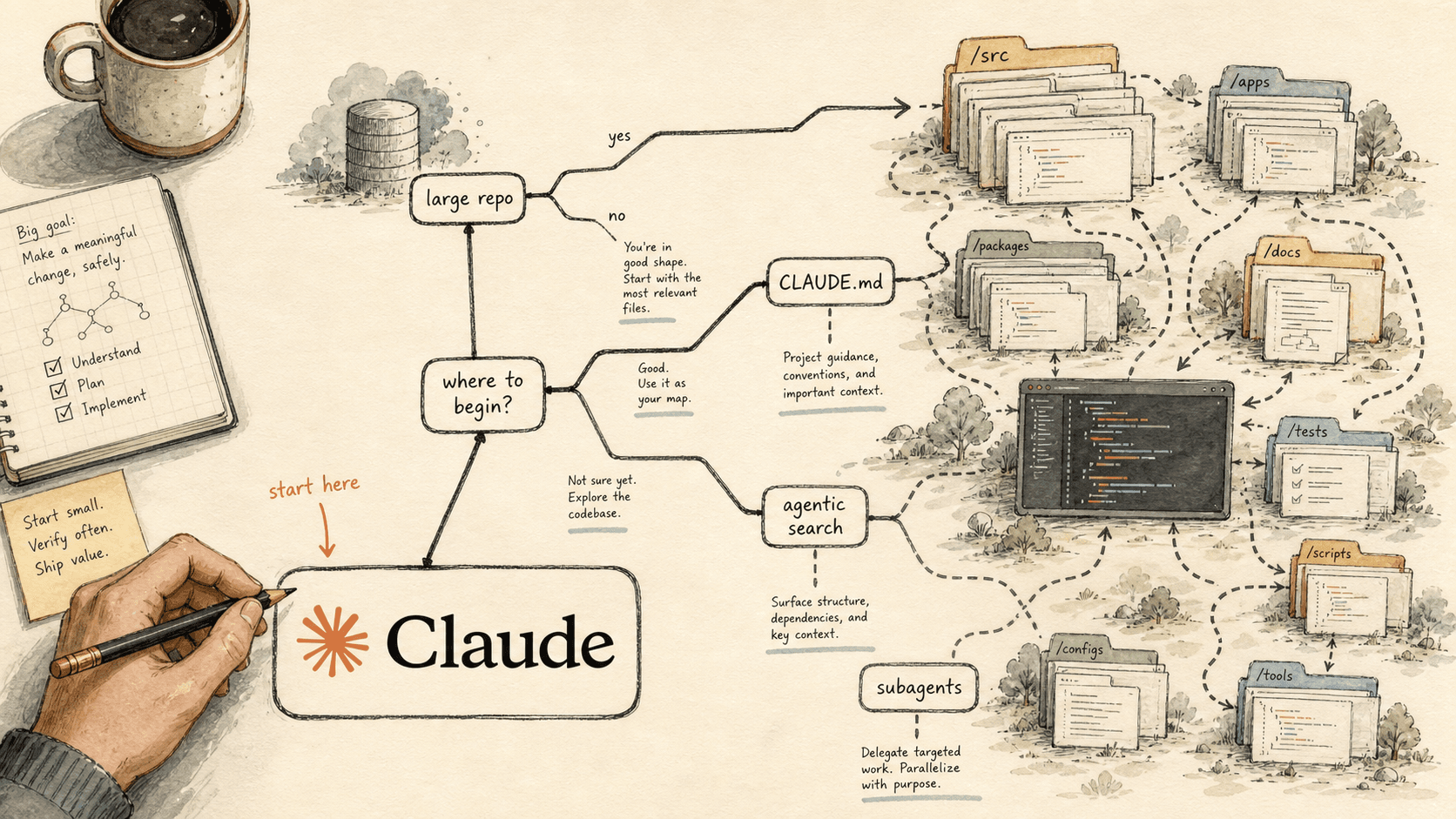
Wo Sie mit Claude Code in einem großen Repo anfangen: ein Entscheidungsbaum (2026)
Auf den Punkt
- Die erste Entscheidung in einem großen Claude-Code-Setup lautet nicht, welche Features Sie einschalten — sondern welchen einen Mechanismus Ihre Repo-Form und Ihr Schmerzpunkt zuerst verlangen. Konfigurieren Sie genau diesen, liefern Sie ihn aus, und ergänzen Sie den nächsten erst, wenn sein Trigger auftaucht.
- Der Grund, warum Sie schmal starten können, ist agentic search: Claude Code erkundet ein Repo bei Bedarf, indem es Dateien durchläuft und grep nutzt — ohne Embedding-Index, den Sie bauen oder aktuell halten müssen. Repo-Größe erzwingt die Setup-Entscheidung nicht; Repo-Form und Ihr tatsächlicher Fehlerfall tun es.
- Nutzen Sie die Entscheidungstabelle unten, um "mein Repo ist X / mein Schmerz ist Y" auf einen Startmechanismus zu mappen — gescoptes
CLAUDE.md, einen Subagent, agentic search oder eine/compact-gegen-frisch-Policy — und bauen Sie ihn danach mit dem verlinkten Implementierungsleitfaden.
Die meisten Teams, die Claude Code auf einem ernsthaften Repository einführen, versuchen alles gleichzeitig zu konfigurieren — ein Root-CLAUDE.md, verschachtelte Dateien, Skills, Hooks, Subagents, MCP — und enden mit einer großen Oberfläche, die sie nicht verstehen und nicht debuggen können. Der schnellere Weg ist, zu entscheiden, welchen einen Mechanismus Ihre Situation zuerst braucht, ihn aufzusetzen und den Rest liegenzulassen, bis ein konkretes Symptom ihn erzwingt.
Anthropics Applied-AI-Team hat beschrieben, wie es Claude Code produktiv "across multi-million-line monorepos, decades-old legacy systems, distributed architectures spanning dozens of repositories, and at organizations with thousands of developers" nutzt. Der nützliche Teil für jemanden, der an einem Montag vor einem großen Repo sitzt, ist nicht die Größenbehauptung. Es ist die Einsicht, dass der richtige Startpunkt von der Repo-Form abhängt, nicht von der Zeilenzahl. Das hier ist die Entscheidungsschicht; im Implementierungsleitfaden wird sie gebaut.
Wie entscheiden Sie, wo Sie mit Claude Code in einem großen Repo anfangen?
Starten Sie, indem Sie Repo-Form und den einen schmerzhaftesten Fehler auf einen Mechanismus mappen — nicht, indem Sie Features der Reihe nach aktivieren. Die Nützlichkeit von Claude Code in einer großen Codebase ist, in Anthropics Worten, "bounded by its ability to find the right context", und der Fehler schneidet in beide Richtungen: "Too much context loaded into every session degrades performance, while too little context leaves Claude to navigate blind." Der Startzug ist also immer der, der Ihre Seite dieses Ungleichgewichts korrigiert.
Finden Sie die Zeile, die zu Ihrer Situation passt, starten Sie dort, und behandeln Sie jeden anderen Mechanismus als späteren Schritt, der erst durch ein konkretes Symptom ausgelöst wird.
| Ihre Situation | Starten Sie hier | Warum (der Mechanismus) |
|---|---|---|
| Großes Monorepo, viele Services, Root-Konfiguration fühlt sich falsch an | Gescopektes CLAUDE.md in Unterverzeichnissen, nicht nur im Root | Claude "walks up the directory tree and loads every CLAUDE.md file it finds" und hängt Root→cwd zusammen; lokaler Kontext kommt dazu, ohne Root-Kontext zu verlieren. |
| Ein riesiges Repo, Sessions fühlen sich ab dem ersten Prompt langsam oder vage an | Schlankes Root-CLAUDE.md (nur Pointer + Gotchas, unter etwa 200 Zeilen) | Ein aufgeblähtes Kontextfile senkt Adherence — "Claude ignores half of it because important rules get lost in the noise." Schlanker Kontext ist der günstigste erste Gewinn. |
| Untersuchungsaufgaben sprengen die Session (Hunderte Dateien gelesen) | Ein Subagent für Exploration | Ein Subagent läuft in "its own context window" und "returns only the summary"; die Explorationskosten verschmutzen den Hauptthread nicht. |
| Sie diskutieren, ob Sie für "Search" einen Vector Index anschrauben sollen | Erst auf eingebaute agentic search setzen | Agentic search hat "no embedding pipeline or centralized index to maintain" und vermeidet Index-Staleness — ergänzen Sie eine Search-Sidecar nur bei gemessener Token- oder Latenzwand. |
| Lange Sessions laufen mitten in der Aufgabe ins Kontextlimit | Eine /compact-gegen-/clear-Policy | Was /compact überlebt, ist regelgebunden (siehe Survival-Tabelle unten); zu entscheiden, wann kompaktieren statt frisch starten, verhindert stillen Kontextverlust. |
| Hunderttausende Ordner / Millionen Dateien oder Nicht-Git-VCS | Stoppen und als Edge Case behandeln | Anthropic räumt ein, dass "even the hierarchical CLAUDE.md approach breaks down" — das liegt außerhalb der Annahmen eines konventionellen Repos. |
Ein Hinweis vor den Branches: Die Tokenzahlen, mit denen Anthropic Kontextkosten illustriert (ein 200.000-Token-Fenster, ein Subagent, der 6.100 Tokens liest und 420 zurückgibt), sind in der eigenen Darstellung ausdrücklich representative — nützlich für Intuition, keine Produktionskonstanten.
Wohin sollten Sie Claude Code in einem großen Repo zuerst zeigen lassen?
Zeigen Sie auf das kleinste Verzeichnis, das Ihre Aufgabe enthält, und lassen Sie Claude Code nach oben zum Root laufen — starten Sie nicht standardmäßig im Repo-Root. Das ist der kontraintuitivste erste Zug, weil "tooling often assumes root access", wie Anthropic schreibt. Claude Code braucht das nicht: "Claude automatically walks up the directory tree and loads every CLAUDE.md file it finds along the way, so root-level context is never lost."
Die Memory-Dokumentation von Claude Code beschreibt den Ladealgorithmus präzise: CLAUDE.md-Dateien werden "by walking up the directory tree from your current working directory" gelesen, alle gefundenen Dateien werden "concatenated into context rather than overriding each other", und der Inhalt wird "ordered from the filesystem root down to your working directory". Subdirectory-Dateien werden beim Start nicht geladen — sie werden "included when Claude reads files in those subdirectories".
Die Startentscheidung für ein Monorepo lautet also: Legen Sie in jedes große Service-Verzeichnis ein CLAUDE.md, halten Sie das Root-File als dünne Karte, und starten Sie Sessions in dem Service, an dem Sie tatsächlich arbeiten. Sie bekommen Root-Regeln plus lokale Regeln und nichts aus den zwölf Services, die Sie nicht anfassen — der günstigste Weg, Claude Code den richtigen Kontext zu geben, ohne es zu ertränken.
Wie groß muss Ihr Repo sein, bevor CLAUDE.md-Scoping zählt?
Scoping zählt in dem Moment, in dem ein einzelnes Root-CLAUDE.md nicht mehr zugleich vollständig und schlank bleiben kann — das ist eine Formschwelle, keine Zeilenzahlschwelle. Anthropics Ziel lautet "under 200 lines per CLAUDE.md file", weil "longer files consume more context and reduce adherence." Ein kleines Single-Purpose-Repo kann alles Wesentliche unter dieser Decke halten. Ein Monorepo kann das nicht: Sobald "vollständig" das Root-File über etwa 200 Zeilen drückt, ist der Punkt erreicht, an dem Scoping sich bezahlt macht.
Der tiefere Grund für schlanken Kontext ist unabhängig von Anthropic. Chromas "Context Rot"-Studie testete 18 Frontier-Modelle und fand, dass alle mit wachsender Eingabelänge messbar schlechter werden. Stanfords "Lost in the Middle"-Forschung ergänzt die Form: Modelle achten stark auf Anfang und Ende ihres Kontextes und schwach auf die Mitte. Regeln, die in einem langen File begraben sind, werden also am ehesten ignoriert. Ein 200-Zeilen-CLAUDE.md ist keine Stilpräferenz — es platziert Ihre wichtigsten Regeln dort, wo das Modell sie tatsächlich liest.
Ein nicht offensichtlicher Mechanismus, den Sie kennen sollten, bevor Sie zu viel in CLAUDE.md investieren: Es ist beratend, nicht erzwingend. Die Memory-Dokumentation von Claude Code sagt, der Inhalt "is delivered as a user message after the system prompt, not as part of the system prompt itself"; deshalb gibt es "no guarantee of strict compliance." Wenn eine Regel immer halten muss — diese Datei nie anfassen, diesen Befehl immer ausführen — dann ist das Aufgabe eines Hooks, nicht einer CLAUDE.md-Zeile.
Die Faustregel lautet: Ein Repo, dessen wesentlicher Kontext unter etwa 200 Zeilen passt → ein einzelnes schlankes CLAUDE.md. Sobald Vollständigkeit Sie darüber schiebt → in Verzeichnisse scopen. Zeilenzahl ist der Proxy; der echte Trigger ist, wenn ein File nicht mehr gleichzeitig vollständig und schlank sein kann.
Wann nehmen Sie einen Subagent statt des Hauptthreads?
Nehmen Sie einen Subagent, wenn eine Aufgabe Ihren Hauptkontext mit Lektüre fluten würde, die Sie nicht behalten wollen — Exploration, Suche, Untersuchung — und bleiben Sie für kontinuierliche Editierarbeit selbst im Hauptthread. Anthropic formuliert die Trennung sauber: "Subagents split exploration from editing." Der Mechanismus darunter: Ein Subagent ist "an isolated Claude instance with its own context window", erledigt die schwere Lektüre und "returns only the summary."
Die Subagents-Dokumentation von Claude Code bestätigt die Isolation: Jeder Subagent "runs in its own context window with a custom system prompt, specific tool access, and independent permissions" und "the subagent does that work in its own context and returns only the summary." Sie benennt auch die Grenze: Subagents können keine Subagents spawnen, "to prevent infinite nesting" — rekursiv können Sie sich also nicht darauf stützen.
Warum das eine Startentscheidung ist und keine Fortgeschrittenenfunktion, zeigt Anthropics Beispiel. Im illustrativen Walkthrough "the subagent read 6,100 tokens of files" und "you got a 420-token result." Behandeln Sie die genauen Zahlen als repräsentativ, nicht garantiert — die Quelle markiert sie so —, aber das Verhältnis ist der Punkt: Die teure Lektüre passiert in einem Kontext, für den Ihre Hauptsession nie bezahlt. Wenn Ihr Symptom ist, dass Untersuchungen die Session aufblasen — Anthropics eigenes Fehlermuster: "Claude reads hundreds of files, filling the context" — ist ein Explorations-Subagent der erste Zug, noch vor CLAUDE.md-Tuning.
Die entscheidende Trennung:
- Starten Sie mit einem Subagent, wenn die Arbeit leseintensiv und trennbar ist — ein unbekanntes Package erkunden, alle Aufrufer einer Funktion finden, einen Bug über Module hinweg untersuchen. Die Kosten bleiben im Fenster des Subagents.
- Bleiben Sie im Hauptthread, wenn die Arbeit ein kontinuierliches Architektururteil braucht oder wenn die Lektüre, die Sie tun, genau der Kontext ist, gegen den Sie weiter editieren wollen. Das auszulagern wirft den Kontext weg, den Sie behalten wollten.
Was ist agentic search, und wann schlägt sie einen Index?
Agentic search ist die Art, wie Claude Code Kontext findet: Es erkundet bei Bedarf — Dateien traversieren, lesen, grep ausführen, Referenzen folgen — statt einen vorgebauten Vector Index abzufragen. Sie schlägt einen Index immer dann, wenn Frische und Null-Setup wichtiger sind als rohes Query-Volumen. Anthropic beschreibt die Navigation direkt: Claude Code "traverses the file system, reads files, uses grep to find exactly what it needs, and follows references across the codebase", so wie eine Engineer es tun würde. Der explizite Tradeoff: "There's no embedding pipeline or centralized index to maintain."
Das ist das Entscheidungskriterium. Ein Retrieval-Augmented-Generation-Index (RAG) muss neu gebaut werden, wenn Code sich ändert; ein stale Index "reflects the codebase as it previously existed weeks, days, or even hours before", wie Anthropic es rahmt. Agentic search liest den Code, wie er jetzt ist — kein Rebuild, kein Drift, nichts zu warten. Für die meisten Teams lautet die Startantwort deshalb: eingebaut nutzen, nichts ergänzen.
Die Behauptung ist umstritten, also kennen Sie die Gegenposition, bevor Sie sich festlegen. Zilliz/Milvus — ein Vector-Database-Anbieter, der einen claude-context-Index ausliefert — argumentiert, grep-only Retrieval "just burns too many tokens" bei hohem Query-Volumen und semantische Suche sei auf großen, stabilen Codebases effizienter; das kommerzielle Eigeninteresse sollte man mitbewerten. Auf der anderen Seite berichtete ein Claude Engineer (zitiert via SmartScope) aus Tests das Gegenteil — "agentic search outperformed [it] by a lot, and this was surprising" — und unabhängige Analysen bestätigen, dass Claude Code eine lokale Vector DB zugunsten von Glob/Grep/Read fallen ließ.
Die Entscheidungsregel:
- Starten Sie mit agentic search (kein Index), wenn das Repo aktiv bearbeitet wird und Frische plus null Infrastruktur zählen — die meisten Produktteams. Sie vermeiden Index-Staleness und Setup-Kosten.
- Erwägen Sie eine Search-Sidecar nur, wenn Sie eine Token- oder Latenzwand auf einer hochvolumigen, relativ stabilen Codebase gemessen haben. Das ist der enge Fall, den die Vendor-Kritik beschreibt — nicht der Default.
Wann sollten Sie /compact nutzen, statt frisch zu starten?
Nutzen Sie /compact, wenn Sie an derselben Aufgabe weiterarbeiten und Platz zurückholen wollen; starten Sie mit /clear frisch, wenn Sie zu einer unabhängigen Aufgabe wechseln — und wissen Sie genau, was /compact behält, bevor Sie darauf vertrauen. Anthropics Best-Practices-Leitfaden ist deutlich: "the context window fills up fast, and performance degrades as it fills", und Sie sollten "/clear frequently between tasks to reset the context window entirely" nutzen. /clear ist der saubere Schnitt zwischen Jobs; /compact ist die Verdichtung mitten in der Aufgabe.
Die Entscheidung hängt daran, was eine Kompaktierung wirklich überlebt. Die Context-Window-Dokumentation von Claude Code spezifiziert es; diese Werte sind harte Caps, keine illustrativen Zahlen:
| Was im Kontext liegt | Überlebt /compact? |
|---|---|
| System Prompt und Output Style | Unverändert — nicht Teil der Message History |
Projekt-Root-CLAUDE.md und ungescopte Regeln | Von Disk neu injiziert |
| Auto Memory | Von Disk neu injiziert |
Pfadgescopte Regeln (paths:-Frontmatter) und verschachtelte CLAUDE.md | Verloren, bis wieder eine passende Datei gelesen wird |
| Invoked Skill Bodies | Neu injiziert, aber gedeckelt auf 5.000 Tokens pro Skill und 25.000 Tokens total — die ältesten fallen zuerst heraus |
Die Falle liegt in Zeile vier. Wenn das Arbeitswissen Ihrer Session aus einem verschachtelten CLAUDE.md oder einer pfadgescopten Regel kam, lässt /compact es still fallen, bis Sie wieder eine Datei in diesem Verzeichnis öffnen. Die Regel lautet deshalb: /compact, um an derselben Aufgabe weiterzumachen — aber wenn sie vom gescopten Kontext eines tiefen Verzeichnisses abhängt, berühren Sie danach wieder eine Datei dort, damit die Regeln neu laden. /clear immer dann, wenn Sie zu etwas Unabhängigem wechseln. Die Survival-Tabelle macht aus /compact ein Werkzeug statt einer Wette.
Was ist das Minimum, das Sie an Tag eins konfigurieren sollten?
Das Minimum ist ein dünnes Root-CLAUDE.md plus der eine Branch oben, der zu Ihrem lautesten Schmerz passt — mehr nicht. Anthropics eigene Einschränkung setzt die Grenze: Claude Code ist "designed around conventional software engineering environments where engineers are the primary codebase contributors, the repo uses Git, and code follows standard directory structures." Innerhalb dieses Rahmens brauchen Sie kein großes Initial-Setup; Sie brauchen den richtigen ersten Mechanismus.
Wenn Sie über Tag eins hinaus einen Adoptionspfad wollen, halten Sie ihn eng: ein 2-Wochen-Build-Sprint, um den Startmechanismus und die dünne Root-Karte aufzusetzen, danach ein 2-Wochen-Test-and-Iterate-Sprint, in dem Sie echte Sessions beobachten und den nächsten Mechanismus erst hinzufügen, wenn ein Symptom ihn verlangt. Vermeiden Sie mehrmonatige "Rollout-Pilot"-Rahmen — die Entscheidung hier ist klein und schnell, und Overplanning verzögert nur die erste echte Session. Wenn Sie bereit sind, die volle Hierarchie zu bauen, Skills zu scopen, Hooks zu ergänzen und das Setup über ein Team zu governancen, ist dafür der Implementierungsleitfaden da.
Maßgebliche Quellen und weiterführende Lektüre
Primärquellen und stützende Quellen
- Anthropics Applied-AI-Team, How Claude Code works in large codebases: Best practices and where to start (claude.com Blog, veröffentlicht am 14. Mai 2026) — Primärquelle für Repo-Form, agentic search, den
CLAUDE.md-Walk-up-Algorithmus und den Subagent-Split. (Keine individuelle Byline; Anthropics Applied-AI-Team zugeschrieben.) https://claude.com/blog/how-claude-code-works-in-large-codebases-best-practices-and-where-to-start - Claude-Code-Dokumentation — How Claude remembers your project (Memory /
CLAUDE.md-Ladereihenfolge, Ziel von ca. 200 Zeilen, beratend statt erzwingend). https://code.claude.com/docs/en/memory - Claude-Code-Dokumentation — Explore the context window (repräsentative 200K-Token-Zahlen, 6.100→420-Subagent-Beispiel,
/compact-Survival-Caps). https://code.claude.com/docs/en/context-window - Claude-Code-Dokumentation — Create custom subagents (separates Kontextfenster, gibt nur Summary zurück, keine Verschachtelung). https://code.claude.com/docs/en/sub-agents
- Claude-Code-Dokumentation — Best practices for Claude Code (Kontext als primäre Constraint,
/clearzwischen Aufgaben, Infinite-Exploration-Fehlermuster). https://code.claude.com/docs/en/best-practices - Chroma, Context Rot — unabhängige Messung, dass alle 18 getesteten Frontier-Modelle bei wachsender Eingabelänge schlechter werden. https://www.understandingai.org/p/context-rot
- Liu et al., Lost in the Middle: How Language Models Use Long Contexts (Stanford et al., arXiv 2307.03172) — die U-förmige Attention-Kurve hinter schlankem Kontext. https://arxiv.org/abs/2307.03172
- Zilliz/Milvus, Why I'm Against Claude Code's Grep-Only Retrieval — die Vector-DB-Vendor-Gegenposition zu agentic search (kommerzielles Interesse vermerkt). https://milvus.io/blog/why-im-against-claude-codes-grep-only-retrieval-it-just-burns-too-many-tokens.md
Weiterführende Artikel von AI Heroes
- Claude Code in großen Codebases: Der Implementierungs-Leitfaden 2026 — sobald Sie wissen, wo Sie starten, bauen Sie hier die volle CLAUDE.md-Hierarchie, Skills, Hooks, Subagent-Patterns und den Team-Rollout.
- The AI Agent Harness Debt You're Quietly Taking On — warum das Harness um das Modell Wartungskosten aufbaut und wie Sie es schlank halten.
- KI-Agenten-Workflow-Automatisierung — wiederholbare Engineering-Aufgaben in governte Agenten-Workflows verwandeln.
- Claude für kleine Unternehmen: Implementierungs-Leitfaden 2026 — dieselbe Start-schmal-Disziplin für ein kleines Team, das Claude einführt.
Der Agent für genau diese Aufgabe

Richard
A forward-deployed AI agent that gets your software live and adopted inside every customer.
Richard kennenlernenHäufig gestellte Fragen

Founder, AI Heroes
I build AI companies and the systems inside them. At AI Heroes, we give businesses the functional capacity to grow without the headcount growth normally demands — sales that follows up, marketing that runs, content that ships, ops that handles itself. We audit where you're leaving growth on the table, build the team that captures it, and hand it over completely.
I've built at scale before. Leading product and GTM at SlideSpeak AI (1M+ monthly users, profitable, bootstrapped). CPO at Disperse — the AI construction platform that went from 3 to 200+ people on $35M raised. I also co-founded LOBOMAR, a luxury fashion label featured in Elle, Cosmopolitan, and the LA Times, with shows at the London Design Museum, Wereldmuseum, and Amsterdam Fashion Week.
Ähnliche Artikel
Claude Code in großen Codebases: Der Implementierungs-Leitfaden 2026
Claude Code gewinnt in großen Codebases nicht, indem es das Repo verschlingt. Es gewinnt, wenn Sie eine Navigations- und Governance-Schicht darum herum bauen.

Claude Code + HTML: Der Implementierungs-Leitfaden 2026 für das richtige Output-Medium
Anthropics eigene Engineers haben Claude-Code-Outputs für fast alles auf HTML umgestellt. Die Implementierungsfrage lautet: Wann gewinnt HTML, wann nicht, und wie sollte das Handoff von Claude Design zu Claude Code wirklich aussehen?
Wie man 2026 eine KI-native Engineering-Organisation führt
Agentic Coding entfernt den Engineering-Engpass nicht — er verschiebt ihn vom Schreiben des Codes zur Verifizierung. Das ist das Betriebsmodell 2026 für eine KI-native Engineering-Organisation: welche Prozesse neu geschrieben werden müssen, wie Code Review sich verändert und welche Metriken zeigen, ob es funktioniert.