Auf den Punkt
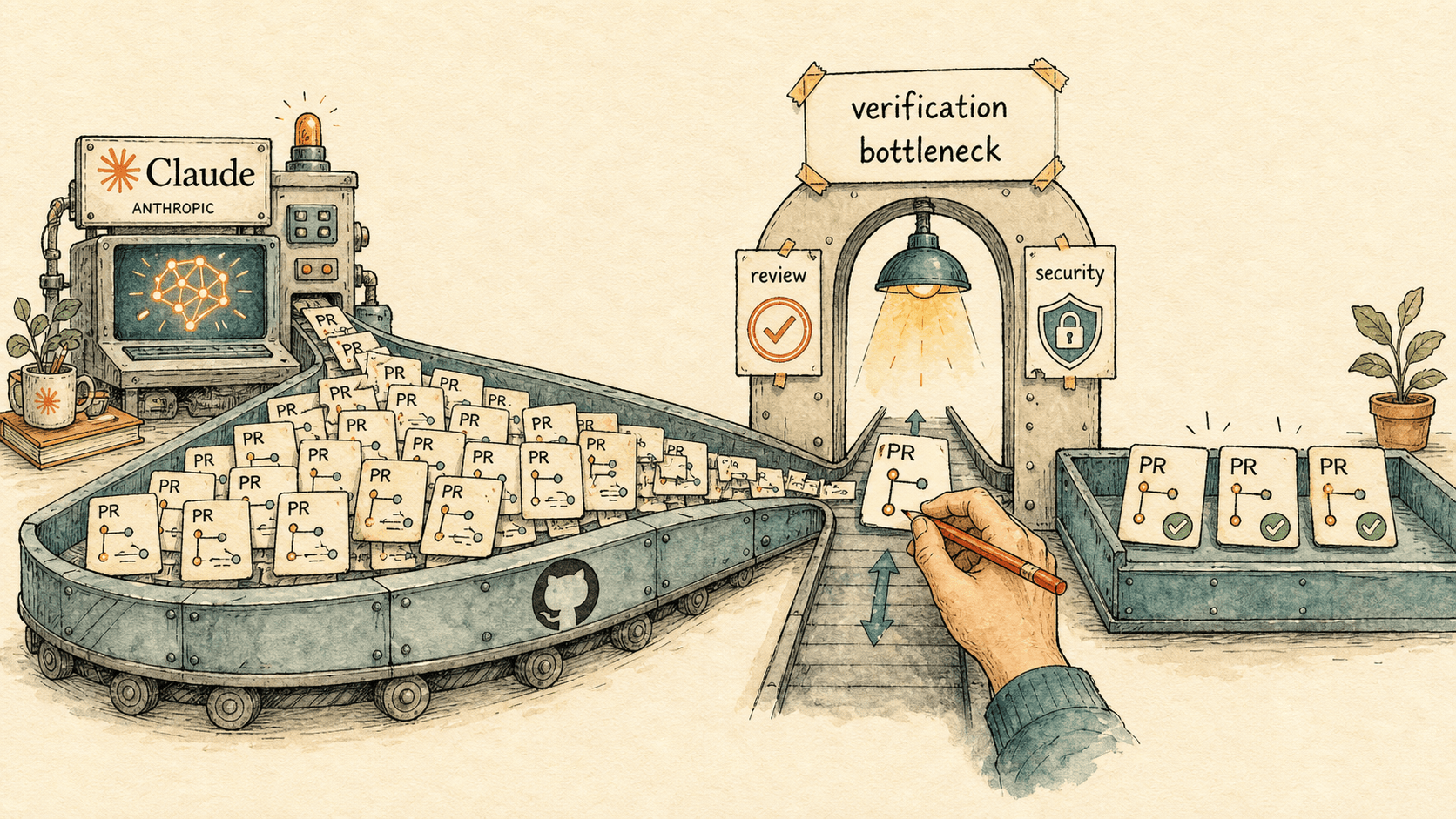
- Wenn agentisches Coding zum Standard wird, verschwindet der Engineering-Engpass nicht — er verschiebt sich. Code schreiben, testen und refactoren ist nicht mehr die knappe Stelle; Verifizierung, Code Review und Security werden es. Das Claude-Code-Team von Anthropic sagt das ungewöhnlich klar, und die unabhängigen Daten aus 2026 stützen es.
- Der Verifizierungs-Engpass (verification bottleneck) ist inzwischen messbar. Laut Sonars 2026er Befragung von mehr als 1.100 professionellen Entwicklerinnen und Entwicklern schreibt KI rund 42% des committed Codes — gleichzeitig sagen 96%, dass sie nicht vollständig darauf vertrauen, dass er korrekt ist, und nur 48% prüfen ihn immer vor dem Commit. Die Zeit geht jetzt in Review-Warteschlangen, nicht in Tastaturen.
- Eine KI-native Engineering-Organisation zu führen bedeutet, vier Dinge um genau diese Verschiebung herum neu zu bauen — Planung, Kontextbeschaffung, Code Review und Teamzuschnitt — und dann Frühindikatoren zu messen (Onboarding-Ramp, PR-Zykluszeit, Anteil KI-unterstützter Commits), ohne Durchsatz mit Erfolg zu verwechseln. KI auf Prozesse zu schrauben, die für den alten Engpass gebaut wurden, erzeugt Schleudertrauma; wer um den neuen Engpass herum umbaut, bekommt den Gewinn.
Zwei Jahrzehnte lang war Engineering-Bandbreite der teure Teil des Softwarebaus. Waterfall, dann Agile, dann Continuous Delivery — jeder Prozess, den Führungskräfte eingeführt haben, war von den Kosten geprägt, die Menschen beim Schreiben von Code verursachten. Agentisches Coding zieht diese Annahme unter dem ganzen Stack weg. Wenn ein Modell den Großteil des Codes schreibt, testet und refactort, lautet die Frage nicht mehr: "Wie shippen wir schneller?", sondern: "Wie vertrauen wir dem, was wir gerade geshippt haben, und wer muss noch darauf schauen?"
Anthropics eigenes Claude-Code-Team ist dazu ungewöhnlich offen. Bei Code w/ Claude SF 2026 beschrieb Fiona Fung — Director of Engineering für Claude Code und Claude Cowork —, wie das Team seine Normen neu schrieb, sobald agentisches Coding zum Standard wurde. Ihre schärfste Zeile ist die, die die meisten Führungskräfte unterschätzen: Code zu schreiben "rarely slows us down anymore. But the bottlenecks didn't go away when agentic coding took away the actual need to type code. Verification, code review, and security took their place." Dieser Beitrag nimmt diese Beobachtung, verankert sie und macht daraus ein Betriebsmodell, das jede Engineering-Organisation tatsächlich anwenden kann — nicht nur die, die das Modell selbst baut.
Was ist eine KI-native Engineering-Organisation?
Eine KI-native Engineering-Organisation ist eine Organisation, deren Planung, Reviews, Rollen und Metriken um agentisches Coding als Standardarbeitsweise herum neu gestaltet wurden — statt es auf Prozesse zu schrauben, die aus einer Zeit stammen, in der Menschen den größten Teil des Codes tippten. Der Unterschied ist wichtig, weil der Fehler so häufig ist: Teams führen die Tools ein, behalten den alten Workflow und wundern sich, wenn Output steigt, aber Outcomes nicht.
Die entscheidende Verschiebung lautet nicht: "Wir nutzen jetzt KI." Sondern: Die knappe Ressource hat gewechselt. Code-Generierung ist reichlich und billig geworden; vertrauenswürdige Verifizierung ist zur Beschränkung geworden. Eine Organisation, die das verinnerlicht hat — und ihre Prozesse entsprechend umgebaut hat — ist KI-nativ. Eine Organisation mit den Tools, aber der alten Form ist nur eine KI-unterstützte Version ihres früheren Selbst, meistens eine langsamere.
Was ändert sich tatsächlich, wenn KI den Großteil des Codes schreibt?
Der Engpass wandert von der Codeproduktion zur Verifizierung, und der bestehende Prozess der meisten Organisationen wurde gebaut, um das falsche Ende dieser Pipeline zu schützen. Die Zahlen für 2026 machen die Größenordnung konkret. Sonars State-of-Code-Befragung von über 1.100 Entwicklerinnen und Entwicklern beziffert den KI-Anteil am committed Code auf etwa 42%, mit einem erwarteten Anstieg auf 65% bis 2027. GitHub berichtet, dass Coding-Assistenten inzwischen fast die Hälfte des Codes auf der Plattform erzeugen, und Gartner prognostiziert, dass bis Ende 2026 60% des neuen Codes KI-generiert sein werden. Unterschiedliche Methoden, unterschiedliche genaue Zahlen — aber jede belastbare Quelle zeigt in dieselbe Richtung: Das Volumen an Code, das in der Review-Warteschlange ankommt, ist deutlich gestiegen.
Was nicht mitgewachsen ist, ist menschliche Aufmerksamkeit. In denselben Sonar-Daten sagen 96% der Entwicklerinnen und Entwickler, dass sie KI-generiertem Code nicht vollständig vertrauen, gleichzeitig prüfen nur 48% ihn immer vor dem Commit. Unabhängige Engineering-Leadership-Berichte aus 2026 beschreiben die Folge als Review-Engpass: mehr generierter Code, als Menschen lesen, verstehen und validieren können, mit dem Druck auf den erfahrensten Reviewerinnen und Reviewern. Mehrere Analysen berichten, dass PR-Review-Zeiten steigen, obwohl der Merge-Durchsatz zunimmt — das Muster, das manche "acceleration whiplash" nennen: Der obere Teil des Funnels beschleunigt, und jede Stufe darunter staut sich.
Das ist die strukturelle Veränderung. Nicht: "Ingenieurinnen und Ingenieure sind schneller." Sondern: Sie sind anders belastet. Die teure, urteilsintensive Arbeit ist nachgelagert, und ein Prozess, der knappe Coding-Zeit rationieren sollte, rationiert jetzt die falsche Sache.
Was ist der Verifizierungs-Engpass?
Der Verifizierungs-Engpass ist der Punkt in einer KI-nativen Software-Pipeline, an dem vertrauenswürdige menschliche Prüfung, Security-Scrutiny und Korrektheitsprüfung — nicht Code-Generierung — zur begrenzenden Größe dafür werden, wie schnell und wie sicher ein Team shippen kann. Es ist das agentic-coding-Äquivalent zu einer Fabrik, deren Maschinen plötzlich zehnmal so viele Teile produzieren, während die einzelne Qualitätsprüfstation gleich groß bleibt: Der Gesamtausstoß wird jetzt durch Prüfung begrenzt, und mehr Maschinen machen die Warteschlange schlimmer, nicht besser.
Ihn zu benennen ist wichtig, weil es zeigt, wo investiert werden muss. Wenn die Beschränkung Verifizierung ist, dann schiebt mehr Generierungskapazität — mehr Seats, mehr Agents, mehr Orchestrierung — nur mehr Arbeit in die Warteschlange, die bereits der Engpass ist. Der Hebel liegt auf der anderen Seite: Verifizierung schneller und gezielter machen. Das heißt, dem Modell die Verifizierung zu geben, die es zuverlässig leisten kann (Style, Linting, Testgenerierung, erster Bug-Fang), und menschliches Urteil für die Stellen zu reservieren, an denen es das Ergebnis tatsächlich verändert. Anthropics Team routet genau so — Claude übernimmt Style, Linting, PR-Feedback-Anfragen und Bug-Funde vor dem Commit über seinen Code Review workflow, und Menschen bleiben "where it matters": rechtliche Risikotoleranz, Vertrauensgrenzen und sicherheitssensibler Code, sowie Produktgeschmack.
Welche Engineering-Prozesse hören leise auf zu funktionieren?
Vier Normen brechen zuerst, und eine KI-native Organisation schreibt jede davon bewusst neu, statt zu warten, bis sie versagt. Fungs Formulierung ist, dass obsolete Prozesse "rarely go away on their own" — sie müssen aktiv beendet werden. Das ändert sich:
| Prozess | Für den alten Engpass gebaut | Für den neuen Engpass neu gebaut |
|---|---|---|
| Planung | Sechs-Monats-Roadmaps und schwere Design-Dokumente, weil Coding-Zeit teuer war und Vorplanung rechtfertigte. | Just-in-time-Planung: prototypen, interne Nutzerinnen und Nutzer darauf setzen, Feedback aufnehmen. Roadmaps, die sechs Monate vorausgeschrieben werden, sind in Monat drei veraltet. |
| Kontextbeschaffung | "Wer hat diesen Code geschrieben?" — Autorin oder Autor finden und fragen. | Die Codebase fragen, nicht die Person. Entscheiden, was man wirklich braucht — wer eine Regression verursacht hat, welche Begründung hinter einer Entscheidung stand — dann das Modell fragen und prüfen, ob die Frage ganz automatisiert werden kann. |
| Code Review | Menschen reviewen alles. | Das Modell übernimmt Style, Linting, Tests und erste Bug-Funde. Menschen reviewen dort, wo Fachurteil entscheidend ist: Security, Recht, Produktgeschmack. |
| Teamzuschnitt | Feste Rollen — Engineers coden, PMs planen, Designer gestalten. | Rollen verschwimmen. PMs prototypen in Code; Engineers übernehmen Design und Content. Eingestellt werden kreative Builder mit Produktsinn und Engineers mit tiefem Systemverständnis — nicht reiner Durchsatz, den liefern die Modelle jetzt. |
Der rote Faden ist, dass jeder alte Prozess für die Kosten des Codeschreibens optimiert war. Sobald diese Kosten einbrechen, ist der Prozess entweder neutral oder aktiv im Weg. Just-in-time-Planung ist nicht "weniger Planung" — sie ist Planung für eine Welt, in der Richtungswechsel billig geworden sind. "Die Codebase fragen" ist keine Bequemlichkeit — es erkennt an, dass der schnellste Weg zu Kontext nicht mehr der Kalender eines Menschen ist.
Wie sollte Code Review in einer KI-nativen Organisation funktionieren?
Code Review wird zu einer Arbeitsteilung zwischen Modell und menschlichen Expertinnen und Experten, wobei sich die Grenze jedes Mal verschiebt, wenn das Modell besser wird. Die zuverlässige Regel lautet "trust but verify": Das Modell übernimmt mechanische, hochvolumige Prüfungen; Menschen konzentrieren sich auf Kategorien, in denen Fehler teuer sind und Urteil nicht reduzierbar ist — Security und Vertrauensgrenzen, Recht und Risikotoleranz, sowie Produktgefühl.
Was Führungskräfte übersehen: Diese Grenze ist nicht fix. Fung sagt ausdrücklich, dass "the right balance of trust vs. verify will keep changing as the models improve. What you need humans for today might look different with the next model." Damit wird die Trust-but-verify-Grenze zu etwas, das regelmäßig überprüft werden muss, nicht einmal gesetzt. Eine Organisation, die "Menschen reviewen alles" festschreibt, verschwendet ihre knappste Ressource auf Prüfungen, die das Modell inzwischen gut erledigt; eine Organisation, die das Modell still sicherheitssensiblen Code reviewen lässt, nur weil es bei einfachen Dingen gut wurde, riskiert die um 23% höheren Incident-Raten, die einige 2026er Analysen mit unterreviewten KI-PRs verbinden. Die Disziplin besteht darin, Release für Release zu fragen, welche Verifizierung noch einen Menschen braucht — und die Grenze auf Evidenz zu bewegen, nicht nach Gefühl.
Wie rollt man neue Normen aus, ohne Chaos zu erzeugen?
Man schreibt eine kleine Zahl nicht verhandelbarer Prinzipien vor und lässt Teams alles andere selbst besitzen. Anthropics Claude-Code-Team arbeitet mit drei "must-dos" und breiter Pod-Autonomie innerhalb dieser Leitplanken:
- Das eigene Produkt unerbittlich dogfooden. Jedes Teammitglied, auch cross-funktionale Partner, nutzt das Produkt täglich und sucht nach dem nächsten Workflow, der automatisiert werden kann. Man kann nicht von außen um KI herum redesignen.
- Das Team so flach wie möglich halten. Manager starten als ICs, shippen echten Code und unterstützen Arbeits-Pods, während Menschen dorthin wechseln, wo die Arbeit liegt. Eine flache Struktur lässt sich schneller um Arbeit herum neu formen, als sich die Arbeit verändert.
- Nicht zögern, Prozesse zu töten, die nicht mehr funktionieren. Teammitglieder haben explizit die Erlaubnis, jeden Prozess zu hinterfragen und zu beenden, dessen ursprüngliche Lücke geschlossen ist.
Innerhalb dieser Regeln entscheiden Pods selbst über Triage, Standups, Planungsrituale und welche Workflows zuerst automatisiert werden. Genau dieser Teil lässt sich gut auf Nicht-Anthropic-Organisationen übertragen: Man muss nicht jeden Workflow zentral diktieren. Man braucht wenige tragende Prinzipien, die Erlaubnis, tote Prozesse zu beenden, und kleine Teams mit der Autorität, ihre eigene Ecke neu zu gestalten. Ein wiederkehrendes manuelles Ritual in etwas zu verwandeln, das als automatisierte Routine läuft, ist genau die Pod-Bewegung, die sich kumuliert.
Woran erkennt man, ob die KI-native Umstellung wirklich funktioniert?
Man verfolgt Frühindikatoren des neuen Engpasses und verwechselt Durchsatz nicht mit Erfolg. Drei Zahlen lohnen sich ab Tag eins — aber jede braucht eine Leitplanke, weil die naheliegende Version manipulierbar oder missverständlich ist.
| Metrik | Was sie zeigt | Die Leitplanke |
|---|---|---|
| Onboarding-Ramp-Time | Wie schnell eine neue Engineer, Designerin oder PM wirksam wird. In einem KI-nativen Team sollte das deutlich fallen — neue Mitarbeitende shippen echten Code innerhalb einer Woche. | Ramp-Time ist wertlos, wenn frühes "Shipped" nur den Review-Backlog vergrößert. Messen Sie Ramp bis zu reviewtem, gemergtem, stabilem Beitrag. |
| PR-Zykluszeit | Wo die Pipeline unter steigendem Codevolumen ächzt — oft CI und Review-Kapazität, also der sichtbar gewordene Verifizierungs-Engpass. | Zerlegen Sie sie. Steigende time-to-first-review (Code wartet in der Queue) ist das Engpass-Signal; steigende review duration, sobald jemand dran ist, kann gesunde Sorgfalt sein. |
| Anteil KI-unterstützter Commits | Wie tief agentisches Coding wirklich zum Standard geworden ist. In einem reifen Team tendiert das gegen "fast jeder Commit". | Das ist die Metrik, die am ehesten zur Vanity Metric wird. Hoher KI-Anteil bei steigenden Defekten oder Churn heißt: Sie generieren schneller, als Sie verifizieren. |
Der ehrliche Vorbehalt, in Fungs Worten: "don't confuse throughput with success. Throughput is one metric, but the real metric is measuring the thing you're trying to solve." Hier stoßen auch die üblichen Delivery-Dashboards an Grenzen. Die verbreiteten DORA-Metriken bleiben wichtig, aber 2026er Analysen sagen klar, dass sie allein nicht unterscheiden können, ob Code KI- oder menschlich erzeugt ist, und dass sie die Qualitätskosten unter steigender Velocity nicht sichtbar machen. Die Lösung, auf die Engineering-Leadership-Forschung konvergiert, ist eine KI-Attributionslinse: Metriken danach segmentieren, wie viel einer Änderung KI-generiert war, und Code-Churn-Ratios beobachten, damit "wir haben mehr geshippt" gegen "und es hat gehalten" geprüft wird. Ein Verifizierungs- und Evaluationsgate, das Agentenoutput bestehen muss, bevor er als erledigt zählt, ist derselbe Instinkt auf Workflow-Ebene.
Wo sollte eine Engineering-Führungskraft anfangen?
Beginnen Sie mit Ihrem lautesten Workflow — dem teuersten, gefürchtetsten oder unbeliebtesten — und fragen Sie, ob er seinen Zweck noch erfüllt und ob er automatisiert werden kann. Fungs Beispiel ist das wiederkehrende Statusmeeting, in dem alle an ihren Laptops saßen, bis sie mit ihrem Bericht dran waren; eine Frage — "why are we having this meeting?" — reichte, um es zu streichen. Das lässt sich verallgemeinern: Der erste Schritt in Richtung KI-nativ ist nicht Toolkauf, sondern ein Prozessaudit auf Lücken, die bereits geschlossen sind.
Wenn Sie einen schärferen Einstieg wollen, wählen Sie den Workflow, der dem Verifizierungs-Engpass am nächsten sitzt. Code-Generierung zu automatisieren, wenn Ihre Review-Queue schon verstopft ist, füttert nur die Beschränkung. Triage, First-Pass-Review, Testgenerierung oder Kontextbeschaffung zu automatisieren, entlastet sie. Dasselbe gilt dafür, wo man Agents überhaupt einführt: Den ersten Mechanismus an den tatsächlichen Schmerz koppeln, so wie es unser Entscheidungsbaum für große Repos tut, statt eine Oberfläche aufzusetzen, die man noch nicht debuggen kann. Und halten Sie den Stack schlank — ein überbautes Scaffold sammelt Harness Debt und kämpft leise gegen das Modell, für das Sie bezahlen.
Die Organisationen, die die nächsten zwei Jahre gewinnen, werden nicht die sein, die am meisten Code generiert haben. Es werden die sein, die gemerkt haben, dass der Engpass gewandert ist — und vor der Konkurrenz darum herum neu gebaut haben.
Maßgebliche Quellen & weiterführende Lektüre
-
Anthropic / Claude — Running an AI-native engineering org (primary source; Fiona Fung, Code w/ Claude SF 2026)
-
Anthropic / Claude — Code Review (Claude Code docs) (how the model handles style, linting and first-pass bug-catching)
-
Anthropic / Claude — Claude Code on the web (running agents beyond the terminal — the systems work behind "run Claude everywhere")
-
Sonar — State of Code Developer Survey 2026 (1,100+ developers: ~42% of committed code AI-generated; 96% don't fully trust it, 48% always verify)
-
GitHub / Gartner — AI now generates close to half of code on GitHub; Gartner projects 60% of new code AI-generated by end of 2026
-
DORA / engineering-leadership analyses (2026) — why DORA metrics need an AI-attribution lens to separate throughput gains from quality cost
-
AI Heroes: Harness Debt: Ihr KI-Agenten-Scaffolding kämpft leise gegen das Modell — warum ein schlanker Stack besser ist als ein ausgefeilter, sobald das Modell besser wird.
-
AI Heroes: Wo man mit Claude Code in einem großen Repo anfängt: ein Entscheidungsbaum — den ersten Mechanismus an den tatsächlichen Schmerz koppeln.
-
AI Heroes: Claude-Code-Routinen für Softwareteams — ein wiederkehrendes manuelles Ritual in einen automatisierten Workflow verwandeln.
-
AI Heroes: Der Long-Running-Agent-Harness auf dem Claude Agent SDK — ein Verifizierungs- und Evaluationsgate zwischen Agent und "erledigt" setzen.
Der Agent für genau diese Aufgabe

Richard
A forward-deployed AI agent that gets your software live and adopted inside every customer.
Richard kennenlernenHäufig gestellte Fragen

Founder, AI Heroes
I build AI companies and the systems inside them. At AI Heroes, we give businesses the functional capacity to grow without the headcount growth normally demands — sales that follows up, marketing that runs, content that ships, ops that handles itself. We audit where you're leaving growth on the table, build the team that captures it, and hand it over completely.
I've built at scale before. Leading product and GTM at SlideSpeak AI (1M+ monthly users, profitable, bootstrapped). CPO at Disperse — the AI construction platform that went from 3 to 200+ people on $35M raised. I also co-founded LOBOMAR, a luxury fashion label featured in Elle, Cosmopolitan, and the LA Times, with shows at the London Design Museum, Wereldmuseum, and Amsterdam Fashion Week.
Ähnliche Artikel
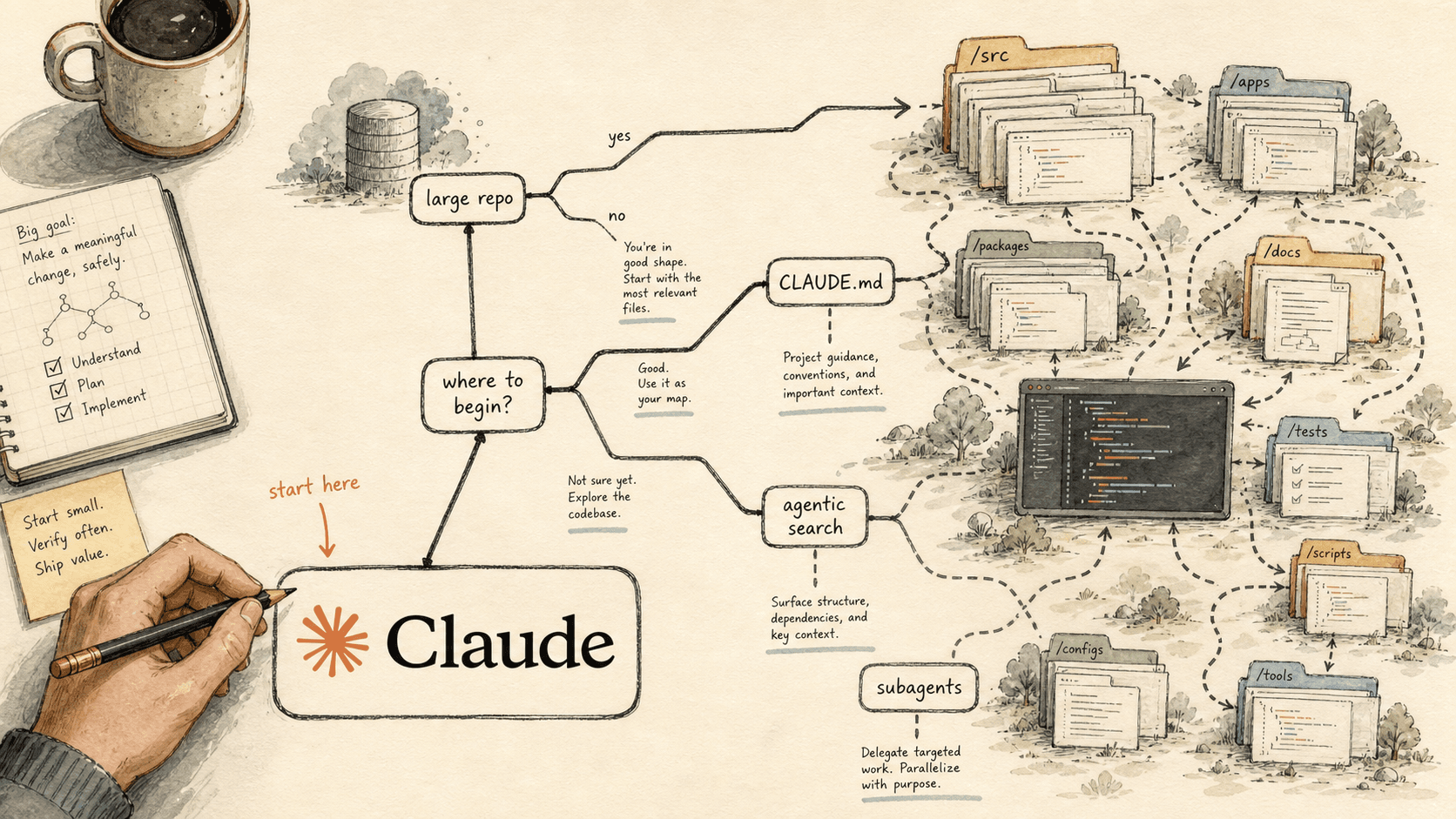
Wo Sie mit Claude Code in einem großen Repo anfangen: ein Entscheidungsbaum (2026)
Sie starten einen großen Claude-Code-Rollout nicht damit, alles zu konfigurieren. Sie starten mit dem einen Mechanismus, den Repo-Form und echter Schmerzpunkt verlangen — und ignorieren den Rest, bis Sie ihn wirklich brauchen. Das ist die Entscheidungsschicht vor dem Build.

Harness Debt: Ihr KI-Agenten-Gerüst arbeitet still gegen das Modell (2026)
Ihr KI-Agent ist wahrscheinlich schlechter als das Modell darin — und die Lücke ist Ihr eigenes Gerüst. Ein experimentelles Harness erzielte mit demselben Modell mehr als das Doppelte von Anthropics Standard-Harness. Die Lösung ist kein größeres Framework, sondern das Löschen von Annahmen, die am Tag des Claude-Opus-4.6-Release veraltet waren.

Claude Code + HTML: Der Implementierungs-Leitfaden 2026 für das richtige Output-Medium
Anthropics eigene Engineers haben Claude-Code-Outputs für fast alles auf HTML umgestellt. Die Implementierungsfrage lautet: Wann gewinnt HTML, wann nicht, und wie sollte das Handoff von Claude Design zu Claude Code wirklich aussehen?