about the enterprise shape. The missing layer is implementation: governed skills, MCP tools, memory, observability, worktree-safe orchestration, and agent fleets that survive contact with a 1,000-person company.