
Die Lücke zwischen den Leitplanken
Auf den Punkt
- Starre Automatisierung und freier KI-Chat scheitern auf entgegengesetzte Weise; die fehlende Schicht ist dokumentiertes Urteil, das Agenten ausführen können.
- Davids Logistikworkflow funktionierte nur für regelhafte Intake-Fälle, bis Force-Majeure-, Sonderabrechnungs- und Schadensfälle die Lücke zeigten.
- Skills erzeugen kein Urteil; sie kodieren es, deshalb müssen menschliche Overrides in die Referenzdateien zurückfließen.
Warum starre Automatisierung und offene KI-Chat-Interfaces beide an derselben Stelle scheitern — und welche Mittelschicht die meisten Teams nie gebaut haben.
47 Anfragen, 7 Eskalationen, 3 Fehler
David leitet ein Logistikunternehmen in Amsterdam. Vor sechs Monaten implementierte sein Team ein KI-gestütztes Intake-System für Kundenanfragen. Am Dienstag verarbeitete es 47 Anfragen. Sieben wurden für die manuelle Prüfung markiert.
Das klingt nach einer Erfolgsgeschichte. War es nicht.
Drei der sieben eskalierten Anfragen waren Standardfälle — eine Force-Majeure-Klausel in einem SLA, ein individuelles Rechnungsformat, eine falsch zugeordnete beschädigte Sendung. Alle drei hätten automatisch bearbeitet werden können. Und eine Anfrage, die nicht eskaliert wurde — eine beschädigte Sendung, die vom Zoll festgehalten wurde — hätte es unbedingt werden müssen.
Das System war nicht defekt. Es war zu starr für Fälle, die Urteilsvermögen erforderten, und zu offen für Fälle, die keines erforderten. David steckte in der Lücke zwischen den Leitplanken.

Zwei Automatisierungskatastrophen
Die erste Katastrophe ist die starre Automatisierung. Zapier, Make.com, regelbasierte Pipelines — sie funktionieren hervorragend, solange die Eingabe dem erwarteten Format entspricht. Davids System fror ein, als eine beschädigte Sendung vom Zoll wegen einer regulatorischen Prüfung festgehalten wurde. Der Fall passte in keine vordefinierte Kategorie. Das System leitete ihn in die Standardschlange. Niemand sah ihn rechtzeitig.
Starre Automatisierung scheitert nicht laut. Sie scheitert still — indem sie Ausnahmen wie Regelfälle behandelt.
Die zweite Katastrophe ist das offene KI-Chat-Interface. In Dublin hatte eine Customer-Success-Leiterin eines SaaS-Unternehmens ein gemeinsames Claude-Projekt eingerichtet. Ihr Team nutzte es für Kundenantworten, Zusammenfassungen, Eskalationsnotizen. Die Ergebnisse waren nie zweimal gleich. Ton, Detailtiefe, Struktur — alles variierte je nach Person, Tageszeit und wie die Frage formuliert wurde.
Die Outputs waren nicht schlecht. Sie waren inkonsistent. Und in einem kundenorientierten Team ist Inkonsistenz nicht akzeptabel.
Beide Katastrophen haben denselben Kern: Der Mensch ist nach wie vor die Leitplanke. Bei starrer Automatisierung ist der Mensch die Ausnahmebehandlung. Beim offenen Chat ist der Mensch die Qualitätskontrolle. In beiden Fällen skaliert das nicht.
Die Ebene, die dazwischen liegt
David arbeitete mit seiner leitenden Koordinatorin zusammen, um das Urteilsvermögen hinter dem Intake-Prozess zu kartieren. Nicht die Regeln — die wusste das System bereits. Sondern die Entscheidungen, die ein erfahrener Koordinator trifft, wenn eine Anfrage nicht eindeutig in eine Kategorie fällt.
Das Ergebnis: eine skill.md-Datei, die den Entscheidungsbaum kodifizierte. Referenzdateien für SLA-Typen, Eskalationskriterien und Zollszenarien. Claude Code verband alles zu einem funktionierenden System.
Was David damit gebaut hatte, war kein besseres Automatisierungstool. Es war ein trainierter Junior-Koordinator — ein System, das Urteilsvermögen anwenden konnte, ohne es selbst zu besitzen.
Der messbare Unterschied: Eskalationen kamen jetzt mit einer vorläufigen Analyse an. Die Prüfzeit pro Eskalation sank von 20 Minuten auf 4 Minuten. Nicht weil die Eskalationen einfacher wurden — sondern weil das System die Vorarbeit leistete, die früher der erfahrene Koordinator im Kopf erledigte.
Das Design, das Context Overload verhindert
In Brüssel hatte ein Versicherungsmakler ein anderes Problem. Er hatte 23 Skills gleichzeitig geladen — für verschiedene Versicherungsarten, Schadensszenarien, regulatorische Prüfungen. Die Ausgabequalität verschlechterte sich spürbar. Der Agent versuchte, alle 23 Kontexte gleichzeitig zu berücksichtigen, und produzierte generische, unspezifische Ergebnisse.
Die Lösung heißt Progressive Disclosure. Beim Start lädt der Agent nur die Metadaten aller verfügbaren Skills — eine kurze Beschreibung, die Auslösebedingungen, die Kategorie. Der vollständige Skill mit allen Referenzdateien wird erst geladen, wenn die Anfrage tatsächlich diesen Skill erfordert.
Das Ergebnis: Der Makler verarbeitet jetzt 31 verschiedene Workflows — mehr als vorher — mit besserer Ausgabequalität. Nicht durch ein leistungsfähigeres Modell, sondern durch ein intelligenteres Ladedesign.
Progressive Disclosure ist keine technische Spielerei. Es ist die Antwort auf eine grundlegende Einschränkung: Kontextfenster sind endlich, und ein Agent, der alles gleichzeitig wissen muss, weiß am Ende nichts besonders gut.
Wo die Mittelschicht versagt
Sechs Wochen nach der Implementierung traf Davids System auf einen Hafenstreik, der durch eine regulatorische Maßnahme ausgelöst worden war. Der Skill für Force-Majeure-Fälle griff — und behandelte den Fall zuversichtlich, vollständig und falsch.
Das Problem: Der Skill kodifizierte das Urteilsvermögen, das Davids Team zu einem bestimmten Zeitpunkt hatte. Er konnte keine neuen Urteile bilden. Er konnte keine Situation erkennen, die grundlegend anders war als alles, was in den Referenzdateien stand.
Skills kodifizieren Urteilsvermögen. Sie erzeugen es nicht.
Das bedeutet: Ein Feedback-Loop ist nicht optional. Er ist architektonisch notwendig. Wenn ein Skill eine Entscheidung trifft, die ein Mensch überstimmt, muss diese Überstimmung zurück in die Referenzdateien fließen. Nicht irgendwann. Systematisch. Weil ein Skill ohne Feedback-Loop ein eingefrenes Urteilsvermögen ist — und eingefrorenes Urteilsvermögen wird mit der Zeit falsch.
Die Frage, die David nicht mehr stellt
David fragt nicht mehr: „Welche Aufgaben kann ich automatisieren?"
Er fragt: „Welches Urteilsvermögen in meinem Unternehmen ist gut genug dokumentiert, um portabel zu sein?"
Das ist eine grundlegend andere Frage. Die erste führt zu Tools. Die zweite führt zu Architektur. Und die Lücke, in der Davids Team steckte — zwischen starrer Automatisierung und inkonsistentem Chat — ist im Kern eine Dokumentationslücke.
Die Prozesse existieren. Das Urteilsvermögen existiert. Es wurde nur nie in eine Form gebracht, die ein Agent nutzen kann.
Die Lücke zwischen Ihren Leitplanken schließen? Sprechen Sie mit AI Heroes — wir helfen Ihnen, die Mittelschicht zu bauen, die zwischen Automatisierung und Urteilsvermögen fehlt.
Der Agent für genau diese Aufgabe

Richard
A forward-deployed AI agent that gets your software live and adopted inside every customer.
Richard kennenlernenHäufig gestellte Fragen

Founder, AI Heroes
I build AI companies and the systems inside them. At AI Heroes, we give businesses the functional capacity to grow without the headcount growth normally demands — sales that follows up, marketing that runs, content that ships, ops that handles itself. We audit where you're leaving growth on the table, build the team that captures it, and hand it over completely.
I've built at scale before. Leading product and GTM at SlideSpeak AI (1M+ monthly users, profitable, bootstrapped). CPO at Disperse — the AI construction platform that went from 3 to 200+ people on $35M raised. I also co-founded LOBOMAR, a luxury fashion label featured in Elle, Cosmopolitan, and the LA Times, with shows at the London Design Museum, Wereldmuseum, and Amsterdam Fashion Week.
Ähnliche Artikel
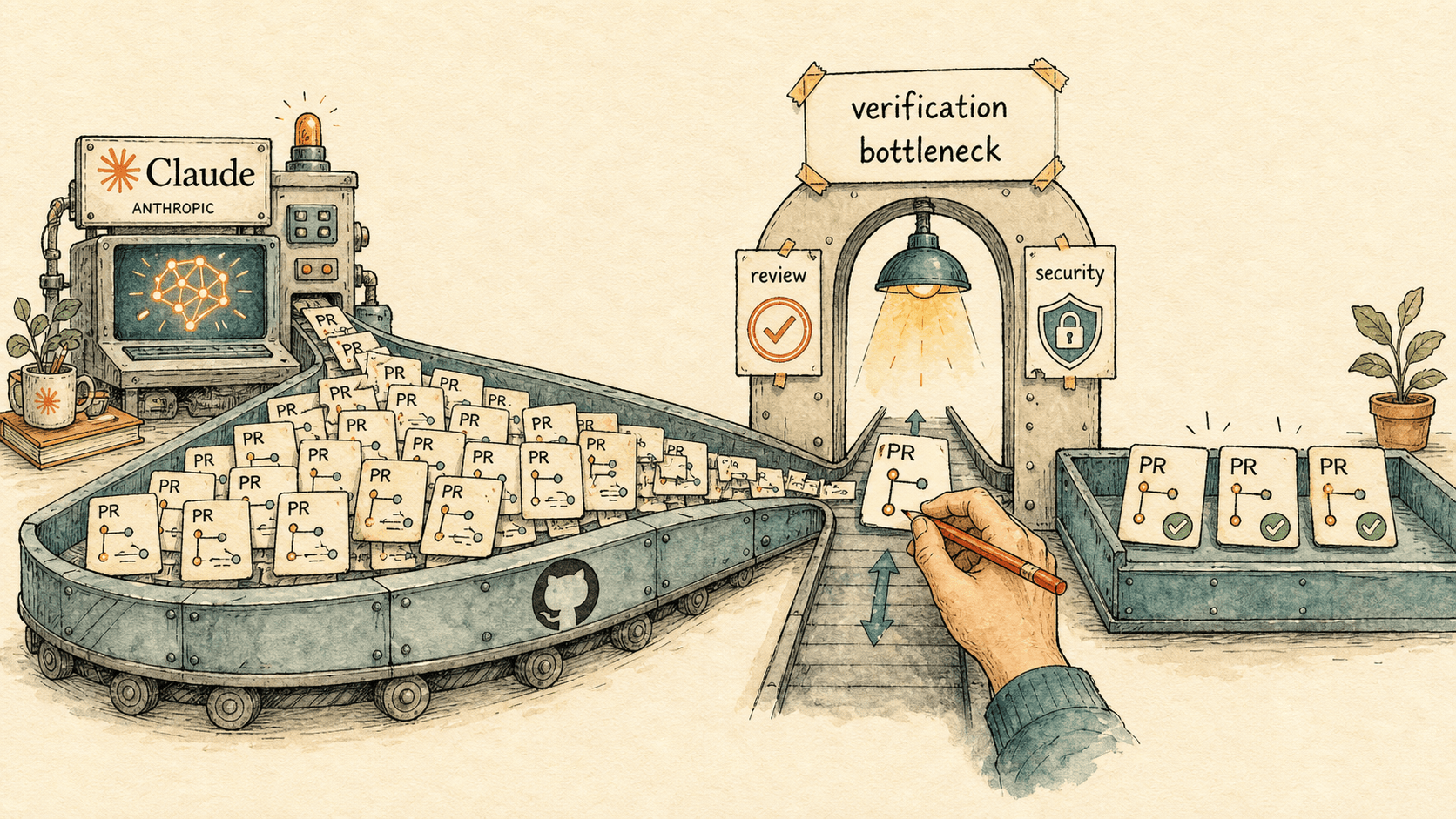
Wie man 2026 eine KI-native Engineering-Organisation führt
Agentic Coding entfernt den Engineering-Engpass nicht — er verschiebt ihn vom Schreiben des Codes zur Verifizierung. Das ist das Betriebsmodell 2026 für eine KI-native Engineering-Organisation: welche Prozesse neu geschrieben werden müssen, wie Code Review sich verändert und welche Metriken zeigen, ob es funktioniert.
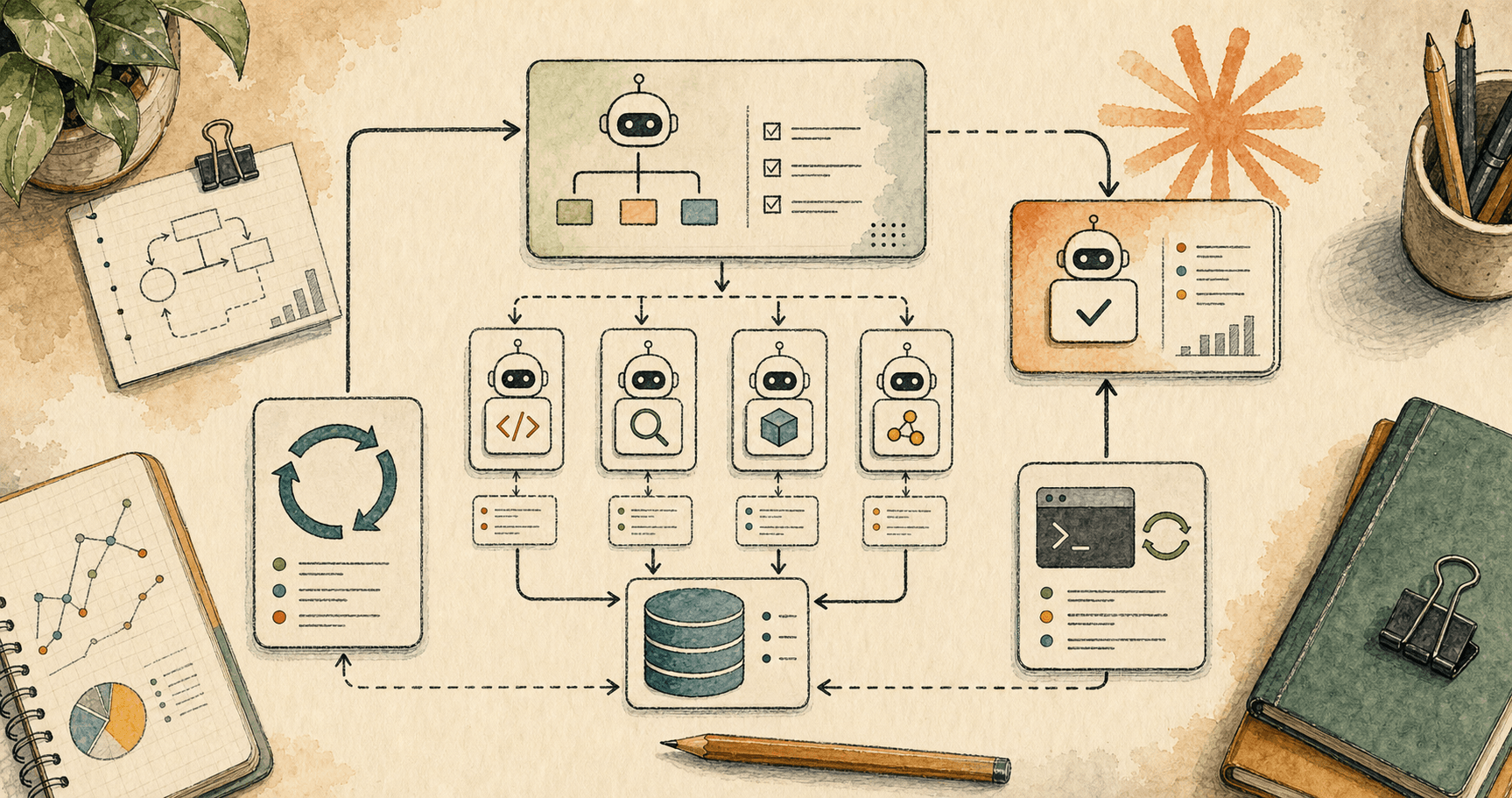
Claude Code Dynamic Workflows: What Is Actually New in 2026?
Claude Code dynamic workflows are not just parallel agents. They turn a prompt into an executable orchestration script that can split work, store intermediate results, cross-check findings and return one synthesised answer.
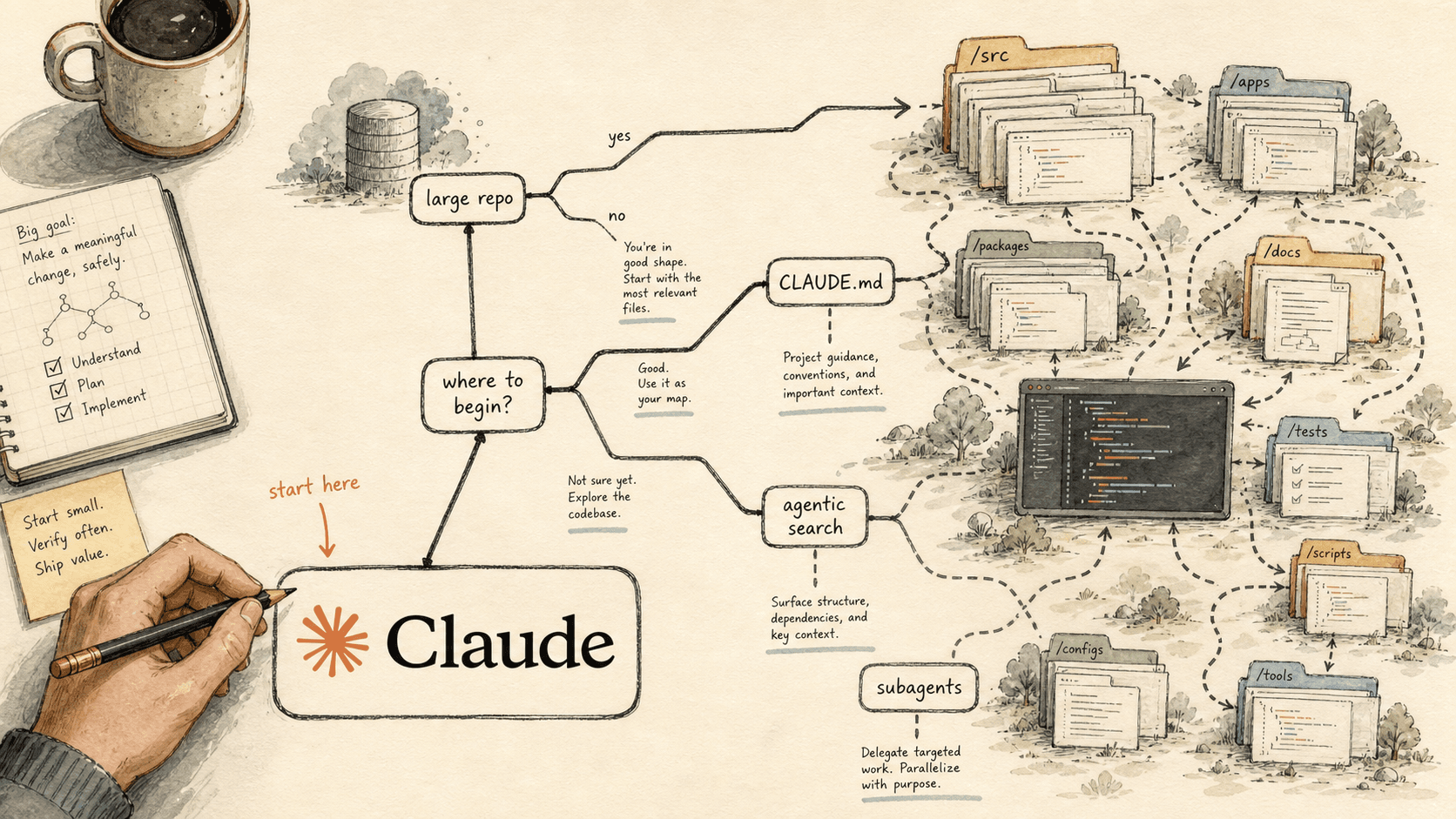
Wo Sie mit Claude Code in einem großen Repo anfangen: ein Entscheidungsbaum (2026)
Sie starten einen großen Claude-Code-Rollout nicht damit, alles zu konfigurieren. Sie starten mit dem einen Mechanismus, den Repo-Form und echter Schmerzpunkt verlangen — und ignorieren den Rest, bis Sie ihn wirklich brauchen. Das ist die Entscheidungsschicht vor dem Build.