
The Prompt That Broke at Scale
It was a Thursday afternoon in Frankfurt, and Sarah was staring at two outputs on the same screen.
She was the COO of a sixty-person contract intelligence company — the kind of firm that sits between law firms and their enterprise clients, processing commercial agreements at scale. For the past eight months, Sarah had been building what she privately called "the prompt library." Hundreds of carefully tested instructions, each one refined through trial and error, each one covering a different scenario: NDAs, vendor agreements, force majeure clauses, change-of-control provisions. Her team used Claude to summarize, flag, and classify. The time savings were real. Then she started sharing the prompts across the team.
The output from one analyst was crisp, structured, accurate. The output from another — using the same prompt, on the same clause, on a near-identical contract — was incomplete. It missed a critical indemnity cap. Sarah read the prompt again. There was nothing wrong with it.
That was the moment she stopped optimizing the wrong layer.
What Eight Months of Prompt Engineering Actually Produces
There is a belief, widespread enough to be called consensus, that the quality of AI output is a function of prompt quality. Spend more time on your prompts, get better outputs. It is not wrong, exactly. But it is dangerously incomplete.
What Sarah had built — what most founders and ops leaders build in the first year of AI adoption — is personal prompt expertise. The prompt library worked brilliantly for her because she understood, implicitly, the ten assumptions baked into every instruction. She knew which contract type each prompt applied to, which jurisdiction caveats to mentally apply, which edge cases the prompt couldn't handle. When she handed the prompt to one analyst, some of that knowledge transferred. When she handed it to another, less did. The prompt was legible. The context wasn't.
This is the gap that kills most enterprise AI implementations: the instruction is portable, but the judgment behind it isn't.
Claude skills — structured instruction files that combine a process document, grounding references, and optional code scripts — are an architectural answer to this problem. Not a better prompt. A different layer entirely. And when those skills are built and deployed using Claude Code, Anthropic's agentic system for building agent workflows, the result is something operations teams increasingly call a plugin: a modular, packaged capability any agent can call on demand.
The Architecture Nobody Draws on the Whiteboard
A head of revenue operations at a London fintech that processed expense reports and supplier invoices for mid-market businesses had gone the opposite route from Sarah. He'd built Zapier workflows, then Make.com flows, then a custom webhook pipeline that routed documents through an OCR engine before passing them to a classification API. Deterministic. Reliable. Fast — as long as the inputs stayed inside the rails.
Then his largest client started sending scanned PDFs with handwritten amendments. Then another client began embedding contract changes in email threads rather than attaching revised documents. The pipeline didn't fail dramatically. It just started routing everything uncertain to the human review queue. Within six weeks, the human review queue had become larger than the original manual process.
He had built a system that worked at the average and failed at the edges. The edges were where the money was.
What both had missed was the middle layer — what practitioners building production AI systems have started calling sovereign agent skills. The anatomy is specific: a skill.md file that outlines the step-by-step execution logic (the equivalent of a dynamic SOP); a set of reference files that ground the agent in company-specific reality (style guides, ICPs, product taxonomies, historical examples); and optionally, lightweight scripts that handle strictly deterministic tasks within a judgment-driven flow.
An AI operations lead at a Berlin HR platform serving mid-market manufacturing clients had built exactly this architecture for her company's candidate briefing process, using Claude Code to wire together the execution logic, reference files, and tool connections. The skill walked the agent through five steps: parse the job requirements, cross-reference the internal salary band file, check the ATS for prior applications from the candidate's network, draft the briefing in the house format, and flag anything requiring human sign-off. The reference files held the voice guide, the job-family taxonomy, and a curated archive of approved briefings. Once deployed as a plugin within their agent environment, the output was consistent enough to use directly in client meetings.
"The first time we ran it without editing the output," she said, "was six months after we started. That was the day we knew we'd built something different from a prompt."
Skills, Plugins, and Why the Distinction Matters
There is a terminology distinction worth nailing down, because it changes how teams think about what they're building.
A skill is the architecture: the skill.md, the reference files, the optional scripts. A plugin is that architecture packaged and deployed — made callable by any agent, shareable across a team, composable with other skills. All plugins are skills. But a skill that lives in a shared folder as three loose files is not yet a plugin. It becomes a plugin when it is wired into an agent environment so that any trigger — a user instruction, a scheduled task, an upstream workflow — can invoke it without human setup.
This distinction matters because it is the difference between building a better tool and building institutional infrastructure. Sarah's prompt library was a collection of tools. The architecture she eventually built, using Claude Code to connect her clause taxonomy, jurisdiction flags, and review checklist into a single callable unit, was infrastructure. The knowledge moved from inside her team's heads into something the organization owned.
When her firm's headcount doubled the following year, onboarding a new analyst onto the contract review workflow took a morning instead of six weeks. Not because the new hire was exceptional. Because the plugin was.
Why Consistent Output Is Harder Than Good Output
The counterintuitive finding, when you examine where AI implementations actually stall inside organizations, is that quality is rarely the problem. Most modern language models produce output that is, in isolation, impressive. The problem is reproducibility — the same quality at scale, across different users, on different days, with different inputs.
A skill solves the reproducibility problem by moving institutional knowledge from inside people's heads — where it is implicit, inconsistent, and non-transferable — into structured files that any authorized agent call can access. The knowledge becomes organizational, not personal. When Sarah finally rebuilt her contract analysis workflow as a skill, she included a clause_taxonomy.md reference file, a jurisdiction_flags.md document covering the firm's most common contracts, and a review_checklist.md that enforced output structure. The same instruction now produced the same output regardless of who triggered it.
The skill does not remove human judgment from the loop. It removes the human from the position of being the loop.
Where This Breaks
The architecture has a real limit, and it is worth naming.
If the underlying SOP is wrong — if the process the skill.md encodes is itself flawed — the skill automates the error at scale. Sarah's contract analysis improved dramatically once the skill was built. But only because the underlying logic had been tested manually for eight months first. An organization that builds a skill on top of an untested process will get consistently wrong outputs delivered very efficiently.
The sequence matters: manual process first, edge cases identified, judgment documented, then formalized into a skill. Building the skill before you've done the manual work is like writing a quality manual before you know what quality looks like.
The Question Hiding in Every Prompt Library
Sarah still has the prompt library. She hasn't deleted it. But she uses it differently now — as raw material for skill construction, not as the final product. Each prompt is a rough draft of a reference file or an execution step, not a deployable asset.
The question most founders and ops leaders are not yet asking is not "how do we write better prompts?" It is: how do we make the knowledge behind our prompts portable?
The answer is a file. Specifically, three of them. And a Claude Code deployment to connect them.
That's what AI Heroes builds. Not prompt libraries. Portable judgment infrastructure — skills that encode your team's expertise into modular, reliable, compounding systems. The kind of architecture that works whether Sarah runs it or someone who started last Tuesday does.
The agent built for this

Richard
A forward-deployed AI agent that gets your software live and adopted inside every customer.
Meet RichardFrequently Asked Questions

Founder, AI Heroes
I build AI companies and the systems inside them. At AI Heroes, we give businesses the functional capacity to grow without the headcount growth normally demands — sales that follows up, marketing that runs, content that ships, ops that handles itself. We audit where you're leaving growth on the table, build the team that captures it, and hand it over completely.
I've built at scale before. Leading product and GTM at SlideSpeak AI (1M+ monthly users, profitable, bootstrapped). CPO at Disperse — the AI construction platform that went from 3 to 200+ people on $35M raised. I also co-founded LOBOMAR, a luxury fashion label featured in Elle, Cosmopolitan, and the LA Times, with shows at the London Design Museum, Wereldmuseum, and Amsterdam Fashion Week.
Related Articles
How to Run an AI-Native Engineering Org in 2026
Agentic coding doesn't remove the engineering bottleneck — it moves it from writing code to verifying it. Here's the 2026 operating model for an AI-native engineering organization: the processes to rewrite, how code review changes, and the metrics that prove it's working.
Claude Code Dynamic Workflows: What Is Actually New in 2026?
Claude Code dynamic workflows are not just parallel agents. They turn a prompt into an executable orchestration script that can split work, store intermediate results, cross-check findings and return one synthesised answer.
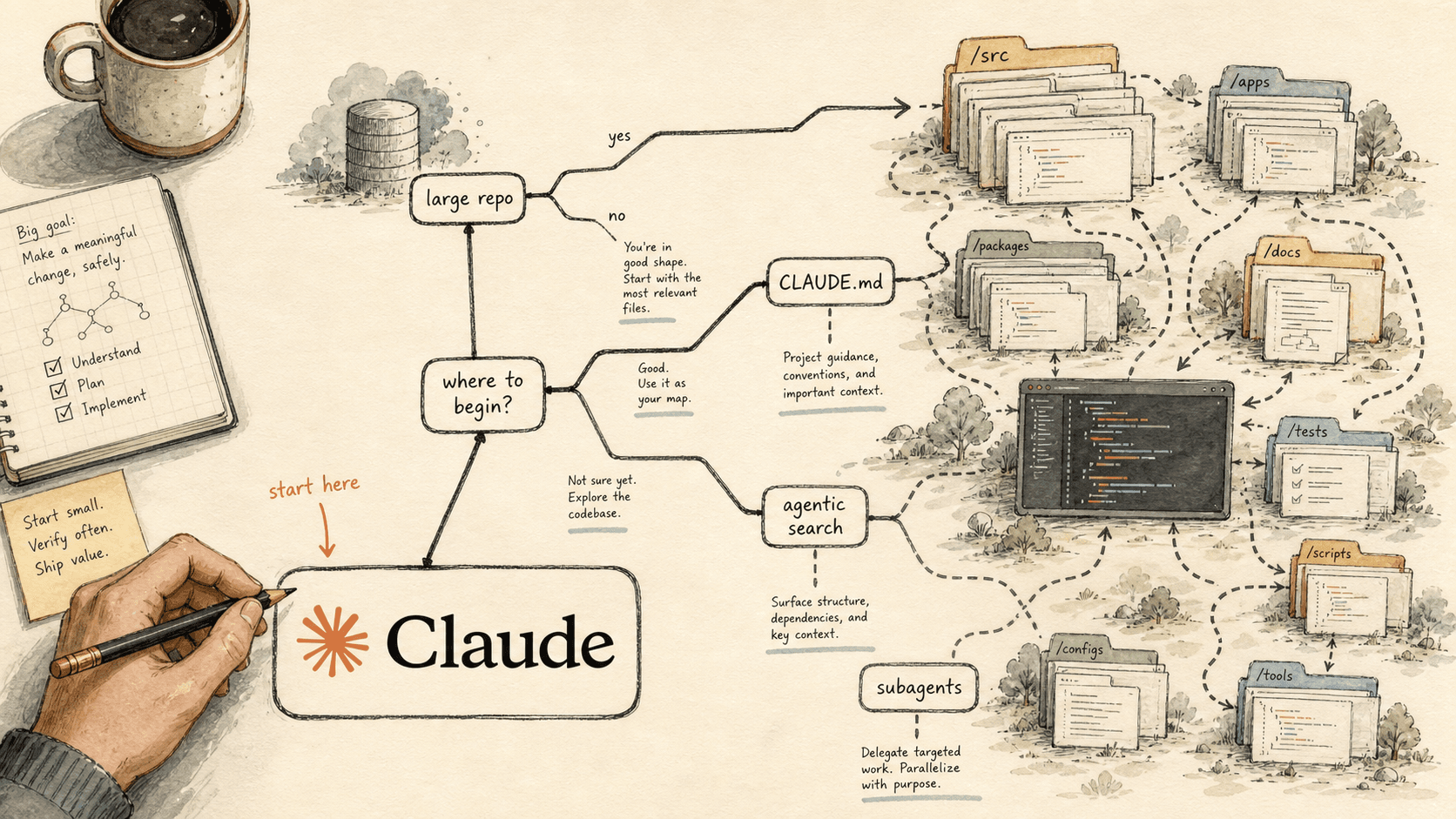
Where to Start With Claude Code in a Large Repo: A Decision Tree (2026)
You do not start a large Claude Code rollout by configuring everything. You start with the one mechanic your repo shape and your actual pain point demand — and ignore the rest until you hit them. This is the decision layer that runs before the build.