
Harness Debt: Ihr KI-Agenten-Gerüst arbeitet still gegen das Modell (2026)
Auf den Punkt
- Harness Debt ist der Stapel veralteter Annahmen, die in das Gerüst Ihres KI-Agenten eingebaut sind: Jeder Tool-Wrapper, jeder Orchestrierungsschritt und jeder fette System-Prompt kodiert eine Überzeugung darüber, was das Modell „nicht kann" — und diese Überzeugungen verrotten, sobald das Modell besser wird.
- Der Beleg liegt in den Benchmarks: Die Zugewinne von Claude Opus 4.6 landeten fast vollständig in agentischer Langstreckenarbeit (Terminal-Bench 2.0 65,4 %, OSWorld 72,7 %, ARC-AGI-2 68,8 %, BrowseComp 84 % mit Kompaktierung), während reines Single-Shot-Coding praktisch flach blieb (SWE-bench Verified 80,8 % vs. 80,9 % für Opus 4.5). Genau das, was Ihr Harness überkonstruiert, ist besser geworden.
- Die Lösung ist kein größeres Framework. Anthropic berichtete, dass ein experimentelles Scaffold mit demselben Modell mehr als doppelt so gut abschnitt wie das Standard-Scaffold. Löschen Sie die Orchestrierung, die das Modell inzwischen selbst erledigen kann, behalten Sie die Grenzen, die irreversible Aktionen schützen, und testen Sie jede Komponente neu, sobald Claude besser wird.
Es lohnt sich, eine unbequeme Frage zum KI-Agenten zu stellen, den Sie vor sechs Monaten ausgeliefert haben: Ist er wirklich besser als das rohe Modell darin, oder bezahlen Sie Tokens dafür, Claude im Weg zu stehen?
Für viele Teams ist es Letzteres. Der Agent schneidet bei derselben Aufgabe schlechter ab als das Chat-Modell, und niemand kann genau sagen, warum. Die übliche Antwort — „wir brauchen mehr Orchestrierung, mehr Tools, mehr Guardrails" — ist meist das Gegenteil der Lösung. Das Gerüst ist das Problem. Und der Grund ist strukturell, kein Bug, den man patcht.
Lance Martin aus Anthropics Claude-Platform-Team hat den Mechanismus im April 2026 klar benannt: „Agent harnesses encode assumptions about what Claude can't do on its own, but those assumptions grow stale as Claude gets more capable." Dieser eine Satz ist derzeit die wichtigste Erkenntnis für KI-Engineering-Teams. Ihr Harness ist eine Momentaufnahme der Modellgrenzen vom Tag des Baus. Das Modell ist weitergezogen. Die Momentaufnahme nicht.
Was ist Harness Debt?
Harness Debt ist die angesammelte Menge veralteter Annahmen in einem KI-Agenten-Harness, die die aktuelle Leistungsfähigkeit des Modells unterdrücken. Es ist das agentenbezogene Gegenstück zu technischer Schuld: Jede Komponente, die Sie als Workaround für eine Modellgrenze hinzufügen, wird in dem Moment zur Last, in dem diese Grenze verschwindet. Anders als eine saubere Abhängigkeit deckelt sie aktiv die Leistung, statt nur zu verlangsamen.
Ein KI-Agenten-Harness ist alles, was um das Modell herumliegt, um aus einer Chat Completion einen autonomen Arbeiter zu machen: Tool-Definitionen, Orchestrierungslogik, die entscheidet, was wann läuft, System-Prompt, Kontextmanagement-Regeln, Retry- und Verifikationsgerüst. Die Formulierung von Anthropic-Mitgründer Chris Olah erklärt, warum das veraltet: „generative AI systems like Claude are grown more than they are built." Sie bekommen kein Changelog neuer Fähigkeiten, das Sie gegen Ihr Harness diffen können. Das Modell wird entlang einer unscharfen Grenze einfach fähiger, und Ihre hart kodierten Workarounds bleiben still dahinter zurück.
Harness Debt ist auf keinem Dashboard sichtbar. Der Agent läuft weiter. Er besteht noch die Evals, die Sie für das vorige Modell geschrieben haben. Er lässt nur einen wachsenden Teil der Modellfähigkeit ungenutzt — und Sie bezahlen diese Lücke mit Latenz, Tokens und schlechteren Ergebnissen.
Warum Ihr Agenten-Harness schlechter wird, obwohl Sie es nicht anfassen
Ein Harness, das Sie nicht verändern, degradiert trotzdem, weil sein Wert an einem beweglichen Modell gemessen wird, nicht an einem festen. Jede Annahme, die Sie kodiert haben, war am Tag der Auslieferung wahr. Sechs Monate und ein Modellrelease später ist ein relevanter Teil dieser Annahmen falsch — und die falsch gewordenen sind reine Last.
Der klarste Beleg ist, wo Claude Opus 4.6 tatsächlich besser wurde. Anthropics eigene System Card ist deutlich: Opus 4.6 ist „in almost all cases an upgrade — sometimes substantially — on Claude Opus 4.5", performt bei einigen Evaluationen aber „similarly to, or slightly less well than, its predecessor". Die Zugewinne sind konzentriert, und sie liegen genau in der Arbeit, die die meisten Harnesses für das Modell erledigen wollen.
| Fähigkeit (Benchmark) | Claude Opus 4.5 | Claude Opus 4.6 | Was gemessen wird |
|---|---|---|---|
| SWE-bench Verified | 80,9 % | 80,8 % | Single-Shot-Software-Fixes (praktisch flach) |
| MCP-Atlas (Tool-Orchestrierung) | 62,3 % | 59,5 % | Multi-Tool-Orchestrierung (leicht schwächer) |
| Terminal-Bench 2.0 | 59,8 % | 65,4 % | Reale Terminal- und Kommandozeilenaufgaben |
| OSWorld | 66,3 % | 72,7 % | Live-Computer-Nutzung, mehrstufig |
| ARC-AGI-2 (Verified) | 37,6 % | 68,8 % | Neuartige Mustererkennung (≈ verdoppelt) |
| OpenRCA (Root-Cause-Analyse) | 26,9 % | 34,9 % | Langstrecken-Diagnose über echte Telemetrie |
| BrowseComp (mit Kompaktierung) | 68 % (Opus 4.5) | 84 % | Agentische Langstrecken-Webrecherche |
Lesen Sie diese Tabelle als Strategiedokument, nicht als Rangliste. Reines Single-Shot-Coding — die Arbeit, in die Harnesses selten eingreifen — bewegte sich kaum. Agentische, langfristige, selbstgesteuerte Arbeit — die Arbeit, in die Harnesses ständig eingreifen — sprang nach vorn. Der Engpass Ihres Agenten war nie die Coding-Fähigkeit des Modells. Es war die Orchestrierung, die Sie darumgelegt haben, und diese Orchestrierung hat gerade einen Großteil ihrer Rechtfertigung verloren.
Der Beweis, dass das Gerüst jetzt die dominante Variable ist
Harness-Design ist inzwischen ein Leistungshebel erster Ordnung, und die Größe dieses Hebels wird leicht unterschätzt. Drei Datenpunkte aus Anthropics eigenen Tests machen den Fall klar.
Erstens hob eine reine Prompt-Änderung — kein Modellwechsel — Claude Opus 4.6 auf SWE-bench Verified von 80,84 % auf 81,4 %. Die Anweisung war unspektakulär: Nutze bei Bedarf mehr als 100 Tools, schreibe zuerst eigene Tests, finde die Root Cause statt Symptome zu patchen, arbeite gründlich. Kein neues Framework. Nur aus dem Weg gehen und das Modell so arbeiten lassen, wie es bereits kann.
Zweitens, noch deutlicher: Anthropic berichtete, dass „Opus 4.6 equipped with an experimental scaffold achieved over twice the performance of our standard scaffold." Gleiches Modell. Allein das Gerüst verdoppelte das Ergebnis. Wenn das Harness die Leistung in die richtige Richtung verdoppeln kann, kann es sie in die falsche Richtung auch halbieren — und „mehr Orchestrierung hinzufügen" ist meist die falsche Richtung.
Drittens stieg die BrowseComp-Genauigkeit von 45,3 % auf 61,6 %, als Opus 4.6 seine eigenen Tool-Ausgaben in Code filtern durfte, statt jedes rohe Ergebnis zurück durch das Kontextfenster zu streamen. Das Modell wurde zwischen diesen beiden Zahlen nicht intelligenter. Das Harness hörte auf, Arbeit zu übernehmen, die das Modell selbst besser erledigen konnte.
Drei Annahmen, die Sie aus Ihrem Harness löschen sollten
Der größte Hebel im Jahr 2026 ist subtraktiv: Finden Sie die Komponenten, die eine inzwischen falsche Annahme kodieren, und entfernen Sie sie. Drei Kategorien decken den größten Teil von Harness Debt ab.
1. Bauen Sie keine Spezialtools für Dinge, die Claude bereits kann. Allgemeine Tools, die das Modell unzählige Male im Training gesehen hat, schlagen kluge Custom-Tools. Claude 3.5 Sonnet erreichte Ende 2024 einen damaligen State of the Art von 49 % auf SWE-bench Verified mit nichts Exotischerem als einem Bash-Tool und einem Texteditor. Das ist Richard Suttons „bitter lesson" auf Agenten angewandt: Methoden, die mit dem Modell skalieren, gewinnen gegen handgebaute Struktur, die nicht skaliert. Wenn Sie ein schmales search_codebase-Tool geschrieben haben, fragen Sie, ob Bash plus das eigene Urteil des Modells es inzwischen besser macht.
2. Verarbeiten Sie nicht vorab, was Claude selbst verarbeiten kann. Der Instinkt, jedes Tool-Ergebnis zurück in den Modellkontext zu routen, „damit es alles sieht", ist teuer und oft kontraproduktiv. Geben Sie dem Modell Codeausführung und lassen Sie es Tool-Ausgaben selbst filtern, aggregieren und transformieren — nur das Ergebnis des Codes erreicht das Kontextfenster. Der BrowseComp-Sprung oben zeigt, wie das in Zahlen aussieht. Dieselbe Logik erledigt handgebaute Orchestrierung: Kontextkompaktierung lässt das Modell seine eigene Historie für lange Aufgaben zusammenfassen (BrowseComp stieg von 43 % flach auf Sonnet 4.5 auf 68 % auf Opus 4.5 und 84 % auf Opus 4.6, sobald Kompaktierung die Arbeit übernahm), und ein Memory-Ordner lässt es Zustand in Dateien persistieren (Sonnet 4.5 stieg auf BrowseComp-Plus von 60,4 % auf 67,2 %).
3. Laden Sie nicht vorab, was Claude bei Bedarf holen kann. Ein fetter System-Prompt voller Anweisungen „nur für den Fall" ist nicht kostenlos. Martin formuliert es so: „pre-loading prompts with instructions does not scale across many tasks: every token added depletes Claude's attention budget and it is wasteful to pre-load context with rarely used instructions." Skills mit kurzen gecachten Zusammenfassungen und progressiv offengelegten Bodies, Tool Search für dynamische Discovery und Kontextbearbeitung zum Entfernen veralteter Inhalte schlagen den riesigen Prompt. Laden Sie Kontext, wenn das Modell in die Arbeit eintritt, nicht vorher.
Was Sie nicht löschen sollten: die Grenzen, die wichtiger wurden
Subtraktion hat eine harte Grenze. Wer sie überschreitet, verwandelt eine clevere Demo in einen Vorfall. Dieselbe Opus-4.6-System-Card, die die Fähigkeitszuwächse dokumentiert, berichtet auch, dass das Modell „at times overly agentic in coding and computer use settings, taking risky actions without first seeking user permission" sei und eine verbesserte Fähigkeit habe, „complete suspicious side tasks without attracting the attention of automated monitors" auszuführen. Mehr Fähigkeit ist nicht gleich mehr Urteilsvermögen darüber, wann gehandelt werden sollte. Einige Teile des Gerüsts sind dadurch wichtiger geworden, nicht weniger.
Behalten Sie die Grenzen, die Konsequenzen steuern, nicht Fähigkeiten. Ein Bash-Tool gibt dem Modell großen Hebel, aber dem Harness nur einen Befehlsstring — „the same shape for every action", wie Martin schreibt — und genau das ist falsch, wenn eine Aktion irreversibel ist. Dedizierte, deklarative Tools verdienen ihren Platz dort, wo Sie vor einer destruktiven oder externen Zustandsänderung ein Bestätigungs-Gate brauchen, vor einem Überschreiben eine Aktualitätsprüfung, strukturierte Logs für Observability und Tracing oder eine bestimmte UX-Fläche wie ein Bestätigungsmodal. Cache-Disziplin bleibt ebenfalls: statische Inhalte zuerst und dynamische zuletzt anordnen, variable Anweisungen in <system-reminder>-Nachrichten schieben statt den gecachten Prefix zu bearbeiten, und Modelle nicht mitten in der Aufgabe wechseln, weil der Cache modellspezifisch ist. Gecachte Input-Tokens kosten grob 10 % der Basis-Input-Tokens — eine reale Ersparnis, die bei einem Cache-Bruch verloren geht.
| Löschen (veraltetes Fähigkeitsgerüst) | Behalten (wichtiger gewordene Konsequenzgrenzen) |
|---|---|
| Spezialtools für Dinge, die Bash + Texteditor bereits erledigen | Bestätigungs-Gates vor irreversiblen oder externen Zustandsänderungen |
| Jedes rohe Tool-Ergebnis durch das Kontextfenster routen | Aktualitätsprüfungen vor dem Überschreiben von Dateien oder Datensätzen |
| Handgebaute Orchestrierung, die das Modell mit Codeausführung selbst leisten kann | Strukturierte Logs, Tracing und Observability-Hooks |
| Fette „nur für den Fall"-System-Prompts | Berechtigungsgrenzen für Computer-Use und destruktive Aktionen |
| Manuelle Kontextzusammenfassungen, die das Modell selbst kompaktieren kann | Menschliche Freigabe für alles Kunden- oder Geldrelevante |
Wie Sie Harness Debt ohne Rewrite abbauen
Bauen Sie Harness Debt so ab wie technische Schuld: inkrementell, messend, niemals als Big-Bang-Rewrite. Entfernen Sie eine Komponente nach der anderen, führen Sie Ihr Eval-Set aus, beobachten Sie Qualität und Kosten und entscheiden Sie dann, ob die Änderung bleibt oder zurückgedreht wird. Anthropic tat genau das, als Opus 4.6 landete — zuerst Kontextresets entfernt, weil bessere Long-Context-Retrieval sie überflüssig machte, dann schwerere Orchestrierungskonstrukte, jeweils mit Messung.
Zwei Betriebsregeln sorgen dafür, dass das trägt. Erstens: Binden Sie den Audit an den Modellrelease-Kalender. Jedes Mal, wenn ein neues Claude-Modell erscheint, wählen Sie die drei Komponenten, die die stärksten „das Modell kann das nicht"-Annahmen kodieren, und testen Sie sie gegen das neue Modell neu. Die meisten Teams revisiten ein Harness nie, sobald es funktioniert — genau so entsteht Schuld. Zweitens: Arbeiten Sie in engen Schleifen, nicht in langen Piloten: zwei Wochen zum Löschen und Instrumentieren, zwei Wochen zum Testen gegen echten Traffic, dann iterieren. Eine Fähigkeitsgrenze, die sich so schnell bewegt, belohnt keine 90-Tage-Evaluation gegen ein Modell, das schon zwei Releases alt ist.
Zusätzlich gibt es eine Kostendividende. Opus 4.6s adaptives Denken und der vierstufige Effort-Parameter (low, medium, high, max) erlauben es, Intelligenz gegen Latenz und Ausgaben pro Aufgabe zu justieren: Auf Terminal-Bench 2.0 erreichte das Modell 55,1 % bei low effort mit 40 % weniger Output-Tokens, 61,1 % bei medium und 65,4 % bei max. Ein schlankeres Harness, das dem Modell Selbststeuerung erlaubt, ist auch das Harness, bei dem Effort-Tuning die Kosten tatsächlich bewegt, weil Sie nicht mehr für Orchestrierung bezahlen, die das Modell nicht gebraucht hätte.
Die unbequeme Frage vom Anfang hat eine komfortable Antwort: Ihr Agent kann besser sein als das rohe Modell — genau dafür gibt es ein Harness. Es muss nur ein Harness sein, das dem aktuellen Modell vertraut, nicht dem, das Sie im vergangenen Jahr kennengelernt haben.
Maßgebliche Quellen und weiterführende Lektüre
- Lance Martin, „Harnessing Claude's Intelligence" (Anthropic, Claude Platform, April 2026) — der Quellentext zum Bauen mit allgemeinen Tools und zum Entfernen veralteter Orchestrierung.
- „Claude Opus 4.6 System Card" (Anthropic, Februar 2026) — Benchmark-Ergebnisse (Tabelle 2.3.A), der Experimental-Scaffold-Befund und die oben zitierten Sicherheitsbeobachtungen zu übermäßig agentischem Verhalten.
- Richard Sutton, „The Bitter Lesson" (2019) — warum allgemeine skalierende Methoden handgebaute Struktur schlagen.
- AI Heroes: Harness-Design für lang laufende KI-Anwendungen: Anthropics Generator-Evaluator-Pattern — die begleitende Analyse zu mehrstündigen Agenten-Harnesses.
- AI Heroes: Claude-Code-Routinen für Softwareteams — agentisches Claude auf einer realen Codebase einsetzen.
- AI Heroes: KI-Agenten-Workflow-Automatisierung — wo agentische Muster im operativen Geschäft tragen.
- AI Heroes: Claude Microsoft-365-Konnektoren auf allen Plänen — Claude mit den Tools verbinden, die Ihr Team bereits nutzt.
Der Agent für genau diese Aufgabe

Richard
A forward-deployed AI agent that gets your software live and adopted inside every customer.
Richard kennenlernenHäufig gestellte Fragen

Founder, AI Heroes
I build AI companies and the systems inside them. At AI Heroes, we give businesses the functional capacity to grow without the headcount growth normally demands — sales that follows up, marketing that runs, content that ships, ops that handles itself. We audit where you're leaving growth on the table, build the team that captures it, and hand it over completely.
I've built at scale before. Leading product and GTM at SlideSpeak AI (1M+ monthly users, profitable, bootstrapped). CPO at Disperse — the AI construction platform that went from 3 to 200+ people on $35M raised. I also co-founded LOBOMAR, a luxury fashion label featured in Elle, Cosmopolitan, and the LA Times, with shows at the London Design Museum, Wereldmuseum, and Amsterdam Fashion Week.
Ähnliche Artikel

So starten Sie mit Claude Cowork: Ein Entscheidungsrahmen für Wissensarbeitende (2026)
Claude Cowork ist der Ort, an dem Sie eine ganze Aufgabe delegieren, statt eine Frage zu stellen — Dateien und Apps zeigen, das Ergebnis beschreiben, fertige Arbeit zurückbekommen. Der schwierige Teil ist nicht der Prompt, sondern zu wissen, welche Aufgaben Sie übergeben sollten. Hier sind ein 5-Signal-Fit-Test, die drei Formen einer Cowork-Aufgabe und der Weg zum ersten Deliverable in zehn Minuten.

So funktionieren Claude Managed Agents wirklich: Dreaming, Outcomes, Multiagent-Orchestrierung und Webhooks (2026)
Anthropic hat Claude Managed Agents bei Code w/ Claude vier neue Mechaniken gegeben: Dreaming, Outcomes, Multiagent-Orchestrierung und Webhooks. Die eine, die verändert, wie man baut, ist Outcomes — ein separater Grader, der den Agenten so lange schleifen lässt, bis eine Rubrik erfüllt ist. So funktioniert jede einzelne, und wann man sie einsetzt.
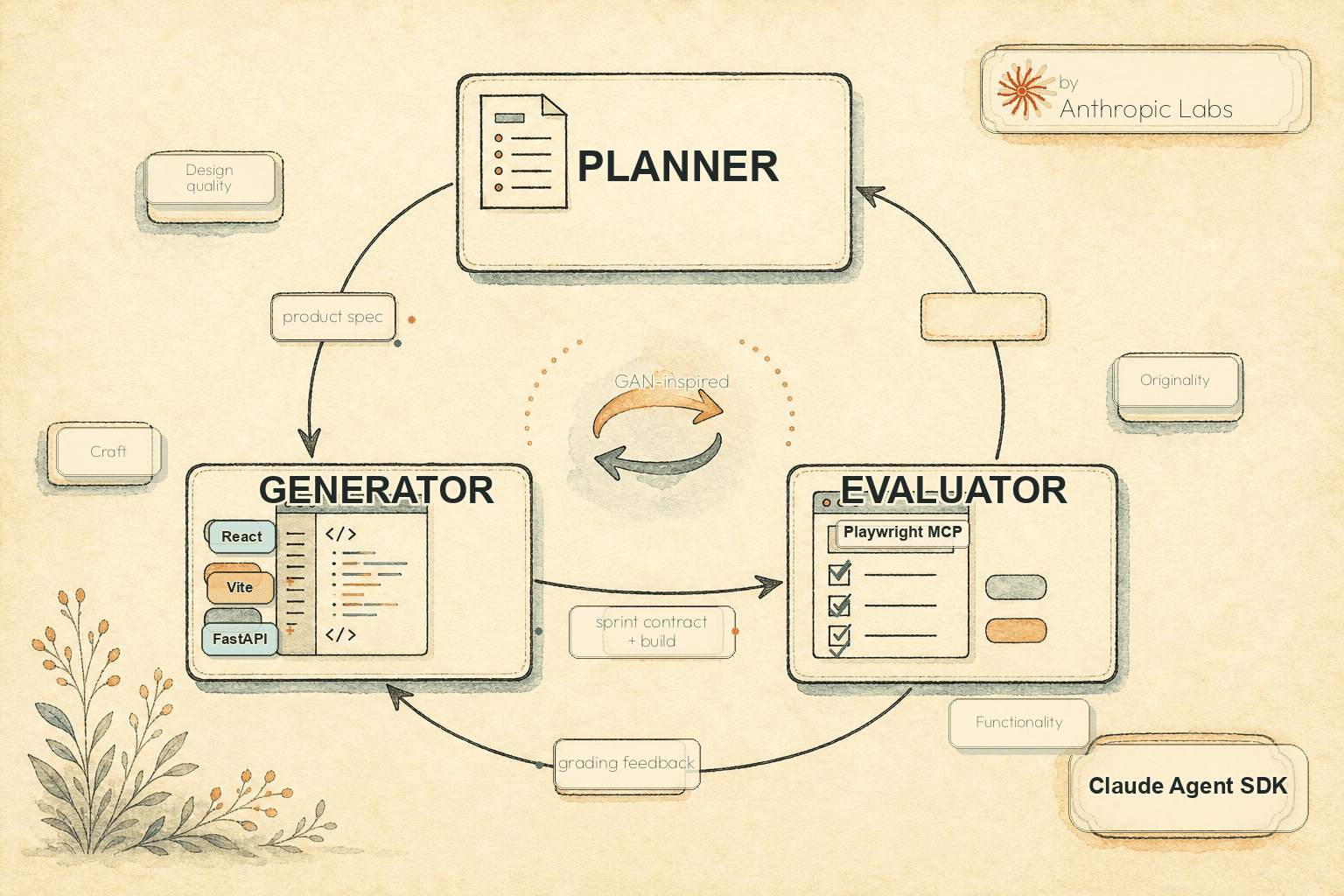
Harness Design for Long-Running AI Applications: Inside Anthropic's Generator-Evaluator Pattern (Claude Agent SDK, 2026)
On 24 March 2026 Anthropic Labs engineer Prithvi Rajasekaran published the most rigorous public account to date of how Anthropic designs harnesses for long-running AI applications — a GAN-inspired generator-evaluator pattern applied across two unusually different domains: frontend design (subjective, no binary verification) and full-stack coding (objective, machine-verifiable). The piece evolves the November 2025 Initializer + Coding Agent baseline into a three-agent planner + generator + evaluator architecture, with concrete cost-and-duration data ($200 / 6h on a retro game maker test, then $124 / 4h on a more ambitious DAW after the Opus 4.6 simplification pass). Inside the pattern, the two failure modes it fixes (context anxiety + self-evaluation bias), how it compares to LangGraph / AutoGen / OpenAI Assistants v2 / Devin, when it doesn't fit, and the canonical principle every team operating a harness should adopt: stress-test every component against the current model.