
So funktionieren Claude Managed Agents wirklich: Dreaming, Outcomes, Multiagent-Orchestrierung und Webhooks (2026)
Auf den Punkt
- Claude Managed Agents ist Anthropics gehostete Schicht für Agenten, die sich mit der Zeit verbessern. Bei Code w/ Claude in San Francisco (Mai 2026) kamen vier Mechaniken hinzu: Dreaming, Outcomes, Multiagent-Orchestrierung und Webhooks.
- Die eine, die verändert, wie man baut, ist Outcomes: Ein separater Grader bewertet die Arbeit des Agenten in einem eigenen Kontextfenster, isoliert von dessen Argumentation, und schickt sie zur Überarbeitung zurück, bis eine Rubrik erfüllt ist. Anthropic berichtet von bis zu 10 Prozentpunkten mehr Aufgabenerfolg gegenüber einer einfachen Prompting-Schleife.
- Die Features sind der einfache Teil. Eine Rubrik zu schreiben, die „gut" erfasst, saubere Orchestrierungsgrenzen zu ziehen und Webhooks, Sandboxes und Tunnel in Systeme zu verdrahten, die Sie bereits betreiben, ist die Arbeit, die ein Launch Ihnen überlässt.
Anthropic hat seine Entwicklerkonferenz in San Francisco genutzt, um ein einziges Argument zu machen: Der Abstand zwischen einer Idee und funktionierender Software schrumpft, und die Teams mit dem größten Hebel sind die, die dafür entwerfen, statt darauf zu reagieren. Der konkreteste Beleg war eine Reihe neuer Fähigkeiten für Claude Managed Agents — die Plattformschicht, die Agenten auf Anthropics Infrastruktur laufen lässt statt auf Ihrem Laptop.
Vier Mechaniken kamen gemeinsam. Jede ist für sich nützlich. Zusammen gelesen beschreiben sie eine einzige Verschiebung: Agenten, die ihre eigene Arbeit bewerten, sie auf Spezialisten aufteilen, sich merken, was funktioniert hat, und Bescheid geben, wenn sie fertig sind.
Was sind Claude Managed Agents?
Claude Managed Agents ist Anthropics gehostete Plattform für selbstverbessernde Agenten, bei der Anthropic die Agent-Schleife betreibt — Orchestrierung, Kontextverwaltung und Fehlerbehebung —, während Sie die Aufgabe, die Werkzeuge und die Erfolgskriterien definieren. Sie unterscheidet sich von Claude Code, der Entwickler-CLI: Managed Agents ist die API- und Console-Oberfläche für Agenten, die serverseitig laufen, geplant oder bei Bedarf, ohne dass ein Mensch jeden Schritt überwacht.
Die vier am 6. Mai 2026 angekündigten Features gliedern sich so:
| Feature | Was es macht | Stand (Mai 2026) | Wann Sie es einsetzen |
|---|---|---|---|
| Dreaming | Ein geplanter Job prüft vergangene Sessions und Memory, extrahiert Muster und kuratiert, woran sich der Agent erinnert | Research Preview | Viele ähnliche Läufe wiederholen dieselben Fehler oder entdecken denselben Workflow neu |
| Outcomes | Ein separater Grader bewertet die Ausgabe in einem eigenen Kontextfenster gegen Ihre Rubrik und schleift den Agenten, bis er besteht | Public Beta | Qualität ist in einem Durchgang schwer zu treffen, aber in einer Rubrik leicht zu beschreiben |
| Multiagent-Orchestrierung | Ein Lead-Agent teilt Arbeit auf und delegiert an Spezialisten, jeder mit eigenem Modell, Prompt und Werkzeugen, parallel auf einem gemeinsamen Dateisystem | Public Beta | Die Aufgabe ist zu groß oder zu vielfältig für ein Kontextfenster |
| Webhooks | Definieren Sie ein Outcome, lassen Sie den Agenten laufen, und werden Sie benachrichtigt, wenn er fertig ist | Public Beta | Aufgaben laufen lange genug, dass das Babysitten der eigentliche Kostenfaktor ist |
Wie funktioniert Dreaming, und wann sollten Sie es nutzen?
Dreaming ist ein geplanter Prozess, der vergangene Sessions und Memory-Speicher eines Agenten prüft, Muster extrahiert und Memory kuratiert, damit der Agent sich zwischen Läufen verbessert. Anthropic beschreibt es als das Sichtbarmachen dessen, was eine einzelne Session allein nicht sehen kann: wiederkehrende Fehler, Workflows, auf die Agenten konvergieren, und teamweit geteilte Präferenzen. Es kann Memory automatisch aktualisieren oder Änderungen zur Prüfung zurückhalten, bevor sie übernommen werden.
Dreaming ist in der Research Preview. Anthropic verweist auf das Legal-AI-Unternehmen Harvey, dessen Abschlussraten „in ihren Tests um das ~6-Fache stiegen". Behandeln Sie das so, wie Sie jede Pilotzahl eines Anbieters behandeln würden, die über dessen eigenen Blog berichtet wird: eine belegte Anekdote aus den Tests eines Teams, kein veröffentlichter Benchmark mit Baseline und Methodik. Der dauerhafte Teil ist der Mechanismus — periodische, strukturierte Memory-Kuration statt einer ständig wachsenden, ständig verrauschteren Memory-Datei.
Greifen Sie zu Dreaming, wenn Sie viele ähnliche Agent-Sessions betreiben und der Engpass Drift ist: Der Agent lernt dieselben Lektionen immer wieder neu, oder sein Memory ist zu Rauschen angewachsen. Lassen Sie es aus, wenn Sessions Einzelfälle ohne erkennbares Muster sind.
Wie funktionieren Outcomes, und warum ist ein separater Grader wichtig?
Mit Outcomes schreiben Sie eine Rubrik, die beschreibt, wie Erfolg aussieht, und ein separater Grader bewertet die Ausgabe des Agenten gegen diese Rubrik in einem eigenen Kontextfenster — „damit er nicht von der Argumentation des Agenten beeinflusst wird", in Anthropics Worten. Wenn die Arbeit unzureichend ist, benennt der Grader genau, was zu ändern ist, und der Agent macht einen weiteren Durchgang, bis er die Schwelle erreicht.
Das entscheidende Detail ist die Trennung. Ein Agent, der seine eigene Arbeit bewertet, ist dasselbe Modell, das sie gerade erzeugt hat — durch seine eigene Argumentation darauf geprägt, sich für fertig zu halten. Ein Grader in einem sauberen Kontextfenster trägt diese Vorprägung nicht. Die Trennung von Erzeugung und Bewertung ist das zuverlässigste Muster überhaupt, um Agenten vertrauenswürdig zu machen, und Outcomes macht daraus ein Plattform-Primitiv, statt etwas, das jedes ernsthafte Team von Hand nachbaut.
Anthropic berichtet den Zugewinn aus internen Tests: Der Aufgabenerfolg verbesserte sich um bis zu 10 Punkte gegenüber einer einfachen Prompting-Schleife, mit den größten Zuwächsen bei den schwierigsten Problemen, sowie konkret +8,4 % bei docx- und +10,1 % bei pptx-Aufgaben. Das sind Anthropics eigene Zahlen, also gewichten Sie sie als richtungsweisend — aber die Richtung deckt sich mit dem, was eval-getriebene Teams ohnehin sehen, sobald sie einem einzelnen Durchgang nicht mehr vertrauen.
Outcomes ist in der Public Beta. Greifen Sie zu, wenn „gut" in einem Durchgang schwer zu erzeugen, aber leicht zu beschreiben ist. Lassen Sie es weg, wenn Sie die Rubrik nicht schreiben können, denn eine vage Rubrik erzeugt einen Grader, der alles durchwinkt.
Wie funktioniert Multiagent-Orchestrierung?
Multiagent-Orchestrierung lässt einen Lead-Agenten eine Aufgabe in Teile zerlegen und jeden Teil an einen Spezialisten mit eigenem Modell, Prompt und Werkzeugen delegieren, wobei die Spezialisten parallel auf einem gemeinsamen Dateisystem arbeiten und zum Kontext des Lead-Agenten beitragen. Persistente Events erlauben dem Lead-Agenten, mitten im Workflow nachzusehen, und der gesamte Ablauf ist in der Claude Console nachvollziehbar — welcher Agent was getan hat und warum.
Anthropics konkretes Beispiel ist eine Untersuchung: Ein Lead-Agent führt den Fall, während Subagenten gleichzeitig durch Deploy-Historie, Fehler-Logs, Metriken und Support-Tickets ausschwärmen. Genannt werden das Plattform-Team von Netflix, das einen Log-Analyse-Agenten über Hunderte von Builds gebaut hat, und Spiral, das Orchestrierung mit Outcomes kombiniert, um Schreibqualität durchzusetzen.
Es ist in der Public Beta. Greifen Sie zu, wenn die Arbeit wirklich zu groß oder zu vielfältig für ein Kontextfenster ist — parallele Recherche, Untersuchung aus mehreren Quellen, Aufgaben, bei denen verschiedene Teilaufgaben verschiedene Modelle wollen. Die Falle ist, es einzusetzen, wenn ein gut zugeschnittener einzelner Agent genügen würde: Jede Grenze, die Sie zwischen Agenten ziehen, ist eine Stelle, an der Kontext verloren gehen kann — Orchestrierung zahlt sich also nur aus, wenn die Parallelität echt ist.
Was bringen Webhooks?
Mit Webhooks definieren Sie ein Outcome, starten den Agenten und erhalten eine Benachrichtigung, wenn der Lauf endet — damit länger laufende Arbeit keinen Menschen braucht, der zusieht. In Kombination mit Outcomes schließt sich eine Schleife: Zielergebnis definieren, den Agenten sich per Bewerten-und-Überarbeiten dorthin schleifen lassen und benachrichtigt werden, sobald er die Schwelle erreicht. Es ist in der Public Beta. Das Muster, das es ermöglicht, ist Abfeuern-und-Prüfen — Agenten, die eine Aufgabe von Anfang bis Ende besitzen und zurückmelden, statt solcher, neben denen man sitzt.
Wo passen selbstgehostete Sandboxes und MCP-Tunnel hin?
Zwei Wochen später, beim London-Event am 19. Mai 2026, lieferte Anthropic die Features, die Managed Agents für Teams nutzbar machen, die keine Daten nach außen geben können: selbstgehostete Sandboxes und MCP-Tunnel. Sie teilen eine Entwurfsidee — den Managed Split. Die Agent-Schleife, die Orchestrierung, Kontextverwaltung und Fehlerbehebung übernimmt, bleibt auf Anthropics Infrastruktur, während die Teile, die Ihre Daten berühren, in Ihre Umgebung wandern.
Mit selbstgehosteten Sandboxes (Public Beta) läuft die Werkzeugausführung auf einer Infrastruktur, die Sie kontrollieren — Ihrer eigenen oder einem Managed-Provider wie Cloudflare, Daytona, Modal oder Vercel —, sodass Dateien und Repositories nie Ihren Perimeter verlassen und Sie Compute und Runtime-Image festlegen. Mit MCP-Tunneln (Research Preview) erreichen Agenten MCP-Server in Ihrem privaten Netzwerk, ohne sie dem Internet auszusetzen: Ein leichtgewichtiges Gateway, das Sie bereitstellen, baut eine einzige ausgehende Verbindung auf, ohne eingehende Firewall-Regeln, ohne öffentliche Endpunkte und mit Ende-zu-Ende-verschlüsseltem Verkehr. Tunnel funktionieren in Managed Agents und der Messages API, und Organisations-Admins verwalten sie über die Console.
| Fähigkeit | Was wo läuft | Stand | Der Punkt |
|---|---|---|---|
| Selbstgehostete Sandboxes | Werkzeugausführung in Ihrer Umgebung oder bei einem Managed-Provider; die Agent-Schleife bleibt bei Anthropic | Public Beta | Dateien und Repositories verlassen nicht Ihren Perimeter |
| MCP-Tunnel | Private MCP-Server über eine einzige ausgehende Verbindung erreichbar; keine eingehenden Regeln, Ende-zu-Ende verschlüsselt | Research Preview | Interne Datenbanken und APIs werden zu Agent-Werkzeugen, ohne öffentliche Exposition |
Für ein reguliertes Team ist das der Unterschied zwischen einer interessanten Demo und etwas, das man tatsächlich produktiv einsetzen kann.
Was änderte sich mit den verdoppelten Claude-Code-Limits?
Anthropic verdoppelte die Fünf-Stunden-Limits von Claude Code für Pro-, Max-, Team- und sitzbasierte Enterprise-Pläne, entfernte die Reduzierung zu Spitzenzeiten für Pro und Max und erhöhte die API-Limits für Claude Opus; der kostenlose Plan blieb unverändert. Berichte beziffern den API-Anstieg für Tier 1 auf etwa das Fünfzehnfache der maximalen Eingabe-Token pro Minute und das Neunfache bei der Ausgabe. Für Agent-Entwickler ist der Spielraum die eigentliche Nachricht: Orchestrierte, bewertete, lange laufende Agenten verbrauchen weit mehr Token als eine Chat-Session, und die bisherigen Limits ließen ernsthafte serverseitige Agenten an eine Wand laufen.
Wann sollten Sie welche Funktion einsetzen?
Ordnen Sie die Funktion dem Engpass zu, nicht der Ankündigung. Outcomes, wenn Qualität das Problem ist und Sie beschreiben können, wie gut aussieht. Multiagent-Orchestrierung, wenn der Umfang das Problem ist und die Arbeit sich wirklich parallelisieren lässt. Dreaming, wenn Wiederholung das Problem ist und der Agent immer wieder neu lernt. Webhooks, wenn Latenztoleranz das Problem ist und niemand den Lauf beobachten sollte. Sandboxes und Tunnel, wenn Vertrauensgrenzen das Problem sind und Daten nicht nach außen dürfen.
Die meisten produktiven Agenten nutzen am Ende zwei oder drei zusammen — ein orchestrierter Job, dessen Spezialisten von Outcomes bewertet werden, der in Ihrer eigenen Sandbox läuft und einen Webhook auslöst, wenn er fertig ist. Diese gegen Systeme zu verdrahten, die Sie bereits betreiben, und Rubriken zu schreiben, mit denen ein Grader tatsächlich etwas anfangen kann, ist die Arbeit, die ein Launch Ihnen überlässt.
Weiterführende Lektüre
Wenn Sie diese Fähigkeiten in etwas verwandeln, das Ihr Team tatsächlich betreibt, sind diese AI-Heroes-Beiträge das passende Begleitset:
- Claude Skills: warum Ihre besten Prompts immer wieder scheitern - die Architekturschicht, die Urteilsvermögen in wiederverwendbare Agent-Ausführung verwandelt.
- KI-Agenten-Workflow-Automatisierung - wie wiederkehrende Arbeit zu einem Agent-Workflow wird statt zu einem Ad-hoc-Chat.
- Der Long-Running-Agent-Harness auf dem Claude Agent SDK - die evaluator-gesicherte Schleife hinter Agenten, die man laufen lassen kann.
- KI und institutionelles Wissen - warum dauerhaftes Memory zählt, sobald sich mehr als eine Person auf einen Agenten verlässt.
- Im Finance-Team von Anthropic - wie ein gemanagter, menschlich geprüfter Agent-Workflow in der Praxis aussieht.
- Wo man bei Claude Code in einem großen Repo anfängt - die Entscheidungsschicht, die vor dem Bauen läuft.
Der Agent für genau diese Aufgabe

Richard
A forward-deployed AI agent that gets your software live and adopted inside every customer.
Richard kennenlernenHäufig gestellte Fragen

Founder, AI Heroes
I build AI companies and the systems inside them. At AI Heroes, we give businesses the functional capacity to grow without the headcount growth normally demands — sales that follows up, marketing that runs, content that ships, ops that handles itself. We audit where you're leaving growth on the table, build the team that captures it, and hand it over completely.
I've built at scale before. Leading product and GTM at SlideSpeak AI (1M+ monthly users, profitable, bootstrapped). CPO at Disperse — the AI construction platform that went from 3 to 200+ people on $35M raised. I also co-founded LOBOMAR, a luxury fashion label featured in Elle, Cosmopolitan, and the LA Times, with shows at the London Design Museum, Wereldmuseum, and Amsterdam Fashion Week.
Ähnliche Artikel

So starten Sie mit Claude Cowork: Ein Entscheidungsrahmen für Wissensarbeitende (2026)
Claude Cowork ist der Ort, an dem Sie eine ganze Aufgabe delegieren, statt eine Frage zu stellen — Dateien und Apps zeigen, das Ergebnis beschreiben, fertige Arbeit zurückbekommen. Der schwierige Teil ist nicht der Prompt, sondern zu wissen, welche Aufgaben Sie übergeben sollten. Hier sind ein 5-Signal-Fit-Test, die drei Formen einer Cowork-Aufgabe und der Weg zum ersten Deliverable in zehn Minuten.

Harness Debt: Ihr KI-Agenten-Gerüst arbeitet still gegen das Modell (2026)
Ihr KI-Agent ist wahrscheinlich schlechter als das Modell darin — und die Lücke ist Ihr eigenes Gerüst. Ein experimentelles Harness erzielte mit demselben Modell mehr als das Doppelte von Anthropics Standard-Harness. Die Lösung ist kein größeres Framework, sondern das Löschen von Annahmen, die am Tag des Claude-Opus-4.6-Release veraltet waren.
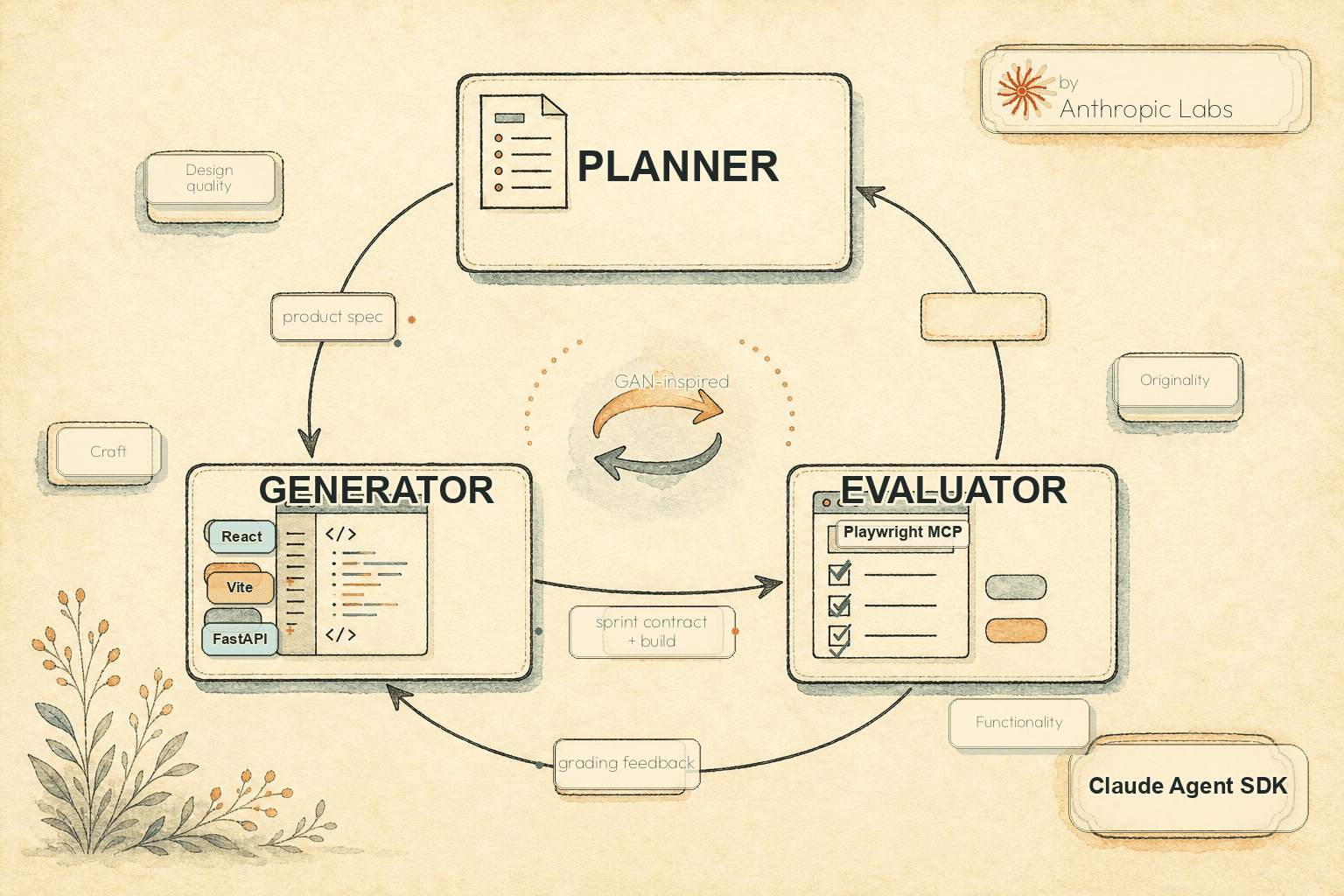
Harness Design for Long-Running AI Applications: Inside Anthropic's Generator-Evaluator Pattern (Claude Agent SDK, 2026)
On 24 March 2026 Anthropic Labs engineer Prithvi Rajasekaran published the most rigorous public account to date of how Anthropic designs harnesses for long-running AI applications — a GAN-inspired generator-evaluator pattern applied across two unusually different domains: frontend design (subjective, no binary verification) and full-stack coding (objective, machine-verifiable). The piece evolves the November 2025 Initializer + Coding Agent baseline into a three-agent planner + generator + evaluator architecture, with concrete cost-and-duration data ($200 / 6h on a retro game maker test, then $124 / 4h on a more ambitious DAW after the Opus 4.6 simplification pass). Inside the pattern, the two failure modes it fixes (context anxiety + self-evaluation bias), how it compares to LangGraph / AutoGen / OpenAI Assistants v2 / Devin, when it doesn't fit, and the canonical principle every team operating a harness should adopt: stress-test every component against the current model.