KI-Agenten auf dem Peec AI MCP für AEO und GEO bauen (2026)
TL;DR
- Ende 2025 hat Peec AI einen offiziellen MCP-Server veröffentlicht — damit ist die gesamte Mess-Ebene für KI-Suche (Projekte, Prompts, Markensichtbarkeit pro Engine, vollständige KI-Antwort-Transkripte, der Quellen-/Zitationsgraph und die bewerteten Actions) direkt von einem LLM-Agenten aufrufbar.
- Das heißt: Sie können einen Claude- oder GPT-Agenten direkt an die Grundwahrheit anschließen, wie ChatGPT, Perplexity, Gemini und AI Overviews Ihre Kategorie tatsächlich beantworten — und ihn über die Daten schließen lassen, um dann die Arbeit zum Schließen der Lücken zu entwerfen.
- Das Build-Muster ist ein fünfstufiger Read-only-Loop: Baseline → Lücke finden → Antworten lesen → Empfehlungen ziehen → Arbeitspaket entwerfen, mit einem menschlichen Ship-Gate, bevor irgendetwas veröffentlicht wird.
- Der ehrliche Teil: Der Agent triagiert und entwirft; ein Mensch prüft und veröffentlicht. Dashboards messen; der Agent + Mensch bewegen die Zahl.
Geschrieben von AI Heroes — wir bauen produktive Agenten auf dem Peec MCP. Zuletzt aktualisiert: Juni 2026.
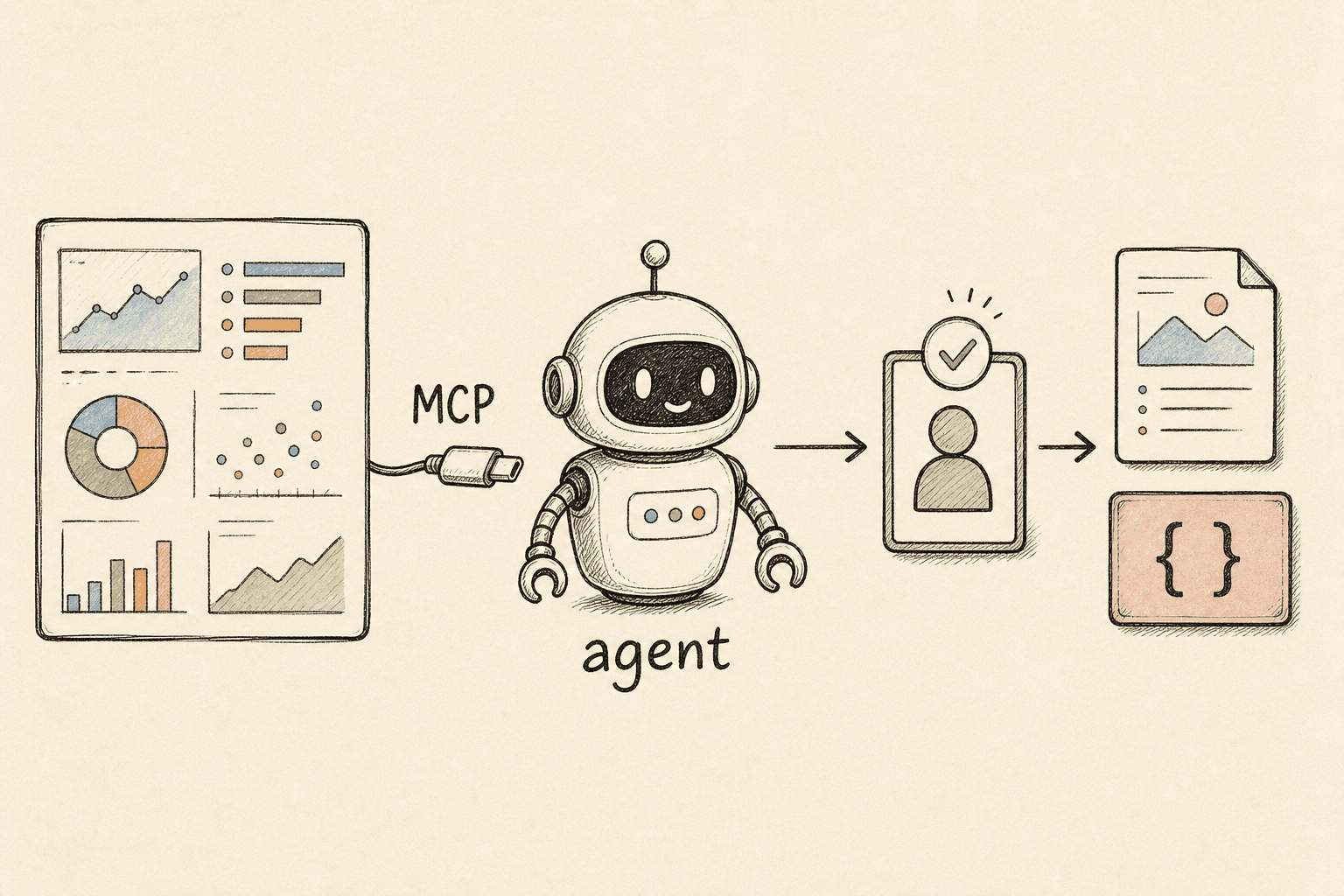
Was ist der Peec AI MCP, und warum ist er für GEO/AEO wichtig?
Das Model Context Protocol (MCP) ist ein offener Standard, um KI-Anwendungen mit externen Tools und Daten zu verbinden — „ein USB-C-Anschluss für KI-Anwendungen". Peec AI — eine KI-Such-Analyseplattform, die verfolgt, wie Marken in ChatGPT, Perplexity, Gemini, Google AI Overviews und mehr auftauchen — bietet jetzt einen offiziellen MCP-Server. Verbinden Sie ihn mit einem MCP-fähigen Host (Claude, Cursor, Ihr eigener Agent), und das Modell kann Peecs Daten direkt aufrufen.
Warum das zählt: Jedes GEO/AEO-Tool ist heute ein Dashboard. Es misst, wie Sie in KI-Antworten erscheinen. Aber Messung ist nicht die Arbeit — der Wert liegt im Loop von Tool-Daten → Agenten-Reasoning → ausgelieferter Arbeit (Content, Schema, Off-Site-Platzierungen). Peecs eigene Actions-Funktion endet bei „hier ist die priorisierte Lücke und ein Beispiel zum Nachahmen"; den Content müssen Sie noch erstellen. Der MCP ist das, was einen Agenten genau an diesem Übergabepunkt ansetzen lässt.
Welche Daten stellt der Peec AI MCP tatsächlich bereit?
Weit mehr als „Sichtbarkeit ist gestiegen oder gefallen". Der Server stellt ein abfragbares Datenmodell bereit: Projects (eine getrackte Marke + ihre Wettbewerber + eine Prompt-Bibliothek), Prompts (täglich über Engines getrackte Fragen), Brands (Ihre + Wettbewerber), Chats (die wortwörtliche Antwort einer Engine auf einen Prompt an einem Datum — die atomare Einheit der KI-Such-Realität) und den Quellen-/Zitationsgraphen (welche URLs eine Engine abgerufen versus inline zitiert hat — diese sind unabhängig, und genau diese Unterscheidung ist das ganze Spiel).
Die Metrik-Semantik — bringen Sie diese in Ordnung (die meisten tun es nicht):
| Metrik | Skala | Bedeutung |
|---|---|---|
visibility | 0–1-Verhältnis (×100 zur Anzeige) | Anteil der KI-Antworten, die die Marke nennen |
share_of_voice | 0–1-Verhältnis | Anteil der Marke an allen Nennungen aller getrackten Marken |
retrieved_percentage | 0–1-Verhältnis | Anteil der Chats, die ≥1 URL von einer Domain gezogen haben |
sentiment | 0–100 | wie positiv Engines Sie beschreiben (die meisten Marken 65–85; <50 = Problem). Nie ×100 |
position | Rang (Ø) | durchschnittlicher Rang, wenn Sie erscheinen; niedriger ist besser |
retrieval_rate / citation_rate | Durchschnitt, kann 1,0 übersteigen | gezogene URLs / Inline-Zitationen pro Chat. Keine Prozentwerte — nie ×100 |
Der häufigste Fehler in der GEO-Tool-Lesekompetenz ist,
retrieval_rateundcitation_rateals Prozentwerte zu behandeln. Es sind Durchschnitte und können größer als 1,0 sein. Nurvisibility,share_of_voiceundretrieved_percentagesind die 0–1-Verhältnisse, die Sie mit 100 multiplizieren.
Die wichtigsten Read-Tools:
| Tool | Was es zurückgibt |
|---|---|
list_projects / list_prompts / list_brands / list_model_channels | Lookup-Tabellen (zuerst IDs → Namen auflösen) |
get_brand_report | das Scoreboard — visibility, SoV, sentiment, position; brechen Sie es nach Engine und nach Topic auf |
get_domain_report | der Quellengraph auf Domain-Ebene + der gap-Filter (Domains, die Wettbewerber zitieren, aber Sie nicht) |
get_url_report | der Quellengraph auf Seitenebene — welche genauen Seiten/Formate zitiert werden (unterstützt ebenfalls gap) |
list_chats / get_chat | die wortwörtlichen KI-Antworten: was gesagt wurde, welche Quellen abgerufen vs zitiert wurden, an welcher Position |
get_url_content | Peecs gescraptes Markdown einer Quell-URL — lesen Sie, warum eine gewinnende Seite gewinnt |
get_actions | die Empfehlungs-Engine: chancen-bewertete Lücken, gruppiert in Owned / Editorial / Reference / UGC |
get_agent_visits / list_bots | Server-Log-Analytics — rufen KI-Crawler Ihre neuen Seiten tatsächlich ab? |
Es gibt auch Write-Tools (create_prompt, update_brand usw.), die ein Projekt konfigurieren. Ein Analyse-Agent sollte standardmäßig read-only sein — Writes mutieren ein laufendes Tracking-Projekt und gehören hinter eine ausdrückliche menschliche Freigabe.
Wie verbindet MCP einen Agenten mit Peec?
MCP hat drei Rollen: einen Host (die KI-App), einen Client (einer pro Server, vom Host gestartet) und den Server (Peec). Lokale Server kommunizieren über stdio; Remote-Server wie Peec nutzen Streamable HTTP. Die Datenebene ist JSON-RPC 2.0: Der Client führt einen initialize-Handshake aus, ruft tools/list auf, um das Schema jedes Tools zu entdecken, und setzt tools/call mit {name, arguments} ab, wenn das Modell eines wählt — und speist das Ergebnis zurück in die Konversation.
Auth ist der Teil, den man richtig machen muss. Die MCP-Spezifikation schreibt OAuth 2.1 für geschützte Server vor, mit immer erforderlichem PKCE, Protected Resource Metadata (RFC 9728) für die Discovery und Audience-Validierung (RFC 8707), damit ein Token für einen Server nicht bei einem anderen wiederverwendet werden kann. In der Praxis fügen Sie den Peec-Connector in Ihrem MCP-Host hinzu, durchlaufen einmal einen OAuth-Flow, und der Agent ruft Tools auf, ohne je Ihr Peec-Passwort zu sehen.
Das ist heute aufwandsarm, weil MCP zur Infrastruktur wurde: Im Dezember 2025 hat Anthropic MCP an die Agentic AI Foundation übergeben, einen Fonds der Linux Foundation — mitgegründet mit Block und OpenAI und unterstützt von Google, Microsoft und AWS. Einen Agenten an Peec zu verdrahten ist ein Konfigurationsschritt, kein Integrationsprojekt.
Wie baut man einen GEO-Agenten auf dem Peec MCP?
Das vertretbare Design ist ein read-only Analyse- und Entwurfs-Agent plus ein menschliches Ship-Gate. Der Agent veröffentlicht nie; er produziert eine gerankte, evidenzgestützte Arbeitswarteschlange und Erst-Entwürfe. Ein Mensch prüft und veröffentlicht.
┌──────────────────────────────────────────────┐
│ PEEC AI MCP (read-only) │
│ get_brand_report · get_domain_report · │
│ get_url_report · get_chat · get_url_content · │
│ get_actions · get_agent_visits │
└───────────────▲───────────────┬──────────────┘
│ tool calls │ JSON
┌───────────────┴───────────────▼──────────────┐
│ GEO AGENT (LLM + MCP client) │
│ 1 BASELINE → 2 GAP → 3 READ → │
│ 4 RECOMMEND → 5 DRAFT WORK PACKAGE │
└───────────────┬───────────────────────────────┘
│ ranked queue + drafted assets
▼
┌───────────────────┐ ┌────────────────────┐
│ HUMAN SHIP GATE │ ───▶│ EXECUTION SURFACES │
│ verify·edit·sign │ │ content · JSON-LD · │
└─────────┬─────────┘ │ Reddit/PR/off-site │
│ └─────────┬──────────┘
│ after publish │
└──── re-baseline ◀───────┘
(get_agent_visits + next brand_report = did it move?)
Stufe 1 — Baseline. get_brand_report, aufgebrochen nach model_channel_id (pro Engine) und erneut nach topic_id (pro Cluster). Output: Ihre visibility/SoV/position pro Engine, das Wettbewerber-Leaderboard und wo Sie bei 0 % stehen.
Stufe 2 — Die Lücke finden. Der wichtigste Aufruf im ganzen Loop:
get_domain_report(
project_id, start_date, end_date,
filters=[{ field: "gap", operator: "gte", value: 1 }],
order_by="citation_count", limit=200
)
Das gibt die Domains zurück, die Ihre Wettbewerber zitieren, aber Sie nicht, getaggt nach classification (Competitor / Editorial / Reference / UGC / You), damit Sie den Typ der Lücke kennen. Führen Sie denselben gap-Filter auf get_url_report aus, um die genauen Seiten zu erhalten.
Stufe 3 — Die Antworten lesen. Für die schwächsten hochwertigen Prompts list_chats → get_chat, um wortwörtlich zu lesen, was jede Engine sagte, welche Quellen sie abrief vs zitierte und an welcher Position. Dann get_url_content auf die wichtigsten Gap-URLs, um zu lesen, warum diese Seiten gewinnen (Struktur, antwort-first-Intros, Tabellen, Aktualität). Das macht aus „wir verlieren" ein „hier ist genau das Format und die Quelle, gegen die wir verlieren".
Stufe 4 — Die Empfehlungen ziehen. get_actions(scope="overview") für die Chancen-Scores, dann drillen (scope="owned" + eine url_classification, oder scope="ugc" + eine domain). Führen Sie Peecs text-Actions mit der eigenen Gap-Analyse des Agenten in einer priorisierten Liste zusammen.
Stufe 5 — Das Arbeitspaket entwerfen. Pro Action liefert der Agent ein antwort-first-Content-Briefing oder einen Entwurf (H2s = die tatsächlich getrackten Prompts), das hinzuzufügende JSON-LD-Schema und eine Off-Site-Zielliste mit einem maßgeschneiderten Pitch/Kommentar für jede Gap-Quelle.
Was ist der Gap-Report, und warum ist er der wichtigste Aufruf?
Weil das meiste, was über KI-Zitationen entscheidet, außerhalb Ihrer eigenen Domain passiert. AirOps' Off-Site-Signal-Analyse fand, dass Marken bei kommerziellen Top-of-Funnel-Anfragen rund 6,5× häufiger über Drittquellen genannt werden als über ihre eigene Domain, und Otterlys Citations-Report 2026 — über 1 Mio.+ Zitationen — fand, dass Community-Plattformen wie Reddit und Quora allein mehr als die Hälfte (52,5 %) der KI-Zitationen auf sich vereinen, mehr als markeneigene Domains. Der gap-Report ist der eine Aufruf, der Ihnen diese Off-Domain-Landkarte direkt liefert: die konkreten Listicles, Vergleichs-Aggregatoren, Reddit-Threads und Referenzseiten, denen die Engines in Ihrer Kategorie bereits vertrauen, gerankt, mit den Quellen markiert, die Wettbewerber zitieren, Sie aber nicht.
Gap-Domain-Typ (classification) | Die implizierte Aktions-Spur |
|---|---|
| Competitor / Editorial (ein „Best X 2026"-Listicle) | Aufnahme in das Roundup verdienen; die Publikation pitchen |
| UGC (Reddit, Quora, YouTube) | Authentisch mit Experten-Antworten in diesen Threads auftauchen |
| Reference (Wikipedia, Wikidata, arXiv) | Entitäts-Autorität und zitierbare Referenzen aufbauen |
| You (Ihre eigenen Seiten, abgerufen, aber nicht zitiert) | Für Extraktion neu bauen — antwort-first, Tabellen, Schema |
Von Daten zu ausgelieferter Arbeit — und wo der Mensch unterschreibt
Der Output des Agenten ist eine Arbeitswarteschlange, keine veröffentlichte Änderung. Ein Mensch bleibt an vier Punkten im Loop, und das ist ein Feature, keine Einschränkung: vor jedem Write oder Publish freigeben; Markenstimme und faktische Richtigkeit prüfen bei jedem entworfenen Asset (das Anti-KI-Slop-Gate); Off-Site-Beiträge von Hand senden (ein Reddit-Kommentar muss ein echter, offengelegter, mehrwertstiftender menschlicher Beitrag sein, nie automatisierter Spam); und nach Geschäftswert neu ranken, denn ein Chancen-Score ist nicht dasselbe wie strategische Bedeutung.
Woran erkennen Sie, dass es funktioniert hat?
Schließen Sie den Loop mit Daten. Nachdem Menschen ausgeliefert haben, bestätigt get_agent_visits, dass die KI-Crawler (GPTBot, OAI-SearchBot, PerplexityBot, ClaudeBot) die neuen Seiten tatsächlich abrufen, und der get_brand_report des nächsten Zyklus zeigt, ob sich Sichtbarkeit und Share of Voice bei den anvisierten Prompts bewegt haben. Der Agent berichtet Deltas, keinen Vanity-Output.
Peec MCP von Hand vs. mit einem Agenten vs. Done-for-you
Das ist die Tool-vs.-Agentur-vs.-Agent-Entscheidung, angewandt auf ein Tool — lesen Sie Peec selbst, richten Sie Ihren eigenen Agenten darauf, oder lassen Sie es für sich laufen?
| Dashboard von Hand | DIY + eigener Agent | Done-for-you (AI Heroes) | |
|---|---|---|---|
| Liest die Daten | Sie, manuell | Agent, automatisch | Agent + Analyst |
| Entwirft die Arbeit | Sie | Agent, Sie prüfen | Agent, Experten-Review |
| Liefert + Off-Site-Outreach | Sie | Sie | Wir, menschlich gesendet |
| Am besten für | Kleiner Umfang, freie Kapazität | Technische Teams, die den Agenten pflegen | Teams, die das Ergebnis ohne Bauen/Betreiben wollen |
Fazit
Der Peec MCP macht aus KI-Such-Messung etwas, auf das ein Agent handeln kann — die Kategorie baselinen, die Off-Domain-Lücken finden, die tatsächlichen Antworten lesen und die Arbeit zum Schließen entwerfen, während ein Mensch das Ergebnis ausliefert. Die Daten sind endlich agenten-aufrufbar; die Ausführung ist weiterhin der Ort des Werts. Beginnen Sie mit der Quellenlücke. Dann bewegen Sie die Antwort.
Wenn Sie den Agenten lieber nicht selbst bauen und betreiben wollen, ist genau das, was AI Heroes tut — Schmitdy ist unser KI-Such-Agent, gebaut auf diesem Muster, mit Menschen für Qualität und Outreach.
Der Agent für genau diese Aufgabe

Schmitdy
Turns ChatGPT, Claude, Gemini, and Perplexity into your next growth channel.
Schmitdy kennenlernenHäufig gestellte Fragen

Founder, AI Heroes
I build AI companies and the systems inside them. At AI Heroes, we give businesses the functional capacity to grow without the headcount growth normally demands — sales that follows up, marketing that runs, content that ships, ops that handles itself. We audit where you're leaving growth on the table, build the team that captures it, and hand it over completely.
I've built at scale before. Leading product and GTM at SlideSpeak AI (1M+ monthly users, profitable, bootstrapped). CPO at Disperse — the AI construction platform that went from 3 to 200+ people on $35M raised. I also co-founded LOBOMAR, a luxury fashion label featured in Elle, Cosmopolitan, and the LA Times, with shows at the London Design Museum, Wereldmuseum, and Amsterdam Fashion Week.
Ähnliche Artikel

KI-Such-Tool vs. Agentur vs. Agent: Was brauchen Sie 2026 wirklich?
Es gibt drei Wege, Ihre KI-Such-Sichtbarkeit zu verbessern, und sie sind Ebenen desselben Stacks, keine Rivalen: Ein Tool (Peec, Profound) misst, wo Sie stehen; eine Agentur erledigt die Optimierungsarbeit mit Menschen; ein Agent — ein KI-Such-Agent — bewältigt das wiederkehrende Volumen unter menschlicher Prüfung. Ein Tool verändert Ihr Verständnis, nicht die Antwort. Eine Agentur verändert die Antwort, kostet aber am meisten und arbeitet im menschlichen Tempo. Ein Agent erledigt das Volumen zu Mid-Market-Kosten, während Menschen Qualität und Strategie verantworten. 2026 behalten die meisten Teams ein Tool und ergänzen eine Ausführungsebene — die eigentliche Entscheidung ist welche.
Von Peec- oder Profound-Daten zu KI-Zitationen: ein 5-Schritte-Playbook (2026)
Ihr Peec- oder Profound-Dashboard sagt Ihnen, wo Sie in KI-Antworten unsichtbar sind, aber ein Sichtbarkeits-Score ist ein Ergebnis, keine Anweisung. Diese Daten in Zitationen zu verwandeln ist ein fünfstufiger Job: die Gap-Reports lesen statt der Vanity-Metrik, die zitierten Quellen in eine Drittquellen-Zielliste verwandeln, die Seiten reparieren, die abgerufen, aber nicht zitiert werden, die Off-Site-Präsenz aufbauen, auf die die Daten zeigen, und dann das Delta in einem Rhythmus neu messen. Der Hebel mit dem größten Gewicht ist der Quellen-/Domain-Gap-Report — die Drittseiten, die Ihre Wettbewerber zitieren, Sie aber nicht. Das meiste der Arbeit liegt außerhalb Ihrer Domain und muss wiederkehren.
Die besten AI-Search-Agenturen 2026 (GEO und AEO) im Vergleich
Die Agenturen, die dafür sorgen, dass Marken in ChatGPT, Gemini, Perplexity und Google AI Overviews zitiert werden, verglichen nach Modell, Markt und Methode, mit klaren Kriterien für die richtige Wahl. Der wichtigste Fakt vorab: Rund 85 Prozent aller KI-Zitierungen stammen von Drittanbieter-Domains, nicht von der eigenen Website.