Building AI Agents in the Enterprise: Implementation Patterns for 2026
TL;DR
- Anthropic is right about the enterprise shape: durable agent programs have to change employees, processes, and products at the same time, not just add a chatbot to the intranet. The implementation question is how to turn that strategic frame into reusable skills, governed tool access, memory, observability, and safe agent operations.
- The production pattern is an agent fleet, not one giant assistant: single agents are useful for bounded work, multi-agent systems are useful for decomposed workflows, and enterprise fleets are useful when many governed agents need to run across teams, tools, schedules, and approval gates.
- The winning layer is institutional infrastructure: the companies that get compounding returns encode judgment into skills, plugins, reference files, evals, logs, and feedback loops. At AI Heroes, this is the layer we build first, because it decides whether Claude becomes a demo or an operating system.
Anthropic's Building AI agents for the enterprise playbook is useful because it does not pretend enterprise AI is a prompt-writing exercise. It frames the problem around employees, processes, and products; cites its September 2025 Economic Index finding that 40 percent of US employees report using AI at work; and points leaders toward Claude Cowork, plugins, skills, MCP, and managed agents as the rollout surface.
That is the right starting line. It is not the finish line.
The thing an implementation partner can say more bluntly than a model provider is this: most enterprise AI programs do not fail because the model is too weak. They fail because nobody built the operating layer around the model. The permissions are vague. The skills are personal instead of sovereign. The memory layer is a folder full of stale docs. The observability is screenshots in Slack. The pilot works because three exceptional people babysit it, then it stalls when the next 997 people need to use it.
This guide is the implementation layer we wish more enterprise teams drew before buying another seat bundle.
How does Anthropic frame enterprise AI-agent building?
Anthropic frames enterprise agents as a shift from point solutions to agentic systems that can reason through multi-step work, use tools, and apply domain context. Its playbook says the durable advantage comes from three simultaneous changes: upskilling employees, accelerating processes, and transforming products.
That frame matters. If a company treats Claude as a writing assistant, it gets faster drafts. If it treats Claude as an operating layer, it starts asking different questions: What work should be delegated? Which institutional standards should become reusable skills? Which tools can an agent touch? Where must human approval interrupt the flow? Which outputs become training data for the next run?
The playbook also points to the practical primitives: Claude Cowork for knowledge workers, Claude Code for engineering teams, MCP for connecting external systems, plugins for packaged team capabilities, and skills for repeatable workflows. The Model Context Protocol documentation describes MCP as an open standard for connecting AI applications to data sources, tools, and workflows. That is not a nice-to-have. It is how agent work stops being trapped inside a chat window.
McKinsey's 2025 State of AI survey supports the same direction of travel: 88 percent of respondents said their organizations regularly use AI in at least one business function, but only about one-third report scaling AI programs across the organization, and 23 percent report scaling an agentic AI system somewhere in the enterprise. Adoption is broad; real agent scaling is still early.
What does the Anthropic playbook leave for implementation teams to solve?
Anthropic can credibly describe the platform direction. It cannot fully describe the messy implementation decisions inside your company, because those decisions depend on your risk model, data estate, political reality, operating cadence, and appetite for delegation.
The missing layer is not "which model should we use?" It is "what should the enterprise agent fleet be allowed to do on Monday morning?"
That layer has five parts.
First, the work has to be decomposed into agent-sized jobs. A legal review agent, renewal-pack agent, sales-research agent, support-triage agent, and finance-reconciliation agent should not share one giant prompt. They need separate scopes, separate tools, separate memories, and separate approval rules.
Second, institutional judgment has to become portable. This is where sovereign skills matter. A skill should contain the execution procedure, reference files, examples, edge cases, and deterministic scripts that make a workflow repeatable. The goal is not a clever prompt. The goal is that a new team member, a scheduled routine, or a parallel agent can invoke the same capability and get the same standard.
Third, every agent needs a trust boundary. Some tools are read-only. Some can draft but not send. Some can write to a branch but not merge. Some can prepare a payment file but never execute payment. The permission model is the product.
Fourth, you need observability before scale. Logs, transcripts, eval results, cost traces, latency traces, tool-call history, and human override reasons should exist from the pilot, not after procurement asks for them.
Fifth, memory needs ownership. If nobody owns the reference files, the agent gets worse as the business changes. If every expert correction updates the skill or memory layer, the system compounds.
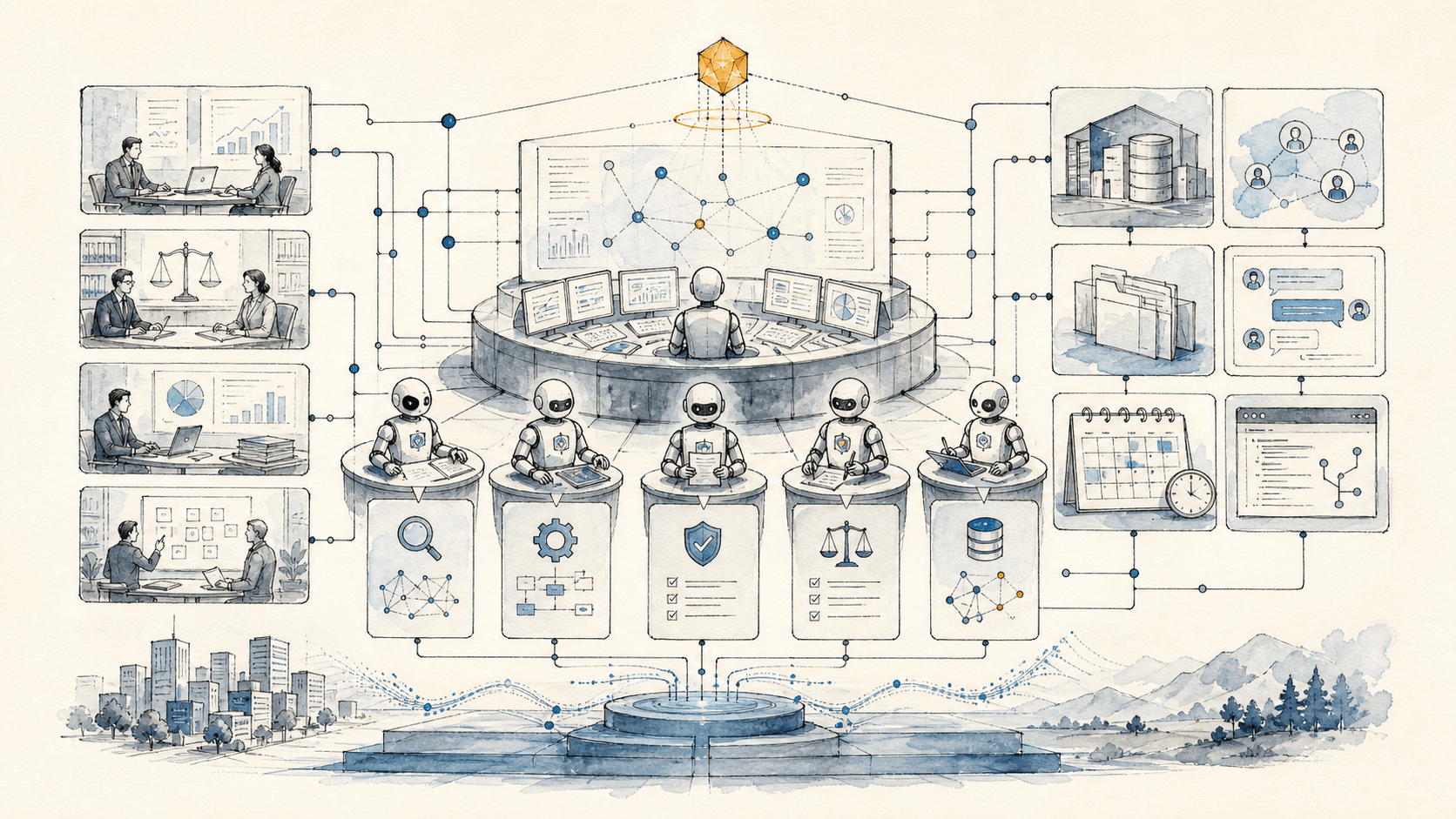
What's the real architecture of an enterprise AI agent fleet?
An enterprise agent fleet is a governed set of role-specific agents, shared skills, approved tools, memory systems, evals, logs, and human approval gates that work across departments. It is closer to an operations stack than a chatbot.
The simplest architecture has six layers:
| Layer | Question it answers | Implementation pattern | Common failure mode |
|---|---|---|---|
| Interface layer | Where does the work arrive? | Claude Cowork, Slack, Teams, Discord, web app, email, scheduled routine, API trigger | Pilots live in chat but never enter the workflow |
| Orchestration layer | Who owns the next step? | Agent router, queue, worktree lane, event trigger, handoff rule | Agents step on each other or duplicate work |
| Skill layer | How should this job be done? | Sovereign skills with instructions, references, scripts, examples, and stop rules | Prompt libraries depend on the person using them |
| Tool layer | What can the agent touch? | MCP servers, connectors, local files, CRMs, docs, browser, code repo, warehouse | Tool permissions are too broad or too vague |
| Memory layer | What should persist? | Reference files, gbrain-style retrieval, feedback logs, approved examples, decision records | The agent relearns the same lesson every week |
| Governance layer | How do we prove control? | Logs, approvals, evals, red-team cases, cost and latency traces, incident review | The pilot cannot pass security or audit review |
This is where AI Heroes work tends to differ from generic AI consulting. We are not trying to make one beautiful demo agent. We are trying to make the dull parts explicit: the queue, the hook, the worktree, the review lane, the reference file, the escalation rule, the failed-run ledger. That is the stuff that keeps the tenth agent from corrupting the work of the ninth.
Single-agent vs multi-agent vs agent-fleet: which is right for the enterprise?
Most enterprises should start with single agents, graduate to multi-agent workflows only when decomposition creates real value, and reserve fleet architecture for repeatable work that crosses teams or runs on schedules.
| Pattern | Typical use case | Infrastructure required | Observability needed | Governance burden | Failure mode | AI Heroes pattern reference |
|---|---|---|---|---|---|---|
| Single agent | Draft a renewal summary, classify support tickets, prepare a meeting brief | One skill, one tool set, one approval path | Transcript and output review | Low to medium | The agent becomes a personal assistant instead of a reusable capability | Skills and reference files |
| Multi-agent workflow | Research, draft, review, and publish a campaign or code change | Router, handoffs, role prompts, shared context | Per-agent logs plus handoff trace | Medium | Agents disagree silently or overwrite each other | Parallel worktree orchestration |
| Agent fleet | Department-level or company-wide operations across sales, legal, finance, product, support, and engineering | Gateway, queues, schedules, MCP/connectors, memory, evals, cost controls | Central event logs, eval dashboards, incident review, usage analytics | High | Shadow automation spreads before control exists | OpenClaw-style fleet operations |
The decision is not ideological. Single agents are underrated when the work is bounded. Multi-agent systems are overrated when the handoff adds more coordination cost than value. Fleets are unavoidable when agents become part of the operating rhythm of a 1,000-person company.
How do you scaffold sovereign agent skills for an enterprise?
A sovereign skill is a workflow the organization owns. It is not just a saved prompt, and it is not just a vendor feature. It is the encoded version of how a team wants work done.
In practice, the skill should include six assets.
The first asset is the operating procedure: what the agent should do, in what order, and where it should stop. The second is the reference pack: policy, brand voice, product taxonomy, contract clauses, pricing rules, reporting standards, or examples of approved work. The third is the tool contract: which systems the agent may read, write, call, or never touch. The fourth is the review rule: which outputs can ship, which need approval, and what proof the reviewer sees. The fifth is the eval set: known tasks, expected outputs, edge cases, and regression checks. The sixth is the update loop: how expert corrections become changes to the skill, not one-off comments in a chat thread.
This is why we talk about skills as institutional infrastructure. A skill captures the judgment behind the work. A plugin packages that skill with connectors and agents so a team can use it repeatedly. An MCP server connects it to the systems where the facts live. A memory layer lets the skill improve without becoming a junk drawer.
When a skill is built well, the business stops asking, "Who knows how to do this?" and starts asking, "Which governed capability handles this?"
What governance does an enterprise agent rollout actually need?
Enterprise agent governance is not a policy PDF. It is a set of controls in the path of work. The controls have to be visible to the agent, the user, the manager, security, and audit.
| Anthropic playbook recommendation | What happens in production | AI Heroes refinement |
|---|---|---|
| Start with specific pilots and success criteria | Teams pick good pilots, then expand before the control model is ready | Define the tool boundary, approval path, owner, eval set, and rollback path before the pilot starts |
| Encode organizational knowledge into plugins and skills | The first version captures an expert's tacit knowledge, but nobody owns maintenance | Give every skill an owner, changelog, reference-file review cycle, and regression eval |
| Use MCP and connectors to reach business systems | Teams connect useful tools, then discover permissions do not map cleanly to agent actions | Split read, draft, write, send, and delete permissions into separate capabilities |
| Keep humans in the loop for sensitive work | Review becomes a vague promise rather than a blocking control | Make approval a tool-state transition: draft prepared, evidence attached, human approved, action executed |
| Measure adoption and impact | Dashboards count usage, but not whether the work improved | Track cycle time, accepted-output rate, override reasons, incident rate, cost per completed workflow, and business metric movement |
The uncomfortable truth is that governance slows down the first two weeks and speeds up the next six months. Without it, every new use case re-litigates security, permissions, and quality. With it, the next team inherits a pattern that has already survived contact with legal, finance, and IT.
How do you measure ROI on an enterprise agent program?
Measure agent ROI at the workflow level first and the enterprise level second. A company-wide "AI productivity" number is usually too soft to steer implementation. A workflow-level scorecard tells you whether a specific agent deserves to scale.
Start with five measures.
Cycle-time compression shows whether the work moved faster. Accepted-output rate shows whether humans trust the result enough to use it. Human-review time shows whether the agent is reducing expert load or just creating editing work. Cost per completed workflow keeps model, tool, and orchestration costs honest. Business movement connects the agent to revenue, margin, risk reduction, customer satisfaction, or product velocity.
Then add three governance measures: incident rate, override reasons, and stale-reference age. These are the metrics that tell you whether the agent remains controllable as more people use it.
The strongest ROI cases are rarely pure headcount-reduction stories. They are capacity stories. The legal team handles more contracts without lowering review quality. The support team resolves more cases without burning out agents. The product team ships more research-backed decisions because the research work is always running. The sales team spends less time assembling account context and more time in the conversation.
How should a 1,000-person company roll out Claude agents in 2026?
A 1,000-person company should roll out enterprise agents in four phases: pick two workflow pilots, turn the winning pilot into a governed skill, package it as a reusable plugin or internal capability, then expand through a controlled fleet model.
In month one, pick workflows where the pain is obvious and the finish line is measurable. Good candidates are renewal summaries, first-pass contract review, support triage, sales account research, finance variance notes, engineering backlog hygiene, or regulated document assembly. Bad candidates are vague mandates like "make marketing more productive."
In month two, build the skill properly. Include the reference files, tool boundary, eval set, approval path, logs, and owner. Treat this as the production prototype, not a demo.
In months three and four, package the winning workflow for reuse. If Claude Cowork is the surface, that usually means plugins and connectors. If the workflow runs outside Cowork, it may mean an internal agent runner, OpenClaw-style orchestration, scheduled routines, or an MCP-backed service. The exact stack matters less than the control model.
In months five and six, expand from one workflow to a small fleet. Add adjacent departments only when the first workflow has evidence: accepted-output rate, cycle-time reduction, low incident rate, and a clear owner. This is where the organization begins to compound. The second skill borrows the first skill's governance pattern. The third borrows the eval harness. The fourth borrows the memory discipline.
That is how Anthropic's enterprise playbook becomes a real operating system. The model provides the reasoning. The enterprise provides the judgment. The implementation layer makes that judgment reusable.
Related reading on enterprise agent implementation
- Claude skills and agent workflows: why prompts are not enough
- OpenClaw vs Claude Code: choosing the right agent control surface
- Claude Code vs ChatGPT Codex: collaborate or delegate?
- Microsoft Copilot Cowork vs Claude Code: two floors nobody automated
- gbrain vs qmd: benchmarking agent memory on 150 real questions
- AI Heroes AI solutions for businesses
The agent built for this

Richard
A forward-deployed AI agent that gets your software live and adopted inside every customer.
Meet RichardFrequently Asked Questions

Founder, AI Heroes
I build AI companies and the systems inside them. At AI Heroes, we give businesses the functional capacity to grow without the headcount growth normally demands — sales that follows up, marketing that runs, content that ships, ops that handles itself. We audit where you're leaving growth on the table, build the team that captures it, and hand it over completely.
I've built at scale before. Leading product and GTM at SlideSpeak AI (1M+ monthly users, profitable, bootstrapped). CPO at Disperse — the AI construction platform that went from 3 to 200+ people on $35M raised. I also co-founded LOBOMAR, a luxury fashion label featured in Elle, Cosmopolitan, and the LA Times, with shows at the London Design Museum, Wereldmuseum, and Amsterdam Fashion Week.
Related Articles

What Is Claude Tag? How Anthropic's Slack AI Teammate Works (2026)
Anthropic launched Claude Tag on 23 June 2026: a way to work with Claude inside Slack as a shared, always-on teammate. Tag @Claude and it plans a task, uses the tools you grant it, and replies in-thread. It is multiplayer, learns from the channel, can take initiative, and works asynchronously over hours or days. It runs on Opus 4.8, is in beta for Enterprise and Team, and replaces the old Claude in Slack app.

Microsoft Scout, Explained: The Always-On 'Autopilot' Built on OpenClaw
Microsoft Scout is the first of a new category Microsoft calls 'Autopilots' — a Windows and macOS desktop agent that acts on your files, shell, browser and Microsoft 365, and works autonomously in the background. Here's what's actually confirmed, what isn't, how to get it, and why it's built on the open-source OpenClaw framework.

How Claude Managed Agents Actually Work: Dreaming, Outcomes, Multiagent Orchestration, and Webhooks (2026)
Anthropic gave Claude Managed Agents four new mechanics at Code w/ Claude: Dreaming, Outcomes, Multiagent Orchestration, and Webhooks. The one that changes how you build is Outcomes — a separate grader that loops the agent until a rubric is met. Here is how each one works, and when to reach for it.