
Der Prompt, der nie funktionierte
Auf den Punkt
- Prompt-Bibliotheken scheitern, wenn der versteckte Kontext hinter einem guten Prompt nicht zwischen Analysten portabel ist.
- Skills verwandeln Urteil in Dateien: Anweisungen, Referenzen und Ausführungsschritte, die Outputs über Personen und Sessions hinweg konsistent machen.
- Die richtige Reihenfolge ist erst manueller Prozess, dann dokumentierte Edge Cases, dann Skill; sonst skaliert die Organisation ein ungeprüftes Vorgehen.
Warum acht Monate Prompt-Engineering nicht das liefern, was Sie denken — und welche strukturelle Ebene den meisten Unternehmen fehlt.
Der Prompt, der nur für eine Person funktionierte
Sarah ist COO eines 60-köpfigen Unternehmens für Vertragsanalyse in Frankfurt. In den letzten acht Monaten hatte sie eine Prompt-Bibliothek aufgebaut, die beeindruckend aussah: Vorlagen für die Prüfung von Geheimhaltungsvereinbarungen, Lieferantenverträge, Force-Majeure-Klauseln. Jeder Prompt war präzise formuliert, mehrfach getestet, dokumentiert. Es war die Art von Arbeit, auf die man stolz sein kann.
Dann teilte sie die Bibliothek mit ihrem Team.
Derselbe Prompt — Wort für Wort identisch — lieferte bei verschiedenen Analysten grundlegend verschiedene Ergebnisse. Ein Analyst produzierte knackige, präzise Zusammenfassungen. Eine andere übersah regelmäßig die Haftungsobergrenze in Entschädigungsklauseln. Nicht weil der Prompt schlecht war. Nicht weil das Modell versagte. Sondern weil Sarahs eigenes Fachwissen — ihre Fähigkeit, das Modell im richtigen Moment in die richtige Richtung zu lenken — nicht im Prompt steckte.
Die Anweisung war portabel. Das Urteilsvermögen dahinter war es nicht.

Was acht Monate Prompt-Engineering tatsächlich produzieren
Die Qualität eines Prompts ist ein gefährlich unvollständiges Maß. Sarahs Prompts funktionierten — für Sarah. Sie funktionierten, weil sie die impliziten Annahmen verstand: welche Klauseln in welchem Rechtsgebiet priorisiert werden, wann eine abweichende Formulierung ein Risiko darstellt und wann sie branchenüblich ist, wie scharf die Zusammenfassung sein sollte, je nachdem ob der Empfänger ein Jurist oder ein Geschäftsführer ist.
Nichts davon stand im Prompt.
Das ist das Muster, das die meisten Unternehmen übersehen: Sie messen Prompt-Qualität an den eigenen Ergebnissen und verwechseln persönliche Expertise mit portierbarem Wissen. Die Person, die den Prompt geschrieben hat, liefert hervorragende Ergebnisse. Alle anderen liefern… unterschiedliche Ergebnisse.
Claude Skills — bestehend aus einer skill.md-Datei, Referenzdateien und Skripten — sind die architektonische Antwort auf genau dieses Problem. Sie werden über Claude Code als Plugins bereitgestellt. Und sie lösen etwas, das Prompts allein nie lösen können: die Trennung von Anweisung und Urteilsvermögen.
Die Architektur, die niemand ans Whiteboard zeichnet
In London hatte der Head of Revenue Operations eines Fintech-Unternehmens ein Automatisierungssystem gebaut, das sich auf dem Papier hervorragend las: Zapier-Flows, Make.com-Szenarien, Webhook-Pipelines, die Daten zwischen CRM, Buchhaltung und Vertragsverwaltung hin- und herschoben. Es funktionierte — solange die Eingaben dem erwarteten Format entsprachen.
Dann schickte ein Kunde gescannte PDFs mit handschriftlichen Änderungen. Die Pipeline brach nicht zusammen. Sie leitete alles in eine manuelle Prüfschlange. Innerhalb von sechs Wochen war die Prüfschlange größer als der ursprüngliche manuelle Prozess.
Das Problem war nicht die Automatisierung. Es war die fehlende Mittelschicht — die Ebene zwischen starrer Regellogik und menschlichem Urteilsvermögen.
In Berlin hatte eine HR-Plattform ein ähnliches Problem mit Kandidatenbriefings. Jeder Recruiter fasste Bewerberprofile anders zusammen. Ton, Detailtiefe, Struktur — alles inkonsistent. Das Team baute mit Claude Code ein Kandidatenbriefing-Skill: fünf klar definierte Schritte, Referenzdateien für Bewertungskriterien und Branchenterminologie, bereitgestellt als Plugin.
Das Ergebnis war nicht sofort perfekt. „Das erste Mal, dass wir die Ausgabe ohne Nachbearbeitung verwendet haben, war sechs Monate nach dem Start", sagte die Teamleiterin. Aber das ist der Punkt: Das Skill-System verbesserte sich über die Zeit, weil die Referenzdateien mit jeder Iteration präziser wurden. Ein Prompt verbessert sich nicht. Er bleibt, wie er ist.
Die Mittelschicht — das, was wir als souveräne Agenten-Skills bezeichnen — kodifiziert nicht nur was zu tun ist, sondern wie Entscheidungen innerhalb dieses Prozesses getroffen werden.
Skills, Plugins und warum die Unterscheidung zählt
Die Begriffe werden oft austauschbar verwendet. Sie sollten es nicht.
Ein Skill ist eine Architektur. Er besteht aus einer skill.md-Datei (die Kernlogik und den Ablauf beschreibt), Referenzdateien (die das Fachwissen kodifizieren) und optional Skripten (die technische Schritte automatisieren). Ein Skill existiert als Struktur.
Ein Plugin ist ein Skill, der verpackt und bereitgestellt wurde. Er ist über Claude Code zugänglich, kann von einem Agenten geladen und ausgeführt werden. Ein Plugin ist ein Skill in Aktion.
Sarahs Prompt-Bibliothek war eine Werkzeugsammlung. Ihre Claude-Code-basierte Architektur — mit skill.md-Dateien, Referenzdateien für Rechtsgebiete und Klauseltaxonomien — war Infrastruktur.
Der Unterschied zeigte sich beim Onboarding. Früher brauchte ein neuer Analyst sechs Wochen, um Sarahs implizites Wissen durch Beobachtung, Fragen und Fehler zu absorbieren. Mit der Skill-Architektur dauerte das Onboarding einen Vormittag. Nicht weil der neue Analyst weniger lernen musste — sondern weil das, was gelernt werden musste, in Dateien lag statt in Sarahs Kopf.
Warum konsistente Ausgabe schwerer ist als gute Ausgabe
Die meisten Teams haben kein Qualitätsproblem. Sie haben ein Reproduzierbarkeitsproblem.
Sarah konnte mit ihrem Prompt eine erstklassige Vertragsanalyse produzieren. Das war nie die Schwierigkeit. Die Schwierigkeit war, dass fünf verschiedene Analysten mit demselben Prompt fünf verschiedene Ergebnisse lieferten — alle akzeptabel, keines identisch, einige mit kritischen Lücken.
Sie baute ihr System um. Die skill.md-Datei definierte den Ablauf: Vertrag empfangen, Rechtsgebiet identifizieren, Klauseln gegen Taxonomie prüfen, Risikobewertung erstellen. Die Referenzdateien taten die eigentliche Arbeit: clause_taxonomy.md kodifizierte, welche Klauseltypen in welchen Vertragsarten zu prüfen sind. jurisdiction_flags.md dokumentierte rechtsgebietsspezifische Besonderheiten. review_checklist.md stellte sicher, dass kein Analyst einen Schritt übersprang.
Das Ergebnis: Der Skill nimmt den Menschen nicht aus dem Prozess heraus. Er nimmt den Menschen als die Schleife heraus. Der Analyst bleibt involviert — prüft, bewertet, entscheidet. Aber der Prozess selbst hängt nicht mehr davon ab, dass ein bestimmter Mensch ihn in einer bestimmten Weise durchführt.
Wo das Ganze an seine Grenzen stößt
Es gibt eine Grenze, die ehrlich benannt werden muss: Wenn Ihr Standardprozess falsch ist, automatisiert ein Skill den Fehler im großen Maßstab.
Das klingt offensichtlich. In der Praxis ist es das nicht. Viele Unternehmen haben Standardprozesse, die sich über Jahre organisch entwickelt haben — mit Workarounds, die niemand mehr hinterfragt, mit Ausnahmen, die zur Regel geworden sind. Wenn Sie diese Prozesse eins zu eins in eine skill.md-Datei übersetzen, produzieren Sie konsistente, zuverlässige, schnelle — und möglicherweise falsche — Ergebnisse.
Die Reihenfolge sollte sein: Manueller Prozess zuerst. Grenzfälle identifizieren. Prozess korrigieren. Dann — und nur dann — in einen Skill formalisieren.
Ein Skill ist ein Verstärker. Er macht gute Prozesse skalierbar und schlechte Prozesse gefährlich.
Die Frage, die sich in jeder Prompt-Bibliothek versteckt
Sarah nutzt ihre Prompt-Bibliothek heute als Rohmaterial. Jeder Prompt ist ein Hinweis auf kodifizierbares Wissen — ein Ausgangspunkt für die Frage: Was steckt an implizitem Urteilsvermögen hinter dieser Anweisung, und wie mache ich es portabel?
Die Antwort ist in den meisten Fällen überraschend kompakt: drei Dateien und eine Claude-Code-Bereitstellung. Eine skill.md für den Ablauf. Referenzdateien für das Fachwissen. Skripte für die technischen Schritte.
Die eigentliche Frage, die sich hinter jeder Prompt-Bibliothek verbirgt, ist nicht „Wie schreibe ich bessere Prompts?" — sondern „Wie mache ich das Wissen hinter meinen Prompts portabel?"
Die meisten Unternehmen beantworten die erste Frage. Die wenigen, die die zweite beantworten, bauen etwas grundlegend anderes.
Bereit, Ihre Prompt-Bibliothek in echte Infrastruktur zu verwandeln? Sprechen Sie mit AI Heroes — wir helfen Ihnen, den Schritt von Prompts zu Skills zu machen.
Der Agent für genau diese Aufgabe

Richard
A forward-deployed AI agent that gets your software live and adopted inside every customer.
Richard kennenlernenHäufig gestellte Fragen

Founder, AI Heroes
I build AI companies and the systems inside them. At AI Heroes, we give businesses the functional capacity to grow without the headcount growth normally demands — sales that follows up, marketing that runs, content that ships, ops that handles itself. We audit where you're leaving growth on the table, build the team that captures it, and hand it over completely.
I've built at scale before. Leading product and GTM at SlideSpeak AI (1M+ monthly users, profitable, bootstrapped). CPO at Disperse — the AI construction platform that went from 3 to 200+ people on $35M raised. I also co-founded LOBOMAR, a luxury fashion label featured in Elle, Cosmopolitan, and the LA Times, with shows at the London Design Museum, Wereldmuseum, and Amsterdam Fashion Week.
Ähnliche Artikel
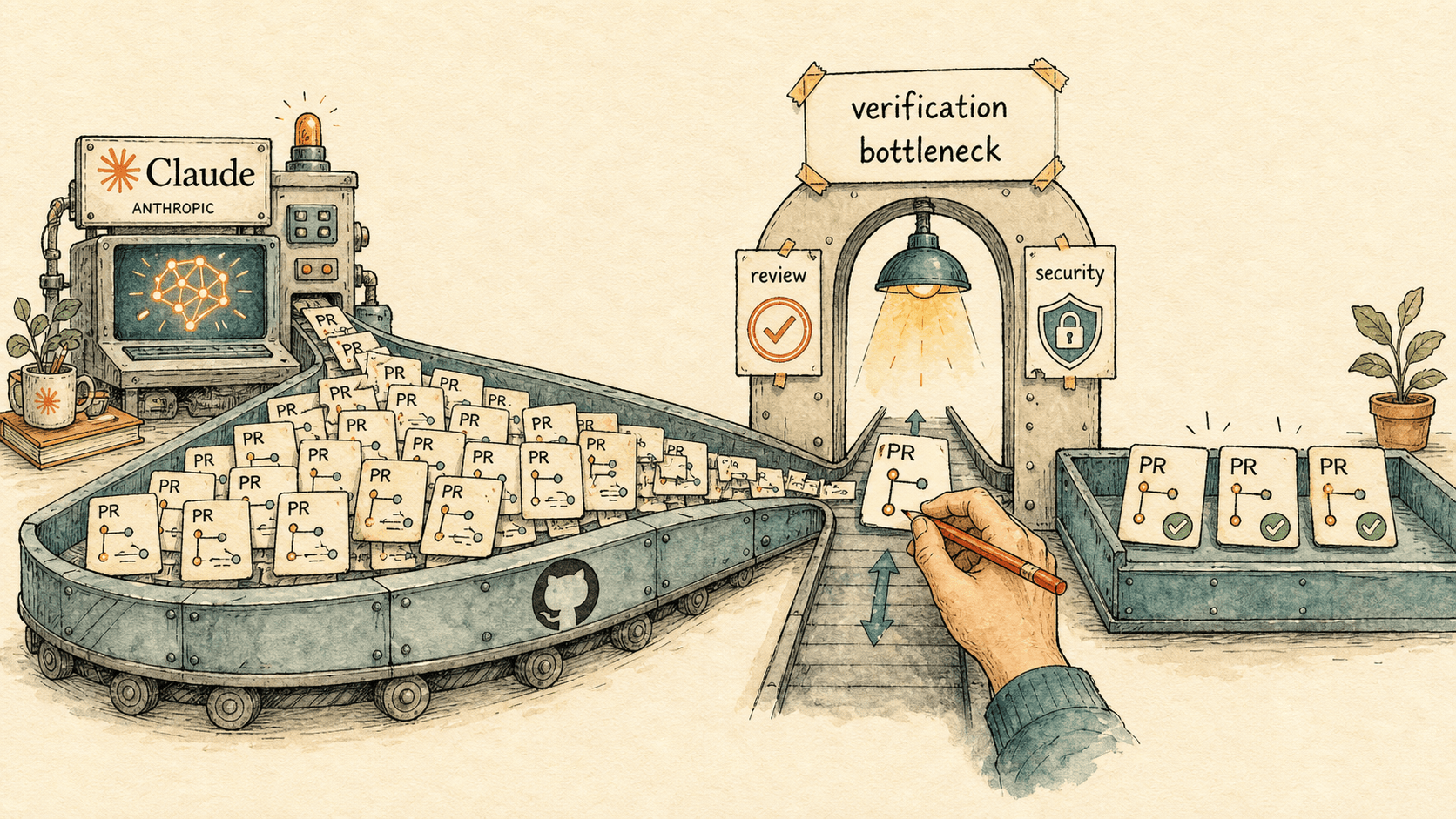
Wie man 2026 eine KI-native Engineering-Organisation führt
Agentic Coding entfernt den Engineering-Engpass nicht — er verschiebt ihn vom Schreiben des Codes zur Verifizierung. Das ist das Betriebsmodell 2026 für eine KI-native Engineering-Organisation: welche Prozesse neu geschrieben werden müssen, wie Code Review sich verändert und welche Metriken zeigen, ob es funktioniert.
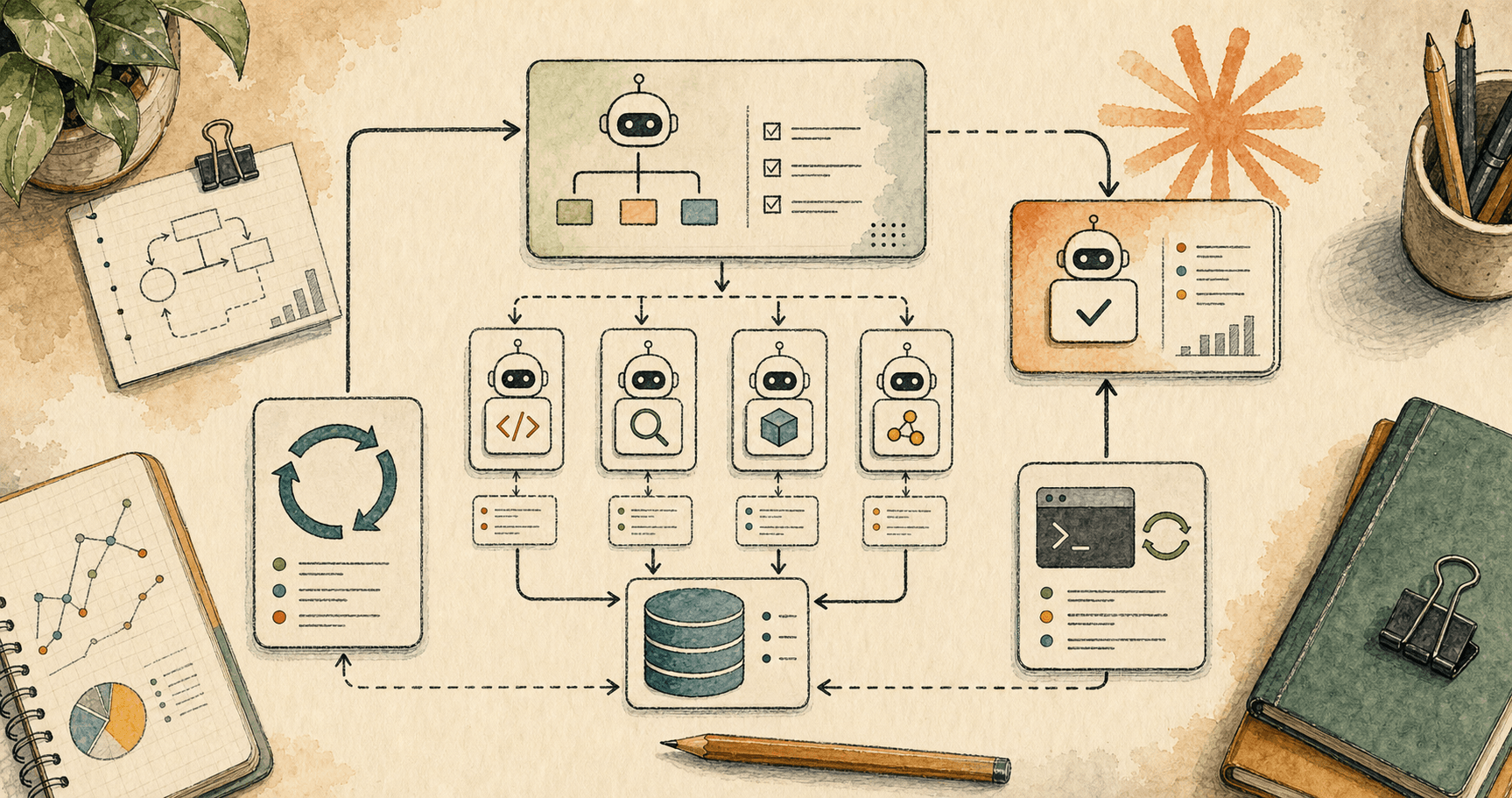
Claude Code Dynamic Workflows: What Is Actually New in 2026?
Claude Code dynamic workflows are not just parallel agents. They turn a prompt into an executable orchestration script that can split work, store intermediate results, cross-check findings and return one synthesised answer.
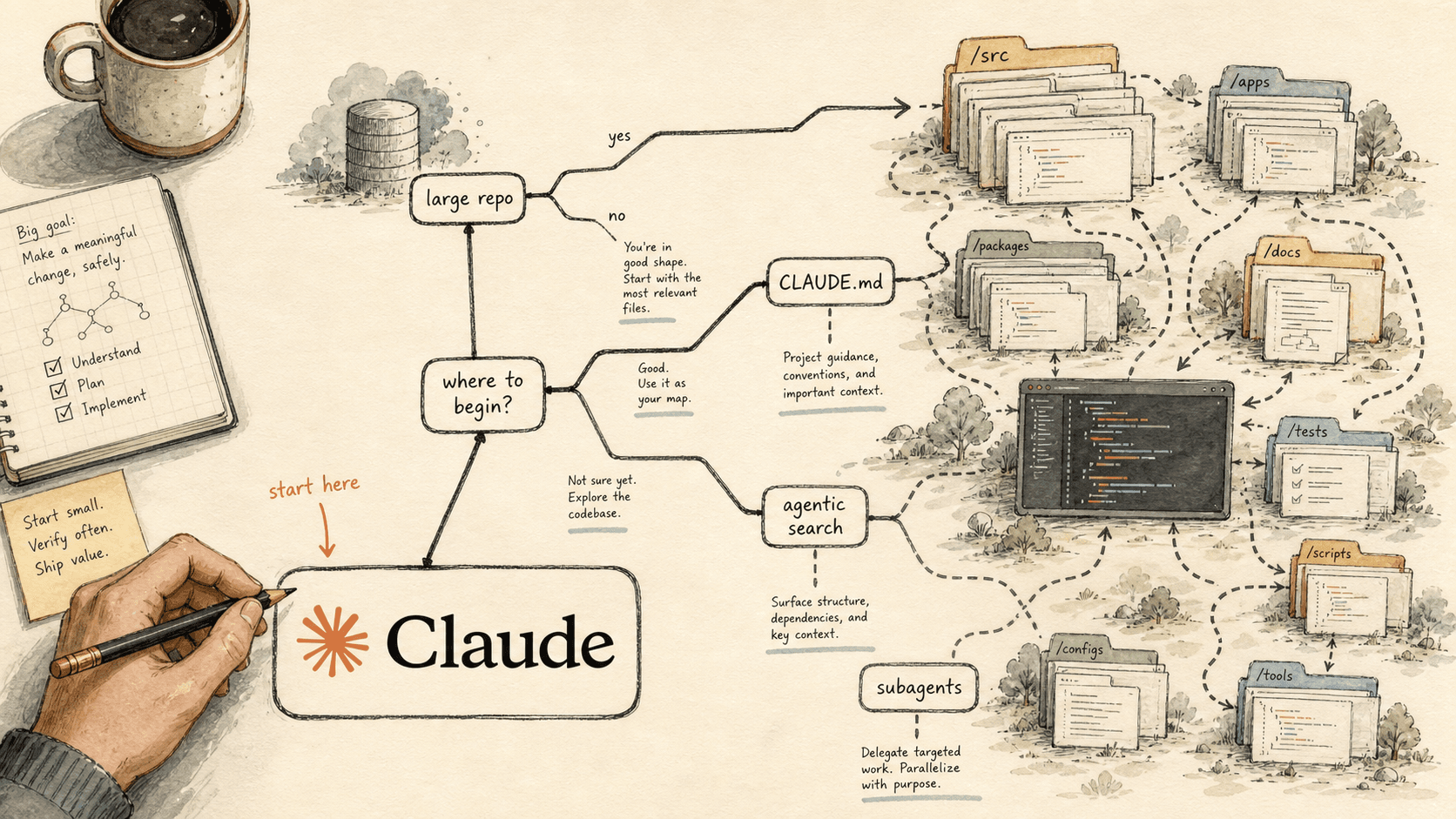
Wo Sie mit Claude Code in einem großen Repo anfangen: ein Entscheidungsbaum (2026)
Sie starten einen großen Claude-Code-Rollout nicht damit, alles zu konfigurieren. Sie starten mit dem einen Mechanismus, den Repo-Form und echter Schmerzpunkt verlangen — und ignorieren den Rest, bis Sie ihn wirklich brauchen. Das ist die Entscheidungsschicht vor dem Build.