MCP
4 Artikel
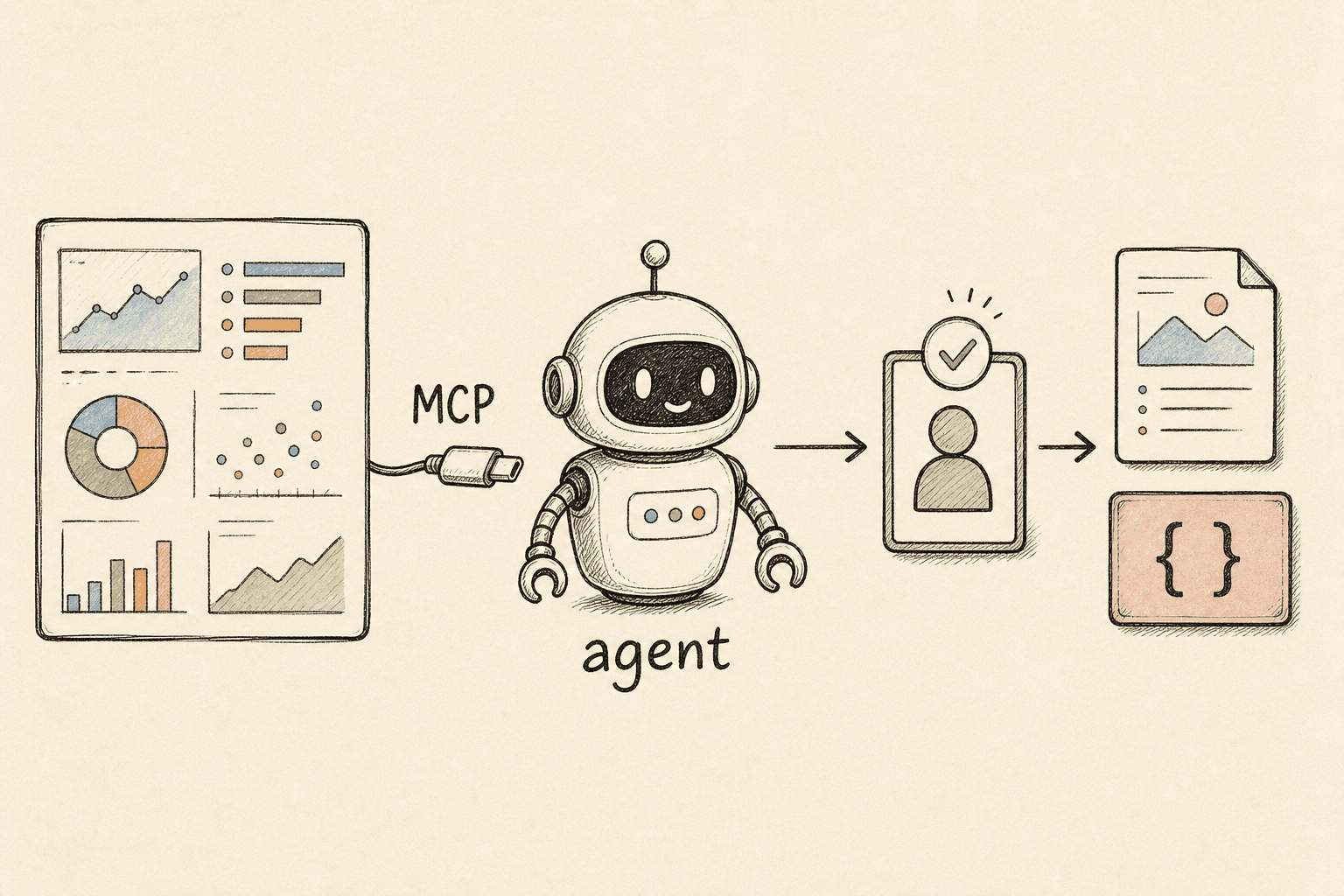
KI-Agenten auf dem Peec AI MCP für AEO und GEO bauen (2026)
Ende 2025 hat Peec AI einen offiziellen MCP-Server veröffentlicht, der die gesamte KI-Such-Mess-Ebene — Projekte, Prompts, Markensichtbarkeit pro Engine, vollständige KI-Antwort-Transkripte, den Quellen-/Zitationsgraphen und die bewerteten Actions — direkt von einem LLM-Agenten aufrufbar macht. Sie können also einen Claude- oder GPT-Agenten direkt an die Grundwahrheit anschließen, wie ChatGPT, Perplexity, Gemini und AI Overviews Ihre Kategorie beantworten, und ihn über die Daten schließen und die Arbeit zum Schließen der Lücken entwerfen lassen. Das vertretbare Build-Muster ist ein read-only, fünfstufiger Loop mit menschlichem Ship-Gate.

So funktionieren Claude Managed Agents wirklich: Dreaming, Outcomes, Multiagent-Orchestrierung und Webhooks (2026)
Anthropic hat Claude Managed Agents bei Code w/ Claude vier neue Mechaniken gegeben: Dreaming, Outcomes, Multiagent-Orchestrierung und Webhooks. Die eine, die verändert, wie man baut, ist Outcomes — ein separater Grader, der den Agenten so lange schleifen lässt, bis eine Rubrik erfüllt ist. So funktioniert jede einzelne, und wann man sie einsetzt.
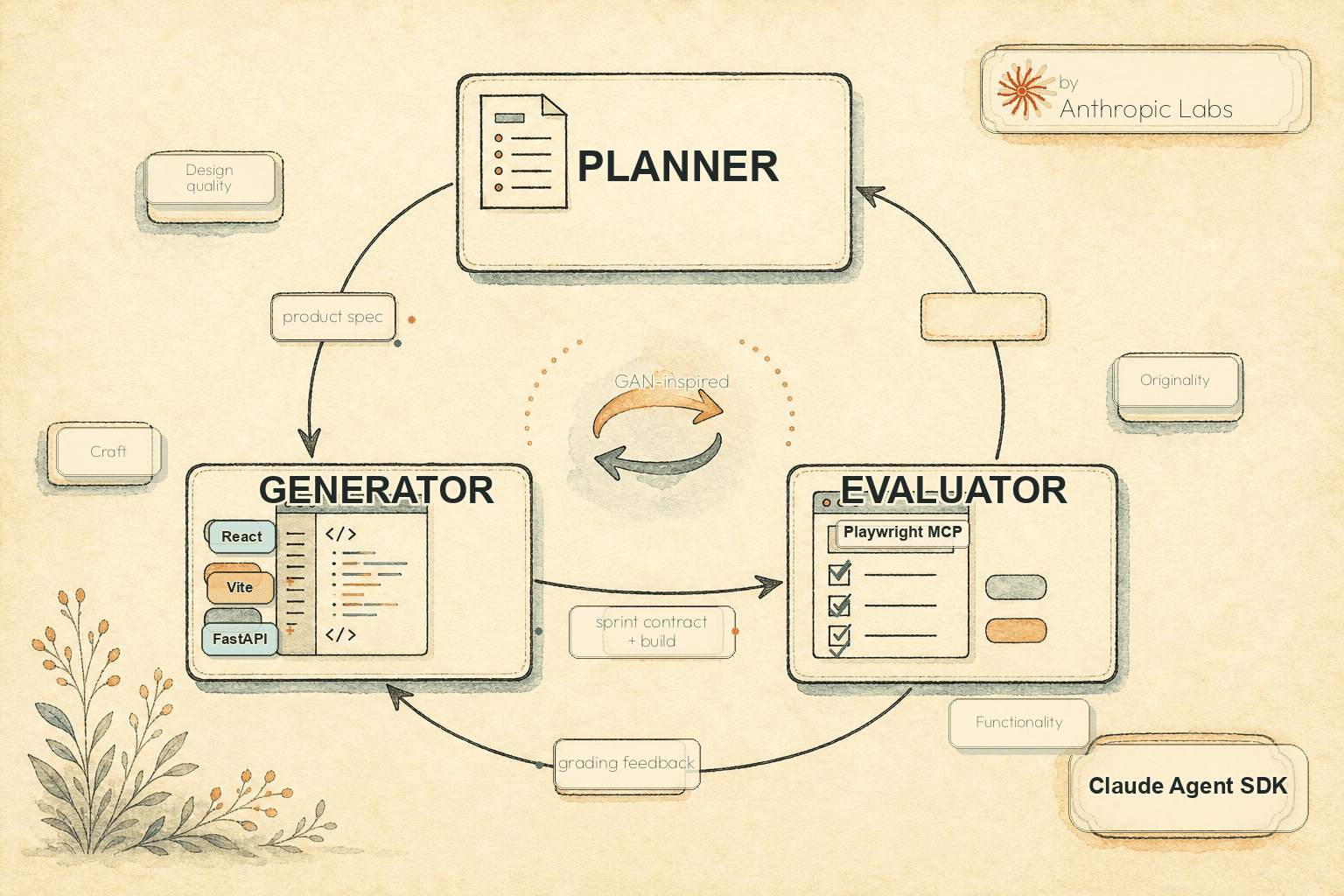
Harness Design for Long-Running AI Applications: Inside Anthropic's Generator-Evaluator Pattern (Claude Agent SDK, 2026)
On 24 March 2026 Anthropic Labs engineer Prithvi Rajasekaran published the most rigorous public account to date of how Anthropic designs harnesses for long-running AI applications — a GAN-inspired generator-evaluator pattern applied across two unusually different domains: frontend design (subjective, no binary verification) and full-stack coding (objective, machine-verifiable). The piece evolves the November 2025 Initializer + Coding Agent baseline into a three-agent planner + generator + evaluator architecture, with concrete cost-and-duration data ($200 / 6h on a retro game maker test, then $124 / 4h on a more ambitious DAW after the Opus 4.6 simplification pass). Inside the pattern, the two failure modes it fixes (context anxiety + self-evaluation bias), how it compares to LangGraph / AutoGen / OpenAI Assistants v2 / Devin, when it doesn't fit, and the canonical principle every team operating a harness should adopt: stress-test every component against the current model.
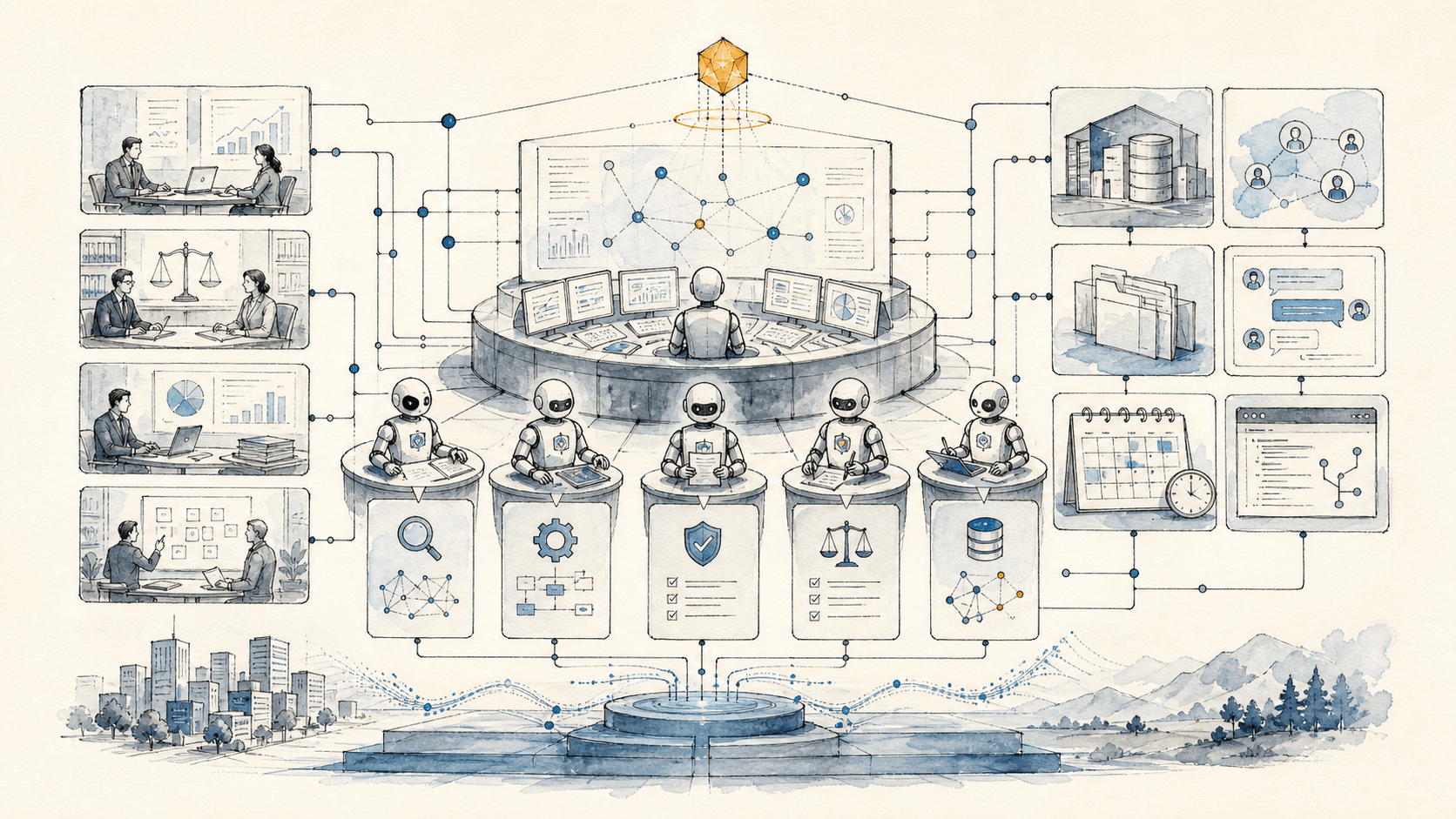
KI-Agenten im Unternehmen bauen: Implementierungsmuster für 2026
Anthropics Playbook hat die Enterprise-Form richtig benannt. Was fehlt, ist die Implementierungsschicht: kontrollierte Skills, MCP-Tools, Gedächtnis, Beobachtbarkeit, Worktree-sichere Orchestrierung und Agent-Flotten, die den Kontakt mit einem Unternehmen mit 1.000 Personen überleben.