KI-Engineering
8 Artikel
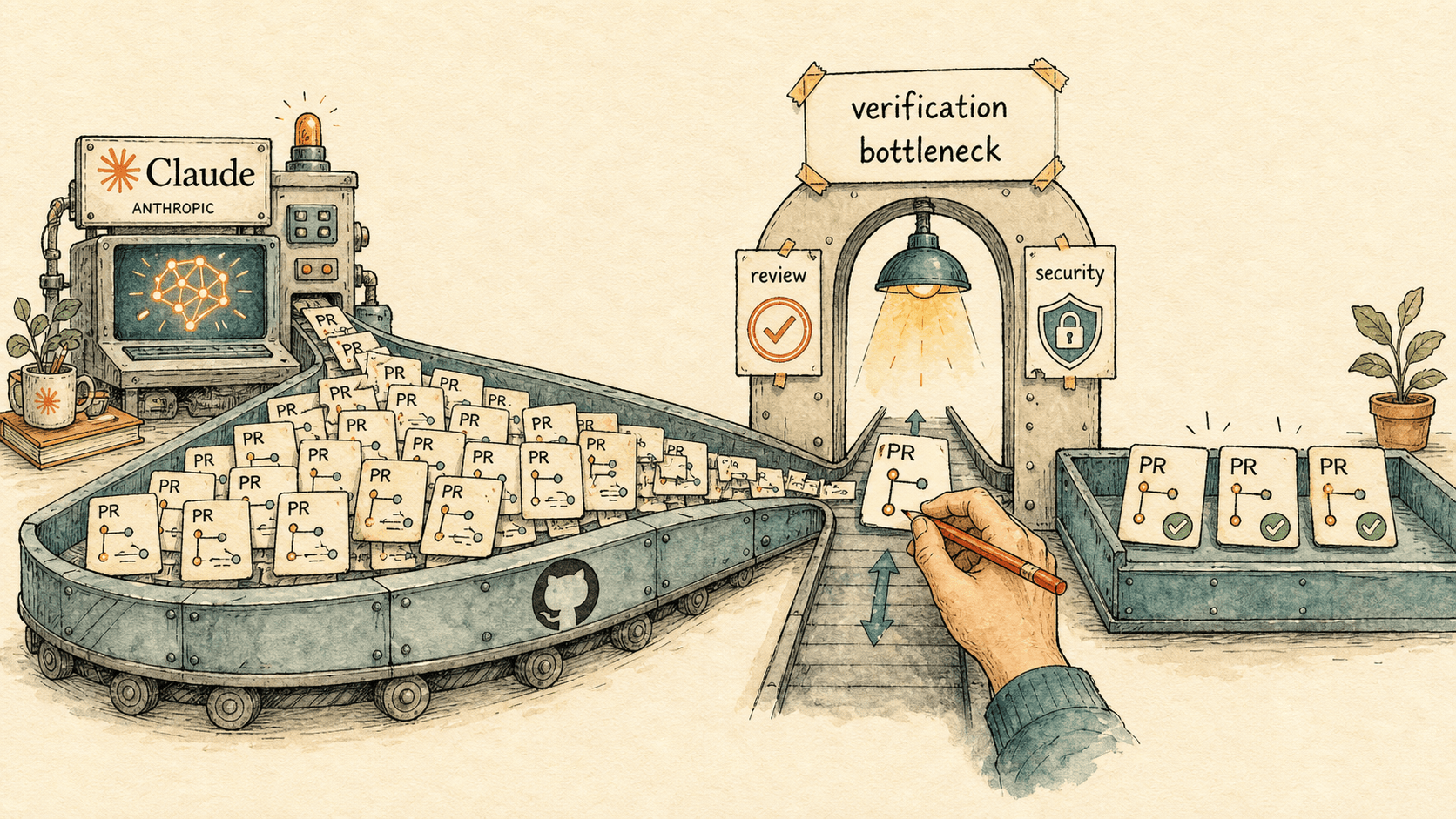
Wie man 2026 eine KI-native Engineering-Organisation führt
Agentic Coding entfernt den Engineering-Engpass nicht — er verschiebt ihn vom Schreiben des Codes zur Verifizierung. Das ist das Betriebsmodell 2026 für eine KI-native Engineering-Organisation: welche Prozesse neu geschrieben werden müssen, wie Code Review sich verändert und welche Metriken zeigen, ob es funktioniert.
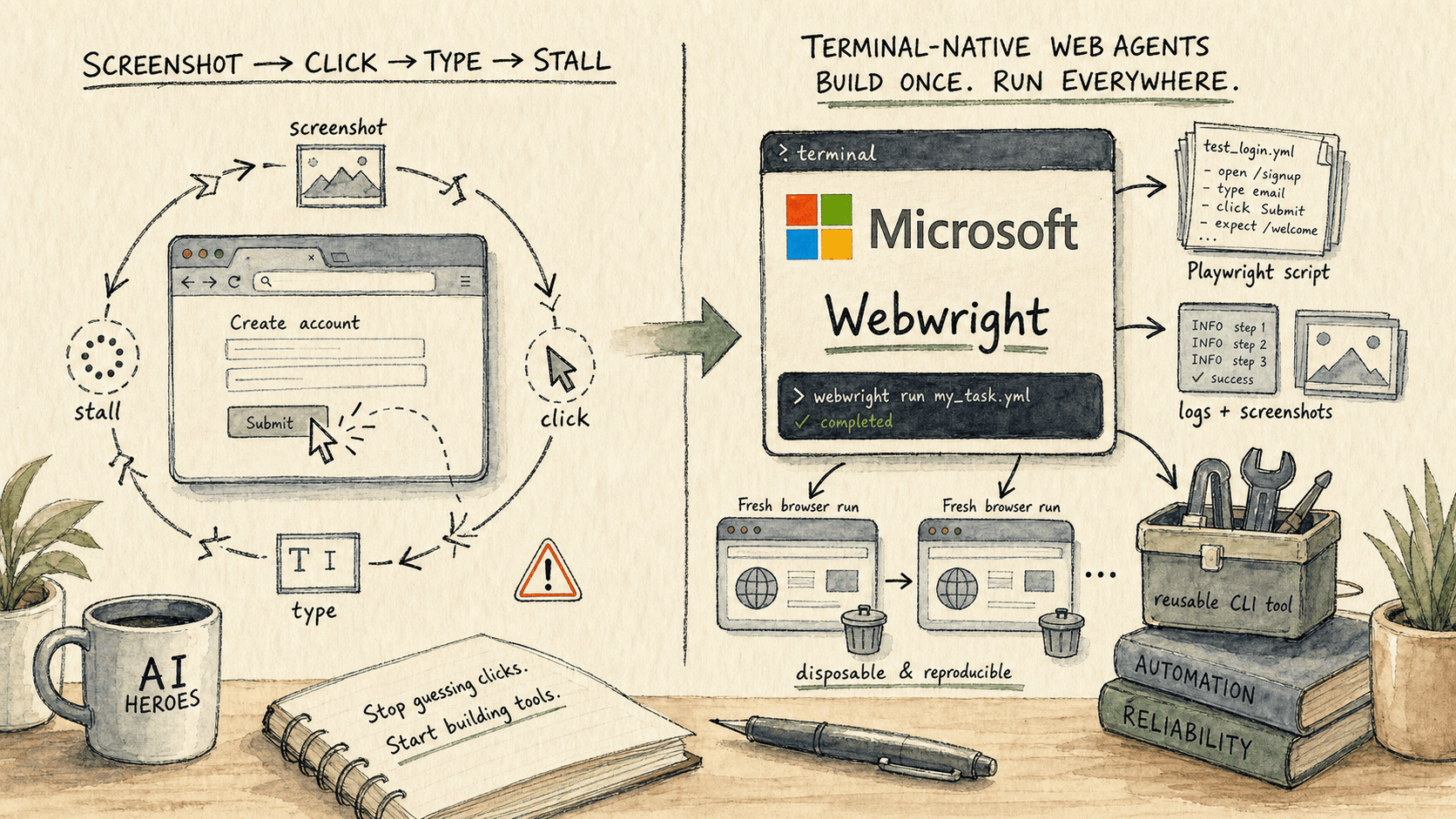
What Are Terminal-Native Web Agents? Microsoft Webwright and the End of Click-by-Click Computer Use (2026)
The next reliable web agent will not just click better. Microsoft Webwright points at the real shift: terminal-native agents that turn repeated browser work into Playwright code, logs, screenshots, fresh reruns, and reusable tools.
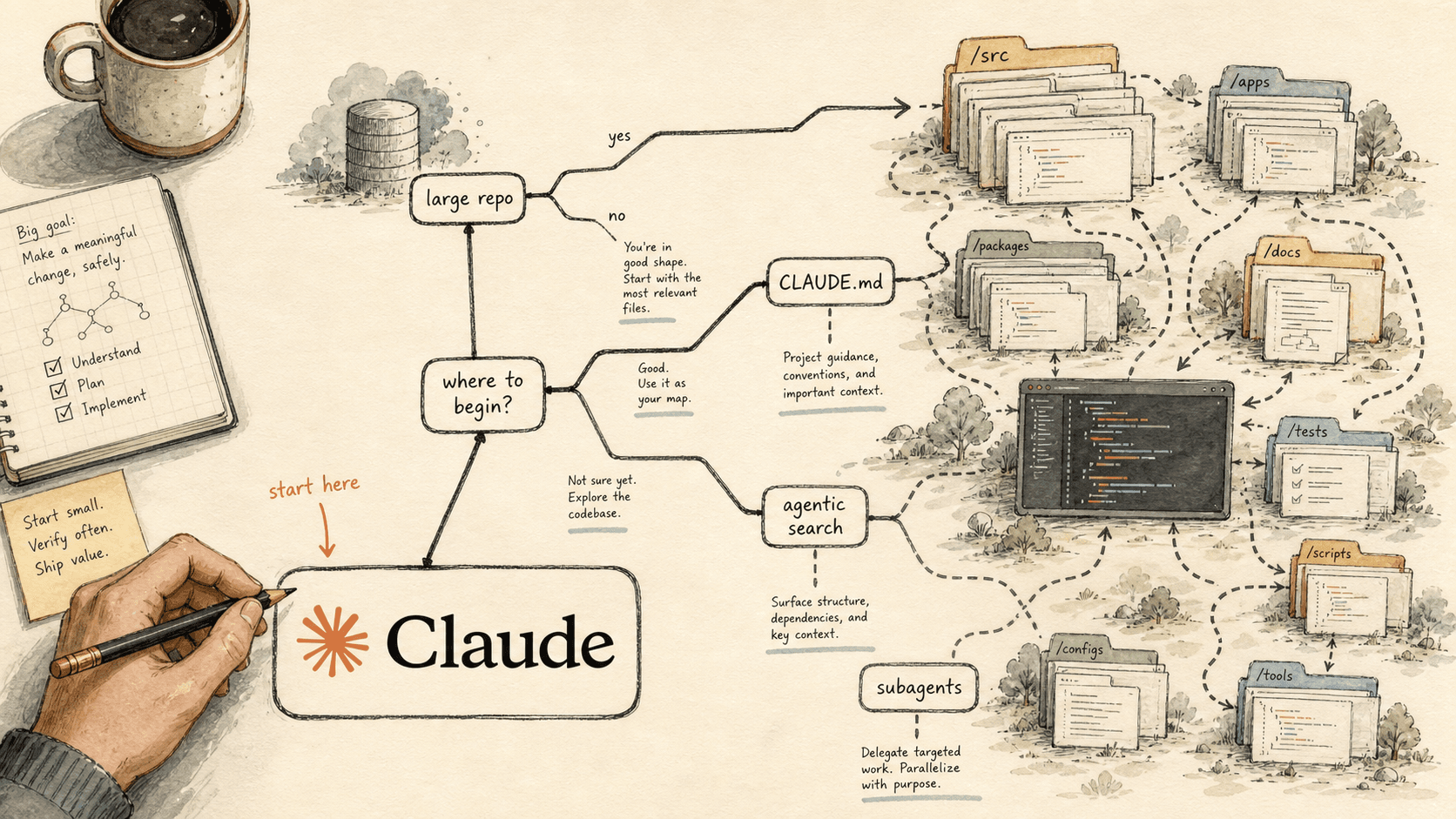
Wo Sie mit Claude Code in einem großen Repo anfangen: ein Entscheidungsbaum (2026)
Sie starten einen großen Claude-Code-Rollout nicht damit, alles zu konfigurieren. Sie starten mit dem einen Mechanismus, den Repo-Form und echter Schmerzpunkt verlangen — und ignorieren den Rest, bis Sie ihn wirklich brauchen. Das ist die Entscheidungsschicht vor dem Build.

Harness Debt: Ihr KI-Agenten-Gerüst arbeitet still gegen das Modell (2026)
Ihr KI-Agent ist wahrscheinlich schlechter als das Modell darin — und die Lücke ist Ihr eigenes Gerüst. Ein experimentelles Harness erzielte mit demselben Modell mehr als das Doppelte von Anthropics Standard-Harness. Die Lösung ist kein größeres Framework, sondern das Löschen von Annahmen, die am Tag des Claude-Opus-4.6-Release veraltet waren.
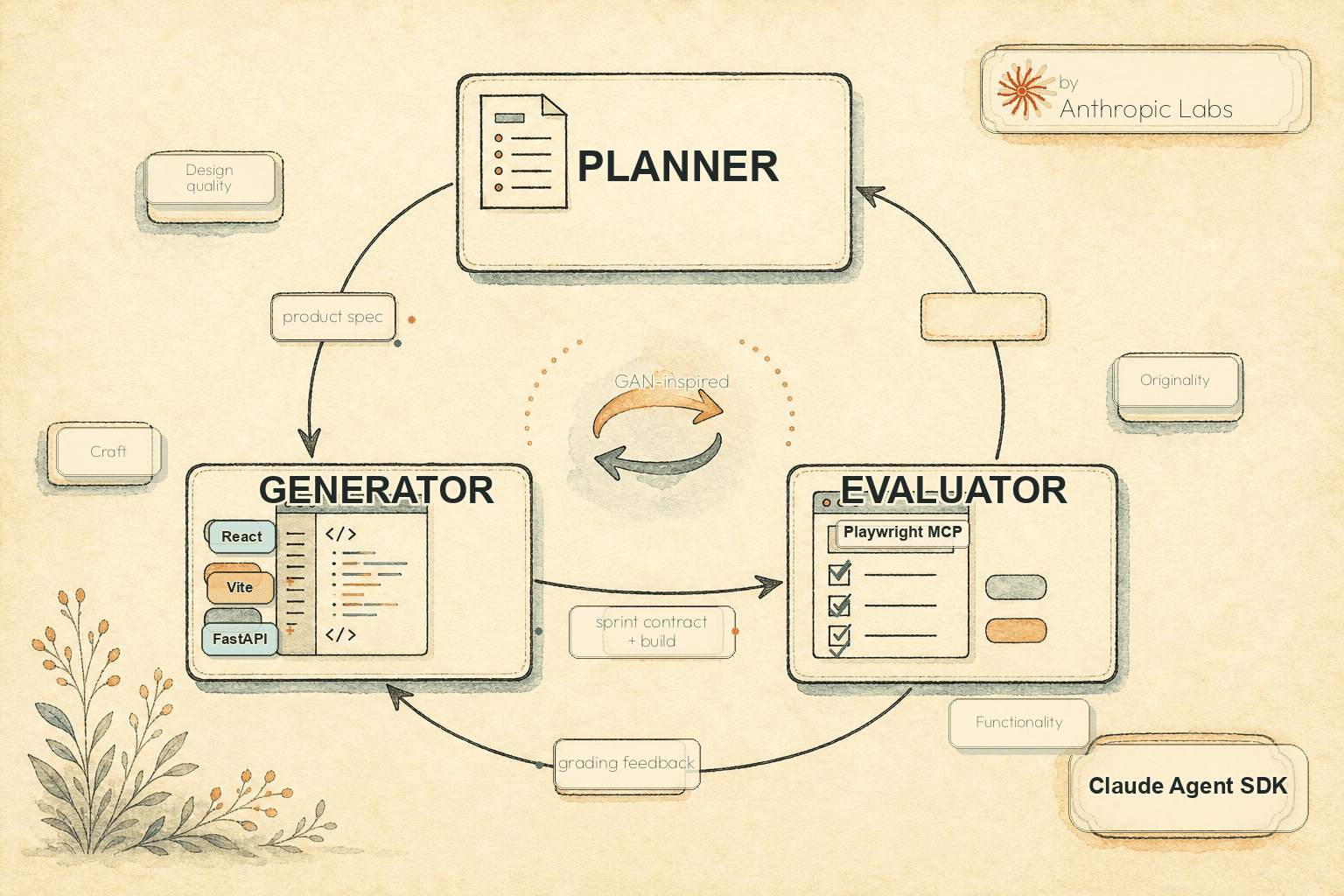
Harness Design for Long-Running AI Applications: Inside Anthropic's Generator-Evaluator Pattern (Claude Agent SDK, 2026)
On 24 March 2026 Anthropic Labs engineer Prithvi Rajasekaran published the most rigorous public account to date of how Anthropic designs harnesses for long-running AI applications — a GAN-inspired generator-evaluator pattern applied across two unusually different domains: frontend design (subjective, no binary verification) and full-stack coding (objective, machine-verifiable). The piece evolves the November 2025 Initializer + Coding Agent baseline into a three-agent planner + generator + evaluator architecture, with concrete cost-and-duration data ($200 / 6h on a retro game maker test, then $124 / 4h on a more ambitious DAW after the Opus 4.6 simplification pass). Inside the pattern, the two failure modes it fixes (context anxiety + self-evaluation bias), how it compares to LangGraph / AutoGen / OpenAI Assistants v2 / Devin, when it doesn't fit, and the canonical principle every team operating a harness should adopt: stress-test every component against the current model.

Claude Code + HTML: Der Implementierungs-Leitfaden 2026 für das richtige Output-Medium
Anthropics eigene Engineers haben Claude-Code-Outputs für fast alles auf HTML umgestellt. Die Implementierungsfrage lautet: Wann gewinnt HTML, wann nicht, und wie sollte das Handoff von Claude Design zu Claude Code wirklich aussehen?
Claude Code in großen Codebases: Der Implementierungs-Leitfaden 2026
Claude Code gewinnt in großen Codebases nicht, indem es das Repo verschlingt. Es gewinnt, wenn Sie eine Navigations- und Governance-Schicht darum herum bauen.

Wir haben Garry Tans gbrain gegen unser eigenes Agentengedächtnis getestet: 150 echte Fragen (Mai 2026)
Ein apples-to-apples Retrieval-Benchmark mit 352 Dateien und 150 Fragen zwischen gbrain und unserem bestehenden OpenClaw-qmd-Setup. gbrain gewinnt 8.3x häufiger bei harten, Cross-Source- und Diskriminierungsfragen, aber die Kernaussage ist weniger eindeutig als das Marketing.
Stay updated
Get new articles on AI implementation for business delivered to your inbox. No spam, no fluff.