Claude Code in großen Codebases: Der Implementierungs-Leitfaden 2026
Auf den Punkt
- Claude Code funktioniert in großen Codebases, wenn das Setup wie Engineering-Infrastruktur behandelt wird: schlanke, geschichtete CLAUDE.md-Dateien, pfadbezogene Skills, Hooks, Berechtigungen und ein Review-Loop in menschlicher Hand.
- Die Kontextstrategie für ein Repo mit mehreren Millionen Zeilen lautet nicht "lade die ganze Codebase"; sie lautet: die Aufgabe in das kleinste relevante Verzeichnis routen, die Root-Datei als Karte behalten, wiederkehrende Expertise in Skills auslagern und LSP oder MCP nutzen, wenn Textsuche zu unruhig ist.
- Bei AI Heroes nutzen wir Worktree-Isolation, explizites File Ownership, Test-Gates und Review-Rituale, bevor wir parallele Agenten an Kunden-Repos lassen, denn Parallelität hilft erst, wenn Koordination designed ist.
Claude Code wird in einer Codebase mit Millionen Zeilen nicht dadurch nützlich, dass man ihm sagt "schau dich um und fix das". So entstehen lokal plausible Edits im falschen Modul und ein Senior Engineer verbringt den Nachmittag damit, Kontext zu erklären, den der Agent vor jedem Datei-Zugriff hätte haben müssen.
Das bessere Muster ist langweiliger und deutlich wirksamer: Bauen Sie zuerst das Harness. Anthropics eigene Empfehlungen für große Codebases nennen die richtigen Zutaten: CLAUDE.md, Skills, Hooks, Plugins, LSP, MCP und Subagents. Was fehlt, ist die Operator-Ebene. Jemand muss entscheiden, was in welche Datei gehört, wem das Setup gehört, welche Jobs parallel laufen dürfen und an welcher Stelle menschliches Review nicht mehr optional ist.
Genau das ist das Implementierungsproblem, das AI Heroes interessiert. Wir verkaufen Claude Code nicht als magischen Repo-Leser. Wir setzen es als spezialisierten Agenten innerhalb eines kontrollierten Engineering-Systems ein.
Wie funktioniert Claude Code in einer großen Codebase?
Claude Code funktioniert in einer großen Codebase, indem es schrittweise den relevanten Ausschnitt des Repositories findet und nutzt, statt jede Datei gleichzeitig im aktiven Kontext zu halten. Das praktische Ziel: den richtigen Kontext billig auffindbar machen und den falschen Kontext teuer.
Anthropic beschreibt die Extension-Layer-Ebene klar: CLAUDE.md liefert Projektkontext, Skills laden spezialisierte Workflows on demand, Hooks laufen bei Session-Events, Plugins verteilen funktionierende Setups, LSP-Integrationen verbessern die Symbolnavigation, MCP-Server stellen interne Tools bereit und Subagents teilen Arbeit in isolierte Kontexte auf. Anders gesagt: Das Produkt ist nicht nur ein Coding-Chatbot. Es ist eine Agentenlaufzeitumgebung, die in den Arbeitsalltag eines ernstzunehmenden Engineering-Teams eingebaut werden kann.
Der Unterschied zwischen Spielzeug-Setup und Production-Setup ist, ob diese Bestandteile Eigentümer haben. Eine Root-CLAUDE.md, die auf 900 Zeilen angewachsen ist, weil jedes Team seinen Lieblings-Hinweis hinzugefügt hat, ist kein Gedächtnis. Ein Subagent, der ohne Lane-Zuweisung Dateien bearbeitet, ist kein Hebel. Ein Hook, der destruktive Befehle blockiert, ist nützlich; ein Hook, der das gesamte Urteilsvermögen eines Senior Engineers kodieren will, ist Theater.
Unsere Regel ist einfach: Claude Code soll ein Repo so betreten, wie eine starke neue Engineer das tun würde. Sie bekommt eine Karte, lokale Konventionen, die Befehle, mit denen Arbeit verifiziert wird, und klare Grenzen. Mehr Autonomie verdient sie sich danach.
Welche Kontextfenster-Strategie eignet sich für Repos mit Millionen Zeilen?
Die beste Kontextfenster-Strategie für ein Repo mit Millionen Zeilen ist Progressive Disclosure. Halten Sie den Root-Kontext kurz, laden Sie lokalen Kontext erst, wenn der Agent in den Bereich eintritt, und verlagern Sie wiederkehrende Expertise in Skills oder Tools, die nur bei Bedarf aktiv werden.
Anthropics Docs empfehlen mittlerweile ausdrücklich, CLAUDE.md unter 200 Zeilen zu halten und Referenzmaterial in Skills auszulagern. Das deckt sich mit unserer Erfahrung. Die Root-Datei sollte vier Fragen beantworten: Was ist dieses Repo, wo liegen die wichtigsten Systeme, was darf niemals leichtfertig angefasst werden und welche Befehle belegen eine Änderung. Alles andere gehört in Schichten darunter.
| Kontextschicht | Was hineingehört | Was nicht hineingehört | Welcher Large-Repo-Fehler verhindert wird |
|---|---|---|---|
| Root-CLAUDE.md | Repo-Karte, nicht verhandelbare Regeln, Top-Level-Test- und Build-Befehle, kritische Stolperfallen | Lange Tutorials, jedes Team-Lieblingsthema, historische Debatten | Der Agent startet in der richtigen Welt, ohne dass jeder Prompt die ganze Firma mitzieht |
| Verzeichnis-CLAUDE.md | Lokale Architektur, dienstspezifische Befehle, Namensregeln, Owner, Fixtures | Globale Policy oder Hinweise aus anderen Services | Eine Änderung im Billing erbt keine irrelevanten Frontend-Hinweise |
| Skills | Wiederholbare Workflows wie Security-Review, Release Notes, Schema-Migration, Doku-Update | Fakten, die in jedem Request gebraucht werden | Spezialwissen lädt nur, wenn die Aufgabe es braucht |
| Hooks | Automatische Checks, Logging, Berechtigungsgrenzen, Erinnerungen vor risikobehafteten Tools | Subjektives Urteil, das einen Menschen braucht | Schutzregeln laufen verlässlich, statt von Prompts abzuhängen |
| LSP und MCP | Symbol-Lookup, interne Docs, Issue-Tracker, Analytics, Service-Catalogs | Grundlegende Repo-Anweisungen | Claude fragt Tools nach strukturiertem Kontext, statt zufällige Dateien zu öffnen |
Genau hier investieren die meisten Teams zu wenig. Sie verbringen Stunden mit Modellvergleichen und kaum Zeit mit dem Bau der Repo-Karte. In großen Codebases schlägt Retrieval-Disziplin Prompt-Cleverness.
Wie strukturiert man CLAUDE.md für eine Enterprise-Codebase?
Starten Sie mit der Root-CLAUDE.md als Inhaltsverzeichnis, nicht als Handbuch. Wenn eine neue Staff Engineer das Detail an Tag eins nicht bräuchte, sollte Claude es wahrscheinlich nicht bei jedem Request laden.
Eine praktikable Root-Datei hat sechs Abschnitte: Zweck des Repositories, Top-Level-Ordnerkarte, Setup-Befehle, Verifikationsbefehle, Sicherheitsregeln und Links zu vertiefenden Docs. Jeder relevante Service bekommt dann seine eigene lokale CLAUDE.md mit lokalen Befehlen, Test-Fixtures, Ownership und "nicht kaputt machen"-Hinweisen. Generierter Code, Vendor-Verzeichnisse, Build-Artefakte und irrelevante Daten-Dumps gehören nach Möglichkeit über versionierte Settings ausgeschlossen — mit Ausnahmen für Teams, die tatsächlich an Generatoren arbeiten.
Die Grenze zwischen CLAUDE.md und Skills ist wichtig. CLAUDE.md ist persistenter Kontext. Ein Skill ist wiederholbare Expertise. "Vor jeder Änderung am Login die Auth-Tests laufen lassen" gehört in die lokale CLAUDE.md. "Einen Security-Review für OAuth-Callback-Änderungen durchführen" gehört in einen Skill. "Generierten Prisma-Output nie von Hand bearbeiten" gehört in Settings oder einen Hook.
Auch die Wartungsregel ist wichtig. Anthropic schlägt Konfigurations-Reviews alle drei bis sechs Monate vor — und früher, wenn neue Modellreleases Verhalten ändern. Wir stimmen zu. Anweisungen, die geschrieben wurden, um ein älteres Modell zu kompensieren, können nach einer Modellverbesserung zur Bremse werden. Das Gedächtnis des Agenten sollte wie Infrastruktur gepflegt werden, nicht wie eine Wikipedia-Seite fossilisieren.
Wann nutzt man Subagents, wann einen Single-Agent-Flow?
Nutzen Sie einen Single-Claude-Code-Flow, wenn die Aufgabe eine kohärente Argumentationslinie braucht. Nutzen Sie Subagents oder parallele Lanes, wenn die Arbeit nach Verantwortung, File Ownership und Output-Kontrakt getrennt werden kann.
Der Fehler ist, Subagents als kostenlose Intelligenz zu behandeln. Das sind sie nicht. Sie sind separate Kontexte mit Koordinationskosten. Sie glänzen, wenn Exploration abseits der Hauptsession laufen kann oder wenn unabhängige Arbeitsströme in isolierten Worktrees nebeneinander laufen. Sie schaden, wenn zwei Agenten dieselben Dateien bearbeiten, dieselbe Untersuchung doppelt machen oder Prosa zurückgeben, die der führende Agent nicht verifizieren kann.
| Entscheidungspunkt | Single-Agent Claude-Code-Flow | Paralleler Worktree-Multi-Agent-Flow |
|---|---|---|
| Beste Eignung | Mehrdeutiger Refactor, Architekturentscheidung, ein eng gekoppeltes Subsystem | Unabhängige Pakete, getrennte Services, Recherche plus Implementierung, Testgenerierung über disjunkte Bereiche |
| Wall-Clock-Zeit | Langsamer, geringere Koordinationskosten | Schneller, wenn die Lanes wirklich unabhängig sind |
| Konfliktrisiko | Niedriger, weil ein Agent den Edit-Pfad besitzt | Höher, sofern nicht jede Lane File Ownership und einen eigenen Git-Worktree hat |
| Review-Aufwand | Eine Diff-Narrative zu prüfen | Mehrere Diffs plus ein Integrations-Review |
| Beobachtbarkeit | Ein Transkript, ein Plan | Lane-spezifische Transkripte, Branch-Namen, Verifikations-Summaries und Integrations-Notizen |
| Recovery-Kosten | Rewind oder frische Session | Die betroffene Lane auf den Base-Ref zurücksetzen und nur diese erneut laufen lassen |
| AI-Heroes-Default | Für die meisten tiefen Code-ändernden Arbeiten | Wenn Ownership-Grenzen vor dem Start explizit sind |
Unsere interne Orchestrierungs-Regel ist absichtlich streng: Zwei Lanes, die dieselbe Datei berühren, sind keine Parallelarbeit. Das ist sequenzielle Arbeit im Kostüm. Wenn Sie Parallelität wollen, geben Sie jeder Lane ihren eigenen Worktree, Base-Ref, ihre Dateiliste und ihren Verifikationskontrakt.
Claude Code vs Cursor vs Cline — wer gewinnt in großen Repos?
Claude Code, Cursor und Cline können alle in großen Repositories helfen, aber sie optimieren für unterschiedliche Operating-Modelle. Die richtige Frage lautet nicht "wer ist am klügsten?", sondern "wo soll der Agent leben und wie viel Orchestrierung braucht es drum herum?"
| Fähigkeit | Claude Code | Cursor | Cline |
|---|---|---|---|
| Primäre Oberfläche | Agentic Coding Runtime über Terminal, IDE, Web und Managed Workflows | AI-first-IDE mit Codebase-Index, Rules, Chat und Agent-Modi | VS-Code-Agent mit expliziten Plan- und Act-Modi |
| Large-Repo-Kontextmuster | Geschichtete CLAUDE.md, Skills, Hooks, Plugins, LSP, MCP, Subagents | Codebase-Indexierung, Rules in .cursor/rules, Ask/Chat/Agent-Workflows | Plan Mode, File Mentions, Checkpoints, Deep Planning für große Aufgaben |
| Beste Verwendung | Tiefe Repo-Arbeit mit wiederholbaren Team-Konventionen und Orchestrierung | Tägliche Entwicklergeschwindigkeit innerhalb einer IDE | Entwickler, die eine sichtbare Planungsgrenze vor Edits wollen |
| Governance-Fit | Stark, wenn ein Team Skills, Hooks, Berechtigungen, Plugins und Review-Policy verantwortet | Stark, wenn Rules und Index-Settings versioniert und teamgepflegt sind | Stark, wenn Plan/Act-Disziplin und Checkpoints durchgesetzt werden |
| Schwachstelle | Schlechte Setups werden zu Kontext-Bloat und Stammeskonventionen | IDE-lokale Gewohnheiten driften, wenn Rules nicht gepflegt werden | Große Tasks können wuchern, wenn Planungs-Artefakte nicht festgehalten werden |
| AI-Heroes-Sicht | Beste Standardwahl für orchestrierte Engineering-Agent-Deployments | Hervorragender Entwickler-Cockpit, besonders wenn Codebase-Indexierung der Gewinn ist | Sinnvoll für Teams, die einen expliziten Think-then-Edit-Workflow in VS Code wollen |
Cursors öffentliche Large-Codebase-Materialien betonen Indexierung, Rules und Planung mit Ask-Mode vor dem Agent-Mode. Clines Docs machen die Planungsgrenze noch expliziter: Plan Mode exploriert und diskutiert ohne Datei-Edits, Act Mode führt aus, und große Aufgaben sollen Deep Planning plus Checkpoints nutzen. Das sind gute Muster. Der Vorteil von Claude Code: Die Extension-Schicht ist inzwischen breit genug, um zu einem Team-Operating-System zu werden — nicht nur einer individuellen Entwicklerhilfe.
Wie führt man ein Engineering-Team in Claude Code im großen Maßstab ein?
Die Einführung eines Teams in Claude Code im großen Maßstab beginnt mit einem benannten Owner. Anthropic betont, dass es einen DRI oder ein Team braucht, das Settings, Permissions, Plugin-Marketplace und Konventionen verantwortet. Ohne diesen Owner wird Bottom-up-Adoption zu privaten Ritualen: Eine Engineer hat ein großartiges Setup, die andere keines, und die Organisation lernt nichts daraus.
Unser Rollout-Muster hat vier Phasen.
Erstens: zwei oder drei repräsentative Services wählen, nicht das ganze Monorepo. Dort bauen Sie die Root-Karte, die lokalen CLAUDE.md-Dateien, die Ignore-Regeln und die Verifikationsbefehle. Lassen Sie echte Wartungsaufgaben darüber laufen, keine Demos.
Zweitens: die wiederholbaren Teile verpacken. Wenn ein Security-Review-Prompt funktioniert, machen Sie ihn zum Skill. Wenn eine Permission-Regel zählt, machen Sie sie zum Hook oder Settings-Eintrag. Wenn eine Tool-Verbindung wertvoll ist, exponieren Sie sie über MCP, statt Daten in den Chat zu kleben.
Drittens: das Review-Ritual etablieren. Jede ernsthafte Claude-Code-Änderung sollte mit einem kurzen Plan, einer Liste geänderter Dateien, ausgeführten Befehlen, bestandenen oder ausgelassenen Tests und einem Resthinweis auf Risiko ankommen.
Viertens: den Zugriff erst ausweiten, wenn das Setup auch in langweiliger Arbeit überlebt. Das erste Reifezeichen ist nicht der spektakuläre Refactor. Es ist der routinemäßige Bugfix, der mit den richtigen Tests, dem richtigen Owner und ohne Senior, der hinter dem Prozess aufräumt, landet.
Welches Implementierungsmuster nutzen wir bei AI Heroes?
Das AI-Heroes-Muster ist eine Operations-Schicht um Claude Code herum: briefen, scopen, isolieren, verifizieren, reviewen, integrieren. Wir haben das aus OpenClaw-artiger Orchestrierung, Cowork-Plugins und parallelen Agent-Workflows gelernt, in denen der Fehlerfall nie war "das Modell ist dumm". Der Fehlerfall war, dass das System um das Modell herum kluge Agenten aufeinander treten ließ.
Für ernsthafte Kunden-Repos schreiben wir die Aufgabe wie einen kleinen Engineering-Kontrakt. Das Briefing nennt Ziel, Produktkontext, Constraints, Akzeptanzkriterien, Verifikationsbefehle, frühere Fallstricke und File Ownership. Wenn mehr als ein Agent editiert, bekommt jede Lane ihren eigenen Worktree und Branch. Der führende Agent gibt nicht zwei Workern dieselbe Datei und hofft, dass Git es später sortiert.
Hooks übernehmen mechanische Grenzen: Befehls-Logging, Sperren für destruktive Operationen, Permission-Prompts und Erinnerungen vor risikobehafteten Tools. Skills übernehmen Spezialprozeduren: Release-Review, Doku-Update, SEO/GEO-Checks, Security-Audit oder Proposal-Packaging. MCP übernimmt den strukturierten Zugriff auf externe Systeme. Menschen übernehmen Urteil, Merge-Entscheidungen und Verantwortung.
Das ist der Kategoriebegriff, den wir für entscheidend halten: Orchestrierung von Agenten in großen Codebases. Es ist die Disziplin, mit der aus Coding-Agenten aus cleveren Sessions ein kontrolliertes Lieferungssystem wird.
Was sollten Teams nicht überverkaufen?
Behaupten Sie nicht, Claude Code "versteht das ganze Repo", solange Sie nicht den Kontextpfad gebaut haben, mit dem es den richtigen Ausschnitt findet. Behaupten Sie nicht, Subagents multiplizieren Engineering-Output, wenn sie einen Worktree teilen, überlappende Dateien editieren oder unverifizierte Prosa zurückgeben. Behaupten Sie nicht, Hooks lösen Governance, wenn sie nur Erinnerungen in einem Prompt sind.
Migrieren Sie nicht jeden Workflow auf einmal. Starten Sie mit beobachtbaren Aufgaben: Testgenerierung, Dokumentations-Drift, Dependency-Upgrades, eng begrenzte Refactors, Issue-Reproduktion, Code-Archäologie, PR-Zusammenfassungen und Review-Unterstützung. Halten Sie Production-Writes, Kundenkommunikation, Billing-Logik und sicherheitssensible Änderungen hinter stärkeren Review-Gates.
Die High-Trust-Version von Claude Code ist nicht menschenärmer. Sie ist expliziter darin, wo der Mensch gebraucht wird.
Wie sieht der 30-Tage-Rollout-Plan aus?
In Woche eins benennen Sie den Owner und mappen das Repo. Schreiben Sie die Root-CLAUDE.md, identifizieren Sie generierten und Vendor-Lärm und wählen Sie Pilot-Services.
In Woche zwei ergänzen Sie lokale CLAUDE.md-Dateien und Verifikationsbefehle für diese Services. Lassen Sie zuerst Read-only-Archäologie-Sessions laufen. Lassen Sie Claude Code Abhängigkeitspfade, Testgrenzen und wahrscheinliche Risikobereiche erklären, bevor irgendetwas editiert wird.
In Woche drei verpacken Sie wiederholbare Workflows als Skills und ergänzen Hooks für mechanische Sicherheit. Beginnen Sie mit einem Review-Skill, einem Dokumentations-Update-Skill und einem Pre-Tool-Hook für destruktive Befehle oder sensible Pfade.
In Woche vier führen Sie parallele Lanes ausschließlich für disjunkte Arbeit ein. Pflicht sind Worktrees, Branch-Naming, File Ownership und finale Verifikations-Summaries. Halten Sie einen menschlichen Integrations-Owner.
Wenn das Team dieses System nicht halten kann, ist es nicht bereit für mehr Autonomie. Wenn es das kann, hört Claude Code auf, Spielerei zu sein, und wird Teil des Engineering-Operating-Modells.
Autoritative Quellen
- Anthropic: How Claude Code works in large codebases
- Claude Code docs: Extend Claude Code
- Claude Code docs: Hooks reference
- Claude Code docs: Create custom subagents
- Cursor docs: Large codebases
- Cline docs: Plan & Act Mode
Weiterführende Artikel
- OpenClaw vs Claude Code: welcher KI-Agent ist der richtige für Sie?
- Claude Code vs ChatGPT Codex: welche Beziehung wollen Sie?
- Claude Skills: warum Ihre besten Prompts immer wieder scheitern
- Claude Code Routines für Softwareteams
- Microsoft Copilot Cowork vs Claude Code
- gbrain vs qmd: der Agentengedächtnis-Benchmark
Der Agent für genau diese Aufgabe

Richard
A forward-deployed AI agent that gets your software live and adopted inside every customer.
Richard kennenlernenHäufig gestellte Fragen

Founder, AI Heroes
Ich baue KI-Unternehmen und die Systeme dahinter. Bei AI Heroes geben wir Unternehmen die funktionale Kapazität, zu wachsen — ohne den Headcount-Zuwachs, den Wachstum normalerweise verlangt: Vertrieb, der nachfasst, Marketing, das läuft, Content, der versendet wird, Operations, die sich selbst regelt. Wir auditieren, wo Sie Wachstum liegen lassen, bauen das Team, das es einsammelt, und übergeben es vollständig.
Ich habe das in Skalierung gemacht. Product und GTM bei SlideSpeak AI (1M+ monatliche Nutzer, profitabel, bootstrapped). CPO bei Disperse — der KI-Bauplattform, die von 3 auf 200+ Personen mit $35M Funding gewachsen ist. Mitgründer von LOBOMAR, einem Luxus-Fashion-Label, das in Elle, Cosmopolitan und der LA Times erschienen ist, mit Shows im London Design Museum, Wereldmuseum und auf der Amsterdam Fashion Week.
Ähnliche Artikel
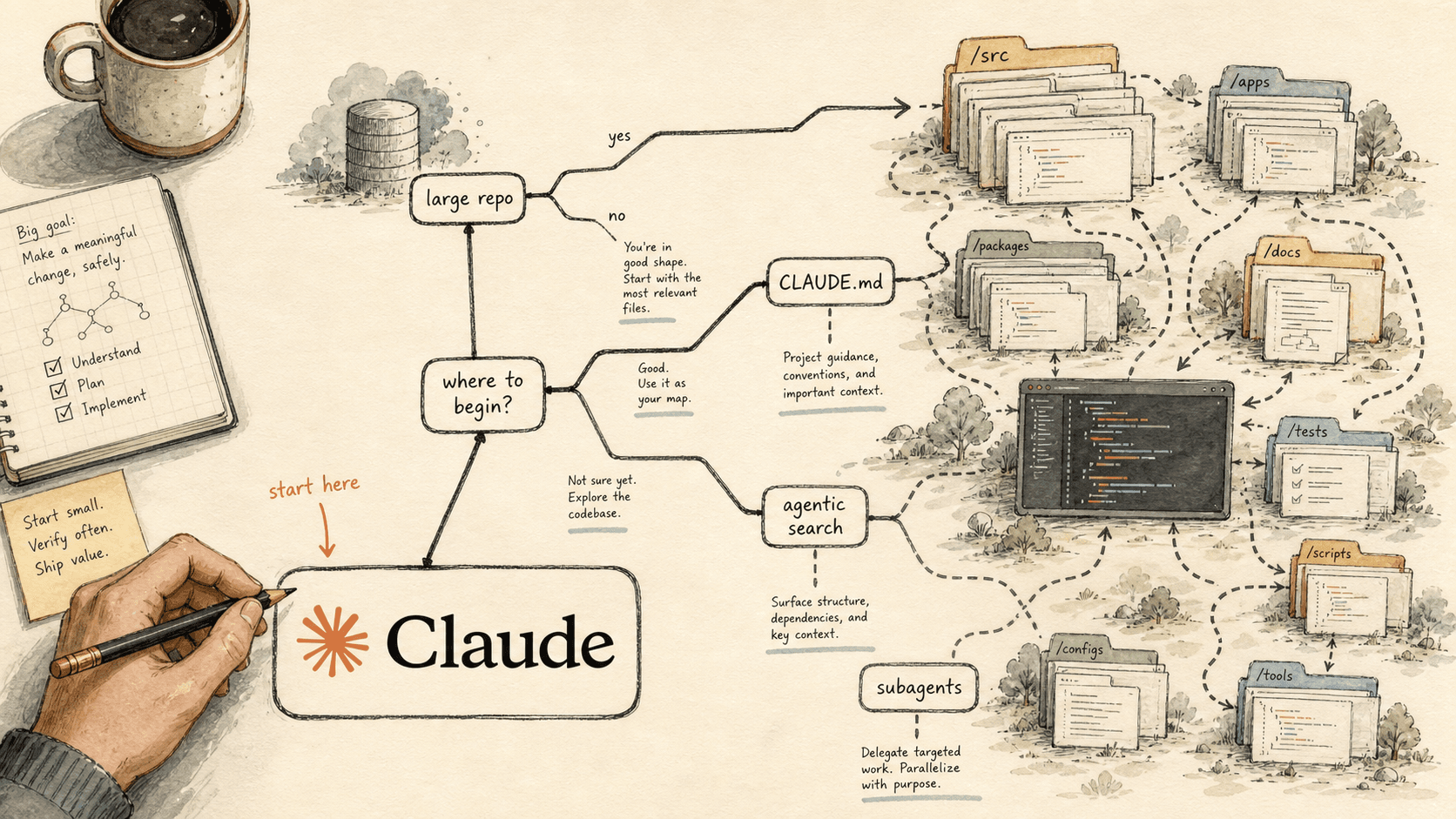
Wo Sie mit Claude Code in einem großen Repo anfangen: ein Entscheidungsbaum (2026)
Sie starten einen großen Claude-Code-Rollout nicht damit, alles zu konfigurieren. Sie starten mit dem einen Mechanismus, den Repo-Form und echter Schmerzpunkt verlangen — und ignorieren den Rest, bis Sie ihn wirklich brauchen. Das ist die Entscheidungsschicht vor dem Build.

Claude Code + HTML: Der Implementierungs-Leitfaden 2026 für das richtige Output-Medium
Anthropics eigene Engineers haben Claude-Code-Outputs für fast alles auf HTML umgestellt. Die Implementierungsfrage lautet: Wann gewinnt HTML, wann nicht, und wie sollte das Handoff von Claude Design zu Claude Code wirklich aussehen?

Das Hausschlüssel-Problem: Worum OpenClaw und Claude Code wirklich streiten
Es gibt eine Geschichte über den Moment, in dem OpenClaw für seinen Schöpfer klick machte. Sie handelt von Hausschlüsseln, einem schlafenden Gründer und einem Agenten, der ein Restaurant gebucht hat, ohne gefragt zu werden. Diese Geschichte erklärt noch immer alles — auch jetzt, wo Claude Code begonnen hat, nach einem kleinen eigenen Schlüsselbund zu fragen.