Harness Design for Long-Running AI Applications: Inside Anthropic's Generator-Evaluator Pattern (Claude Agent SDK, 2026)
TL;DR
- On 24 March 2026 Anthropic Labs engineer Prithvi Rajasekaran published the canonical write-up of the Generator-Evaluator Harness Pattern — a GAN-inspired three-agent architecture (planner + generator + evaluator) that gets Claude through multi-hour autonomous frontend design AND full-stack coding sessions, building on (and explicitly extending) the November 2025 Initializer + Coding Agent baseline. It is the most rigorous public account of how Anthropic actually designs harnesses for long-running AI applications, and it ships a clear AI engineering principle the rest of the industry can adopt directly.
- The pattern's mechanism is separation of generation from evaluation, with a planner agent expanding a 1–4 sentence prompt into a full product spec, a generator agent building one feature at a time against that spec, and an evaluator agent (with Playwright MCP access for live page interaction) grading against pre-defined criteria. The two failure modes the harness is designed to fix are context-window degradation (including "context anxiety" — models prematurely wrapping up work as they approach perceived context limits) and self-evaluation bias (agents confidently praising their own work even when quality is obviously mediocre). Context resets — clearing the context entirely with a structured handoff — are distinct from compaction and were necessary for Claude Sonnet 4.5; with Opus 4.6 most of that scaffolding became unnecessary.
- The buyer takeaway is stress-test every harness component against the current model. Prithvi's canonical principle: "every component in a harness encodes an assumption about what the model can't do on its own, and those assumptions are worth stress testing, both because they may be incorrect, and because they can quickly go stale as models improve." When Opus 4.6 landed, the sprint construct, context resets, and per-sprint evaluator were stripped — leaving a simpler planner + generator + end-of-run evaluator harness that still produced a working DAW in ~4 hours and $124 in token costs. The interesting work for AI engineers isn't picking a static harness; it's continuously finding the next novel combination as models improve.
Last updated: 22 May 2026
On 24 March 2026 Anthropic Labs engineer Prithvi Rajasekaran published the most rigorous public account to date of how Anthropic designs harnesses for long-running AI applications — applied across two unusually different domains: frontend design (subjective, no binary verification) and full-stack coding (objective, machine-verifiable). The same architectural primitive — a GAN-inspired generator + evaluator loop, expanded into a three-agent planner + generator + evaluator system — produced working software in both. The piece builds explicitly on the November 2025 Initializer + Coding Agent pattern, but the central insight has shifted: harness design isn't about adding more agents, it's about systematically stress-testing which agents the current model still needs.
This is the post that turns harness design from "ship a harness, leave it" into "stress-test the harness every time a new model lands." The shape of the answer matters because every major agent framework in 2026 — Claude Agent SDK, LangGraph subgraphs, AutoGen GroupChat, OpenAI Assistants v2, Cognition Devin — is converging on the generator-evaluator primitive. The team that gets the discipline right captures the work.
What is the Generator-Evaluator Harness Pattern — and why isn't a single agent enough?
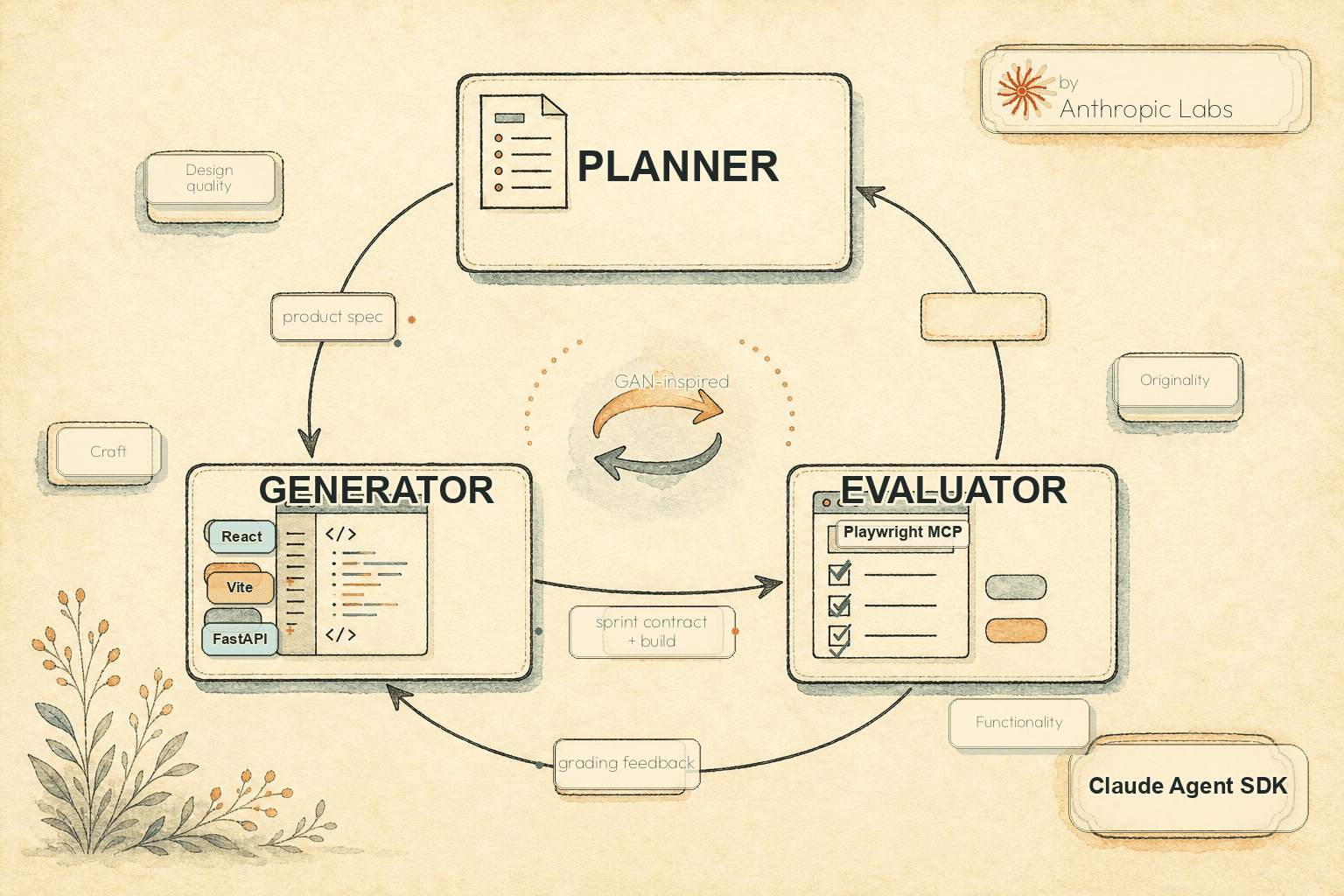
The Generator-Evaluator Harness Pattern is a GAN-inspired multi-agent architecture for long-running AI applications, in which one agent generates work and a separate agent evaluates that work against pre-defined criteria — closing the feedback loop the way a generative adversarial network closes the loop between a generator and a discriminator. In Prithvi Rajasekaran's full-stack coding harness, the pattern expands to three agents: a planner that turns a 1–4 sentence prompt into a product spec, a generator that builds the spec one feature at a time, and an evaluator that uses live browser automation to verify the work against grading criteria.
The reason a single agent isn't enough is two named failure modes Prithvi calls out explicitly. The first is context-window degradation — including the specific behaviour Anthropic now calls "context anxiety", where some models prematurely wrap up work as they approach perceived context limits. The second is self-evaluation bias — agents asked to grade their own work tend to respond by confidently praising it, even when the quality is obviously mediocre to a human observer. Both failure modes get sharper as the work gets longer and the model gets more autonomous. Separation of generation from evaluation is the strongest lever Anthropic has found for fixing both.
The Claude Agent SDK's native primitives — compaction, context awareness, sessions, subagents, hooks, MCP — are the substrate the harness sits on top of. They give the harness the building blocks. But the SDK does not ship the harness pre-wired for any specific task; the discipline is what your team builds.
What are the two failure modes the harness is designed to fix?
The harness is designed to fix two named failure modes that show up in long-running agentic work — both general enough to apply across coding and design.
Failure mode 1: context-window degradation. Models lose coherence on lengthy tasks as their context windows fill. Sonnet 4.5 in particular exhibited what Prithvi calls "context anxiety" — wrapping work up prematurely as it approached perceived context limits. The fix Anthropic ships is context resets: clearing the context window entirely and starting a fresh agent, combined with a structured handoff that carries the previous agent's state and the next steps. This is distinct from compaction, where earlier parts of the conversation are summarised in place so the same agent can keep going on a shortened history. Compaction is what the Claude 4 best practices guide recommends as the first-line defence; context resets are the heavier intervention for when compaction alone isn't enough.
Failure mode 2: self-evaluation bias. Agents asked to grade their own work skew positive. Prithvi's exact phrasing: "When asked to evaluate work they've produced, agents tend to respond by confidently praising the work — even when, to a human observer, the quality is obviously mediocre." On subjective tasks like design — where binary verification tests don't exist — this is catastrophic. Whether a layout feels polished or generic is a judgement call, and a single agent reliably scores its own output too kindly. But the same bias shows up on objectively-verifiable tasks too. The lever is to separate the agent doing the work from the agent judging it. Two prompts, two contexts, often the same model — the structural separation is what matters, not the underlying model identity.
The table below maps each failure mode to the harness component that fixes it.
| Failure mode | What it looks like in production | Harness component that fixes it |
|---|---|---|
| Context anxiety (Sonnet 4.5) | Agent wraps up work early as it approaches the context limit, leaving features half-built | Context resets between sessions + structured handoff file (Opus 4.6 mostly removed this requirement) |
| Self-evaluation bias on subjective work | Generator confidently approves its own visually-mediocre frontend | Dedicated evaluator agent with Playwright MCP + four grading criteria + few-shot calibration |
| Self-evaluation bias on objective work | Generator marks a DAW feature "done" when audio recording is stub-only and clip resize doesn't work | Same dedicated evaluator pattern + grading thresholds + sprint contracts |
| Premature optimism in code review | Evaluator identifies issues then talks itself into approving anyway | Multi-round evaluator prompt tuning + grading-divergence loop with a human in the loop |
What is the three-agent architecture: planner, generator, evaluator?
The three-agent architecture is what Prithvi shipped for full-stack coding: a planner that expands a 1–4 sentence prompt into a complete product spec, a generator that builds the app one feature at a time against the spec, and an evaluator that uses Playwright MCP to click through the running application the way a human user would and grade the work against thresholds.
Planner. Takes the user's 1–4 sentence prompt and writes a full product spec — ambitious about scope, focused on product context and high-level technical design rather than detailed technical implementation. Prithvi's prompt design explicitly avoids granular technical detail because "if the planner tried to specify granular technical details upfront and got something wrong, the errors in the spec would cascade into the downstream implementation." The planner is also instructed to "find opportunities to weave AI features into the product specs" — which is how the retro game maker test ended up with an AI-assisted sprite generator and level designer it would not have produced otherwise.
Generator. Implements the spec one feature at a time, in sprints, using a React + Vite + FastAPI + SQLite (later PostgreSQL) stack with git for version control. The generator self-evaluates at the end of each sprint before handing off to the evaluator. Sprints are bounded so the work stays inside coherent chunks the model can reliably hold.
Evaluator. Uses Playwright MCP to interact with the live application — clicking through UI features, hitting API endpoints, inspecting database state — and grades each sprint against discovered bugs plus pre-defined criteria adapted from the frontend harness (product depth, functionality, visual design, code quality). Each criterion has a hard threshold; if any one fails, the sprint fails and the generator gets detailed feedback on what went wrong.
Sprint contracts. Before each sprint, the generator and evaluator negotiate a sprint contract — agreeing on what "done" looks like for that chunk of work before any code is written. The contract bridges the gap between the planner's high-level user stories and the testable implementation the evaluator can grade. All communication between the three agents happens via files — one agent writes a file, another reads it and responds either in-place or by writing a new file.
How does the evaluator actually work — Playwright MCP, grading criteria, calibration?
The evaluator runs as its own agent with Playwright MCP access, navigates the running application autonomously, screenshots key states, and grades against four criteria adapted from Prithvi's frontend harness: design quality (coherent mood and identity), originality (custom decisions vs templates and "telltale signs of AI generation like purple gradients over white cards"), craft (typography hierarchy, spacing, colour harmony, contrast ratios), and functionality (usability independent of aesthetics).
Two non-obvious calibration moves matter. First, weight criteria against the model's baseline. Prithvi weighted design quality and originality higher than craft and functionality because "Claude already scored well on craft and functionality by default." The lift came from pushing the model away from its safe defaults toward genuine originality. Second, calibrate the evaluator with few-shot examples. Detailed score breakdowns on representative examples gave the evaluator a concrete reference point and reduced score drift across iterations.
The evaluator's value is task-relative. Prithvi names this directly: "the evaluator is not a fixed yes-or-no decision. It is worth the cost when the task sits beyond what the current model does reliably solo." On Opus 4.5, the builds Prithvi tested were at the edge of what the generator could do well solo, and the evaluator caught meaningful issues across the build. On Opus 4.6, the model's raw capability increased and the boundary moved outward — for many tasks, an evaluator at the end of the run is enough, and the per-sprint evaluator becomes redundant cost.
The evaluator is also where the honest limit shows up. "In early runs, I watched it identify legitimate issues, then talk itself into deciding they weren't a big deal and approve the work anyway." Tuning is a multi-round loop: read the evaluator's logs, find examples where its judgement diverged from yours, update the evaluator's prompt to fix that class of divergence, repeat. Several rounds of this before the grading converges on something defensible.
How does this evolve the November 2025 Initializer + Coding Agent pattern?
Prithvi's March 2026 work explicitly builds on the November 2025 Initializer + Coding Agent pattern — same Claude Agent SDK, same filesystem-native handoff, same general principle that long-running work requires structured artefacts between sessions. Two structural moves changed.
First, the planner agent generalised what the initializer used to do manually. The November 2025 pattern required the user to write a detailed feature list themselves or feed in a high-level prompt that the initializer expanded into a feature_list.json. The March 2026 planner does that expansion as a first-class agent step — and goes further by being ambitious about scope and explicitly weaving AI features into the spec. The retro game maker test started from a single sentence and produced a 16-feature spec across 10 sprints, including an AI-assisted sprite generator and level designer the user had never asked for.
Second, the evaluator added the separation-of-generation-from-evaluation lever that the Initializer + Coding pattern only handled implicitly. The November harness had the coding agent self-verify before flipping a feature's passes: true flag — but self-verification has the self-evaluation-bias problem. The March harness puts the verification in a dedicated agent with a Playwright MCP loop. That's the GAN-inspired move: separate the doer from the judge.
The two patterns are not in competition. Teams that want the simpler architecture, and whose work decomposes naturally into a stable feature list, can run the November 2025 Initializer + Coding pattern directly with the Anthropic claude-quickstarts autonomous-coding sample. Teams whose work is at the edge of what their current model does solo, or whose verification surface is subjective, should reach for the March 2026 generator-evaluator pattern.
What did the cost and duration data actually show?
Prithvi published rare cost-and-duration data on two specific harness runs. The numbers are useful as anchors for your own expectations.
| Test | Run shape | Duration | Token cost |
|---|---|---|---|
| Retro 2D game maker — solo agent | Single agent, no harness | 20 minutes | $9 |
| Retro 2D game maker — full 3-agent harness | Planner + generator + evaluator (per-sprint), Opus 4.5 | 6 hours | $200 |
| Browser DAW — simplified harness on Opus 4.6 | Planner + generator + single end-of-run evaluator (no sprint construct) | ~4 hours | $124 |
| DAW build round 1 (within above) | Generator session | 2 hr 7 min | $71.08 |
| DAW build round 2 | Generator session | 1 hr 2 min | $36.89 |
| DAW build round 3 | Generator session | 10.9 min | $5.88 |
Two things to read out. The harness is meaningfully more expensive than a solo agent — over 20× on the retro game maker test. Prithvi makes no attempt to hide that, and his framing is exactly right: "The harness was over 20x more expensive, but the difference in output quality was immediately apparent." On the solo run the actual game was broken — entities appeared on screen but nothing responded to input. On the harness run, the game played. Spending $191 of additional token cost to get from "broken" to "working" is a real trade buyers care about.
The second thing to read out is the cost trend as the harness simplifies. Once Opus 4.6 made the sprint construct unnecessary, the DAW test settled at $124 in ~4 hours — about 60% of the retro game maker harness cost despite being a more ambitious build. The lesson generalises: when the model gets better, strip components; when you strip components, the cost drops; the cost reduction is itself a signal you're stripping the right things.
How should you simplify the harness as models improve?
Prithvi's central principle is the most quotable line in the post: "every component in a harness encodes an assumption about what the model can't do on its own, and those assumptions are worth stress testing, both because they may be incorrect, and because they can quickly go stale as models improve." The corollary — drawn from Anthropic's earlier Building Effective Agents post — is "find the simplest solution possible, and only increase complexity when needed."
The methodical approach Prithvi shipped: remove one component at a time and observe what impact it had on the final result. When Opus 4.6 landed, that loop produced three concrete strips. Context resets got removed first — Opus 4.6's improved long-context retrieval and reduced context anxiety made the heavy intervention unnecessary, and compaction alone was sufficient for most runs. The sprint construct got removed next — Opus 4.6 could sustain agentic tasks for longer and stay coherent across a single multi-hour session without the explicit decomposition. Per-sprint evaluator moved to a single end-of-run evaluator pass — the model was reliable enough across the build that mid-run grading wasn't load-bearing.
What did NOT get removed. The planner stayed in — without it, the generator under-scoped, building a less feature-rich application than the planner would have produced. The evaluator stayed in for tasks at the edge of what the model could do solo (in Prithvi's language: "worth the cost when the task sits beyond what the current model does reliably solo"). The file-based handoff between agents stayed in — it's still the cleanest way to communicate sprint contracts and grading feedback.
The takeaway for any team operating a long-running agent harness: every time Anthropic ships a new model, you should run the same exercise. Strip one component, measure the impact on quality and cost, decide. Harnesses that don't get re-examined go stale fast.
How does this compare to LangGraph, AutoGen, OpenAI Assistants, and Devin?
Every major agent framework in 2026 is converging on the generator-evaluator primitive — durable state, explicit hand-off, separation of generation from judgement — but each picks a different default for where state lives, how the loop is expressed, and how much of the harness the framework itself provides. The pick matters for production stability.
| Framework | State persistence | Loop expression | Best fit for the generator-evaluator pattern |
|---|---|---|---|
| Claude Agent SDK + generator-evaluator harness | Filesystem-native + JSONL session state. Managed Agents variant uses Anthropic-hosted event log. | File-based handoff between named agents; sprint contracts; Playwright MCP for live evaluator interaction. | Teams that want full transparency into agent state on their own infrastructure; codebases already in git; tasks at the edge of what their current model does solo. |
| LangGraph (LangChain) | Pluggable checkpointers — MemorySaver, SqliteSaver, PostgresSaver, custom. | Explicit StateGraph DAG with named nodes + ConditionalEdge. Multi-agent via subgraphs. | Teams that want a graph-explicit workflow with branching, retries, and refine-vs-pivot routing as first-class primitives. |
| AutoGen (Microsoft) | Conversation-history-driven; less file-state-heavy than the Claude pattern. | GroupChat / Society-of-Mind multi-agent conversations with explicit agent roles. | Teams running multi-agent simulations or where the work is naturally conversational (research, ideation, RFP responses). |
| OpenAI Assistants v2 + Realtime Agents | Server-side threads, runs, file-search; persistence is hosted by OpenAI. | Multi-assistant patterns via thread orchestration. | Teams that want OpenAI to manage the persistence layer entirely; lower ops burden, less control. |
| Cognition Devin | Proprietary; Cognition runs the sandbox and the planning module. | Single agent with a planning + execution + verification loop. | Teams that want a fully managed long-running agent and accept the closed-source tradeoff. |
The structural insight is the same across all five: separation of generation from evaluation, durable state between sessions, explicit hand-off discipline. The variation is which layer the framework opinionates on. Claude Agent SDK's filesystem-native + filesystem-handoff model is the most transparent — every artefact is a file your team already knows how to debug, version, and audit. LangGraph's StateGraph + ConditionalEdge model is more flexible when the workflow has explicit branching (refine vs pivot, fallback paths, retry policies). Managed Agents (Anthropic's hosted variant) is the right pick if you want to scale long-running agents to production without operating the sandbox or session infrastructure yourself.
When does the generator-evaluator pattern NOT fit?
The pattern does not fit when the work has no programmatic verification surface, when the session unit is much shorter than a typical Claude context window, when the verification requires human judgement at every step, or when the cost premium isn't justified by the quality lift. Prithvi's own data shows a 20× cost multiplier vs a solo agent on one test — that's a real trade, and the right answer for many tasks is the simpler harness.
Three signals that suggest the pattern fits:
- The work has a verifiable interface — a running app the evaluator can click through, a CLI that returns exit codes, a generated artefact whose quality can be graded against named criteria. Without a verification surface, the evaluator has nothing to do.
- The task sits at or beyond the edge of what the current model does reliably solo. Inside the solo-reliable zone, the harness adds cost without adding quality.
- Quality matters enough to justify the cost premium. Internal tools, research artefacts, and customer-facing builds tend to clear this bar; throwaway scripts and one-shot analyses usually don't.
Three signals that suggest the pattern doesn't fit:
- The work is exploratory ("research the state of X and recommend a direction") rather than constructive ("build feature Y end-to-end"). Generator-evaluator presupposes a deliverable to grade.
- The verification surface requires human judgement at every step (legal review, contract interpretation, design taste). Without a machine-graders' lane, the evaluator becomes a slow human-in-the-loop bottleneck.
- The session unit is short enough that compaction alone is sufficient. If the work fits in a single Claude context window, the planner-generator-evaluator scaffold is just overhead.
What is the AI Heroes implementation pattern for a production generator-evaluator harness?
The AI Heroes implementation pattern for a production generator-evaluator harness is a four-phase loop: define the verification surface before picking the model, codify the grading criteria as an explicit harness contract, stress-test every harness component against the current model, and keep a human in the approval loop on anything customer-facing.
The four phases:
- Verification surface first. Before anything else, name what the evaluator will actually grade against — a running app with Playwright access, an API with curl-based smoke tests, a generated artefact judged against four named criteria. Without this, the rest of the harness is theatre. For coding work, the Playwright MCP + four-criteria grading model from Prithvi's frontend harness is a strong default; adapt the criteria to the specific domain.
- Grading criteria as durable IP. Write down the criteria and the thresholds in the same level of detail Anthropic uses — concrete enough that two evaluators using them on the same artefact would converge on similar scores. Calibrate with few-shot examples. The criteria are the contract; the platforms are the substrate.
- Stress-test every component against the current model. Every time Anthropic ships a new model, run Prithvi's exact exercise: remove one component, measure the impact, keep or drop. The planner is almost always load-bearing. The evaluator is task-relative. Context resets, sprint constructs, and per-sprint evaluators get stripped first as models improve.
- Human approval on anything customer-facing. Long-running agents will inevitably want to send emails, post to Slack, deploy to production, or commit to main. Every customer-facing endpoint needs an explicit approval gate. The same trust mechanic Anthropic's sales team applies to Claude Cowork — humans approve every customer-facing send — applies to engineering long-running agents.
The generator-evaluator pattern is the architecture. The grading criteria are the durable IP. The Claude Agent SDK primitives are the substrate. The human in the approval loop is the safety mechanic. The teams that get the most from a long-running agent harness refuse to ship grading criteria they wouldn't be willing to be graded against themselves. The teams that fail wire the harness as a checkbox and then discover their evaluator has been approving mediocre work for a week.
Authoritative sources
- Anthropic Engineering: Harness design for long-running application development (Prithvi Rajasekaran, Anthropic Labs, 24 Mar 2026) — the canonical write-up of the generator-evaluator harness pattern, applied to frontend design and full-stack coding.
- Anthropic Engineering: Effective harnesses for long-running agents (Justin Young, 26 Nov 2025) — the predecessor Initializer + Coding Agent pattern this work builds on.
- Anthropic Research: Building Effective Agents — the canonical source for the "find the simplest solution possible, and only increase complexity when needed" principle.
- Anthropic Engineering: Effective context engineering for AI agents — sister post on context-window management primitives.
- Claude Agent SDK overview — the SDK's tools, hooks, subagents, MCP integration, sessions, and the comparison to Client SDK / Claude Code CLI / Managed Agents.
- Anthropic claude-quickstarts: autonomous-coding — the open-source quickstart for the predecessor Initializer + Coding harness.
- Anthropic frontend-design skill (open-source) — the frontend-design Skill the planner reads to produce a visual design language for builds.
- LangGraph documentation and Microsoft AutoGen — the closest framework analogues outside the Anthropic stack.
Related reading
- Claude Code in large codebases: the 2026 implementation guide
- Claude Compliance API: the 28 security and compliance integrations now plugged into Claude Enterprise
- Anthropic's sales team on Claude Cowork: an AI-augmented sales operations layer in practice
- Building AI agents in the enterprise: implementation patterns for 2026
- The unreasonable effectiveness of HTML in Claude Code
- Claude Code vs ChatGPT Codex: which relationship do you want?
Der Agent für genau diese Aufgabe

Richard
A forward-deployed AI agent that gets your software live and adopted inside every customer.
Richard kennenlernenHäufig gestellte Fragen

Founder, AI Heroes
I build AI companies and the systems inside them. At AI Heroes, we give businesses the functional capacity to grow without the headcount growth normally demands — sales that follows up, marketing that runs, content that ships, ops that handles itself. We audit where you're leaving growth on the table, build the team that captures it, and hand it over completely.
I've built at scale before. Leading product and GTM at SlideSpeak AI (1M+ monthly users, profitable, bootstrapped). CPO at Disperse — the AI construction platform that went from 3 to 200+ people on $35M raised. I also co-founded LOBOMAR, a luxury fashion label featured in Elle, Cosmopolitan, and the LA Times, with shows at the London Design Museum, Wereldmuseum, and Amsterdam Fashion Week.
Ähnliche Artikel

So funktionieren Claude Managed Agents wirklich: Dreaming, Outcomes, Multiagent-Orchestrierung und Webhooks (2026)
Anthropic hat Claude Managed Agents bei Code w/ Claude vier neue Mechaniken gegeben: Dreaming, Outcomes, Multiagent-Orchestrierung und Webhooks. Die eine, die verändert, wie man baut, ist Outcomes — ein separater Grader, der den Agenten so lange schleifen lässt, bis eine Rubrik erfüllt ist. So funktioniert jede einzelne, und wann man sie einsetzt.

Harness Debt: Ihr KI-Agenten-Gerüst arbeitet still gegen das Modell (2026)
Ihr KI-Agent ist wahrscheinlich schlechter als das Modell darin — und die Lücke ist Ihr eigenes Gerüst. Ein experimentelles Harness erzielte mit demselben Modell mehr als das Doppelte von Anthropics Standard-Harness. Die Lösung ist kein größeres Framework, sondern das Löschen von Annahmen, die am Tag des Claude-Opus-4.6-Release veraltet waren.

Was ist Claude Tag? So funktioniert Anthropics Slack-KI-Teamkollege (2026)
Anthropic startete Claude Tag am 23. Juni 2026: eine Art, mit Claude direkt in Slack als gemeinsamem, immer aktivem Teamkollegen zu arbeiten. Man markiert @Claude, und Claude plant eine Aufgabe, nutzt die freigegebenen Tools und antwortet im Thread. Es ist multiplayerfähig, lernt aus dem Kanal, kann Initiative ergreifen und arbeitet asynchron über Stunden oder Tage. Es läuft auf Opus 4.8, ist in Beta für Enterprise und Team und ersetzt die alte Claude in Slack App.