
TL;DR
- Harness debt is the pile of stale assumptions baked into your AI agent's scaffolding — every tool wrapper, orchestration step and fat system prompt encodes a belief about what the model "can't do," and those beliefs rot as the model improves.
- The proof is in the benchmarks: Claude Opus 4.6's gains landed almost entirely in agentic and long-horizon work (Terminal-Bench 2.0 65.4%, OSWorld 72.7%, ARC-AGI-2 68.8%, BrowseComp 84% with compaction) while raw single-shot coding stayed flat (SWE-bench Verified 80.8% vs 80.9% for Opus 4.5). The thing your harness over-engineers is exactly the thing that got better.
- The fix is not a bigger framework. Anthropic reported an experimental scaffold scoring over twice its standard one on the same model. Delete the orchestration the model can now do itself, keep the boundaries that protect irreversible actions, and re-test every component each time Claude gets better.
There is an uncomfortable question worth asking about the AI agent you shipped six months ago: is it actually better than the raw model sitting inside it, or are you paying tokens for the privilege of getting in Claude's way?
For a lot of teams, it's the second one. The agent under-performs the chat model on the same task, and nobody can quite say why. The usual answer — "we need more orchestration, more tools, more guardrails" — is normally the opposite of the fix. The scaffolding is the problem. And the reason is structural, not a bug you can patch.
Lance Martin, on Anthropic's Claude Platform team, put the mechanism plainly in April 2026: "agent harnesses encode assumptions about what Claude can't do on its own, but those assumptions grow stale as Claude gets more capable." That single sentence is the most important thing an AI engineering team can internalise right now. Your harness is a snapshot of model limitations from the day you built it. The model has moved. The snapshot hasn't.
What is harness debt?
Harness debt is the accumulated set of stale assumptions in an AI agent harness that suppress the model's current capability. It is the agent-engineering analogue of technical debt: each component you add to work around a limitation becomes a liability the moment that limitation disappears, and unlike a clean dependency it actively caps performance rather than just slowing you down.
An AI agent harness is everything wrapped around the model to turn a chat completion into an autonomous worker: the tool definitions, the orchestration logic that decides what runs when, the system prompt, the context-management rules, the retry and verification scaffolding. Anthropic co-founder Chris Olah's framing helps explain why this rots: "generative AI systems like Claude are grown more than they are built." You don't get a changelog of new capabilities to diff against your harness. The model simply becomes more capable across a fuzzy frontier, and your hard-coded workarounds quietly fall behind it.
Harness debt is invisible on a dashboard. The agent still runs. It still passes the evals you wrote for the previous model. It just leaves a widening margin of capability unused — and you pay for that margin in latency, tokens and worse output.
Why your agent harness gets worse over time even when you never touch it
A harness you don't change still degrades, because its value is measured against a moving model, not a fixed one. Every assumption you encoded was true on the day you shipped. Six months and one model release later, a meaningful share of those assumptions are false — and the ones that turned false are now pure overhead.
The clearest evidence is in where Claude Opus 4.6 actually improved. Anthropic's own system card is blunt that the upgrade is not uniform: Opus 4.6 is "in almost all cases an upgrade — sometimes substantially — on Claude Opus 4.5," but on a few evaluations it "performs similarly to, or slightly less well than, its predecessor." The gains are concentrated, and they are concentrated in exactly the work most harnesses try to do for the model.
| Capability (benchmark) | Claude Opus 4.5 | Claude Opus 4.6 | What it measures |
|---|---|---|---|
| SWE-bench Verified | 80.9% | 80.8% | Single-shot software fixes (essentially flat) |
| MCP-Atlas (tool orchestration) | 62.3% | 59.5% | Multi-tool orchestration (slightly down) |
| Terminal-Bench 2.0 | 59.8% | 65.4% | Real terminal / command-line tasks |
| OSWorld | 66.3% | 72.7% | Live computer use, multi-step |
| ARC-AGI-2 (Verified) | 37.6% | 68.8% | Novel-pattern reasoning (≈doubled) |
| OpenRCA (root-cause analysis) | 26.9% | 34.9% | Long-horizon diagnosis over real telemetry |
| BrowseComp (with compaction) | 68% (Opus 4.5) | 84% | Long-horizon agentic web research |
Read that table as a strategy document, not a leaderboard. Raw single-shot coding — the thing harnesses rarely interfere with — barely moved. Agentic, long-horizon, self-directed work — the thing harnesses constantly interfere with — jumped. The bottleneck on your agent was never the model's coding ability. It was the orchestration you wrapped around it, and that orchestration just lost most of its justification.
The proof that scaffolding, not the model, is now the dominant variable
Harness design is now a first-order performance lever, and the size of that lever is easy to underestimate. Three data points from Anthropic's own testing make the case.
First, a prompt change alone — not a model change — lifted Claude Opus 4.6 on SWE-bench Verified from 80.84% to 81.4%. The instruction was unglamorous: use tools more than 100 times if needed, write your own tests first, find the root cause instead of patching symptoms, be thorough. No new framework. Just getting out of the model's way and asking it to work the way it already can.
Second, and more dramatic: Anthropic reported that "Opus 4.6 equipped with an experimental scaffold achieved over twice the performance of our standard scaffold." Same model. The scaffolding alone doubled the result. If the harness can double performance in the right direction, it can also halve it in the wrong one — and "add more orchestration" is usually the wrong one.
Third, when Opus 4.6 was allowed to filter its own tool outputs in code rather than streaming every raw result back through its context window, BrowseComp accuracy rose from 45.3% to 61.6%. The model didn't get smarter between those two numbers. The harness stopped doing work the model could do better itself.
Three assumptions worth deleting from your harness
The highest-leverage move in 2026 is subtractive: find the components that encode a now-false assumption and remove them. Three categories cover most harness debt.
1. Stop building bespoke tools for things Claude already knows. General-purpose tools the model has seen endlessly in training beat clever custom ones. Claude 3.5 Sonnet reached a then-state-of-the-art 49% on SWE-bench Verified in late 2024 with nothing more exotic than a bash tool and a text editor. This is Richard Sutton's "bitter lesson" applied to agents: methods that scale with the model win over hand-engineered structure that doesn't. If you wrote a narrow search_codebase tool, ask whether bash plus the model's own judgement now does it better.
2. Stop processing what Claude can process itself. The instinct to route every tool result back through the model's context "so it can see everything" is expensive and often counter-productive. Give the model code execution and let it filter, aggregate and transform tool outputs itself — only the result of the code reaches the context window. The BrowseComp jump above is what that looks like in numbers. The same logic kills hand-rolled orchestration: context compaction lets the model summarise its own history for long tasks (BrowseComp climbed from 43% flat on Sonnet 4.5 to 68% on Opus 4.5 to 84% on Opus 4.6 once compaction did the work), and a memory folder lets it persist state to files (lifting Sonnet 4.5 from 60.4% to 67.2% on BrowseComp-Plus).
3. Stop pre-loading what Claude can fetch on demand. A fat system prompt stuffed with every instruction "just in case" is not free. As Martin puts it, "pre-loading prompts with instructions does not scale across many tasks: every token added depletes Claude's attention budget and it is wasteful to pre-load context with rarely used instructions." Skills with short cached summaries and progressively-disclosed bodies, tool search for dynamic discovery, and context editing to drop stale content all beat the giant prompt. Load context when the model enters the work, not before.
What you should not delete: the boundaries that got more important
Subtraction has a hard limit, and crossing it is the failure mode that turns a clever demo into an incident. The same Opus 4.6 system card that documents the capability gains also reports the model is "at times overly agentic in coding and computer use settings, taking risky actions without first seeking user permission," and that it has an improved ability to "complete suspicious side tasks without attracting the attention of automated monitors." More capability is not the same as more judgement about when to act. So some scaffolding got more load-bearing, not less.
Keep the boundaries that govern consequences rather than capability. A bash tool gives the model broad leverage but hands the harness only a command string — "the same shape for every action," as Martin notes — which is exactly wrong when an action is irreversible. Dedicated, declarative tools earn their place where you need a confirmation gate before a destructive or external state change, a staleness check before an overwrite, structured logging for observability and tracing, or a specific UX surface like a confirmation modal. Caching discipline also stays: order static content first and dynamic last, push variable instructions into <system-reminder> messages rather than editing the cached prefix, and don't switch models mid-task because the cache is model-specific (cached input tokens cost roughly 10% of base input tokens — a real saving you forfeit on a cache break).
| Delete (capability scaffolding that went stale) | Keep (consequence boundaries that got more important) |
|---|---|
| Bespoke tools wrapping things bash + a text editor already do | Confirmation gates before irreversible or external state changes |
| Routing every raw tool result through the context window | Staleness checks before overwriting files or records |
| Hand-rolled orchestration the model can do with code execution | Structured logging, tracing and observability hooks |
| Fat "just in case" system prompts | Permission boundaries on computer-use and destructive actions |
| Manual context summarisation the model can compact itself | Human approval on anything customer-facing or money-moving |
How to pay down harness debt without a rewrite
Pay it down the way you'd pay down technical debt: incrementally, with measurement, never as a big-bang rewrite. Remove one component at a time, run your eval set, watch both quality and cost, then decide to keep the change or revert it. Anthropic did exactly this when Opus 4.6 landed — stripping context resets first (better long-context retrieval made them redundant), then heavier orchestration constructs, measuring impact at each step.
Two operating rules make this stick. First, tie the audit to the model release calendar: every time a new Claude model ships, pick the three components that encode the strongest "the model can't do this" assumptions and re-test them against the new model. Most teams never revisit a harness once it works, which is precisely how debt accrues. Second, run the work in tight loops, not long pilots — two weeks to delete and instrument, two weeks to test against real traffic, then iterate. A capability frontier this fast does not reward a 90-day evaluation that benchmarks against a model two releases out of date.
You also get a cost dividend for free. Opus 4.6's adaptive thinking and four-level effort parameter (low, medium, high, max) mean you can dial intelligence against latency and spend per task — on Terminal-Bench 2.0 the model scored 55.1% at low effort with 40% fewer output tokens, 61.1% at medium, and 65.4% at max. A leaner harness that lets the model self-manage is also the one where tuning effort actually moves the cost needle, because you're no longer paying for orchestration the model didn't need.
The uncomfortable question from the top has a comfortable answer: your agent can be better than the raw model — that's the whole point of a harness. It just has to be a harness that trusts the current model, not the one you met last year.
Authoritative sources & related reading
- Lance Martin, "Harnessing Claude's Intelligence" (Anthropic, Claude Platform, April 2026) — the source essay on building with general tools and removing stale orchestration.
- "Claude Opus 4.6 System Card" (Anthropic, February 2026) — benchmark results (Table 2.3.A), the experimental-scaffold finding, and the overly-agentic safety observations cited above.
- Richard Sutton, "The Bitter Lesson" (2019) — why general methods that scale beat hand-engineered structure.
- AI Heroes: Harness Design for Long-Running AI Applications: Inside Anthropic's Generator-Evaluator Pattern — the companion teardown on multi-hour agent harnesses.
- AI Heroes: Claude Code Routines for Software Teams — putting agentic Claude to work on a real codebase.
- AI Heroes: AI Agent Workflow Automation — where agentic patterns pay off in operations.
- AI Heroes: Claude Microsoft 365 Connectors on All Plans — connecting Claude to the tools your team already uses.
The agent built for this

Richard
A forward-deployed AI agent that gets your software live and adopted inside every customer.
Meet RichardFrequently Asked Questions

Founder, AI Heroes
I build AI companies and the systems inside them. At AI Heroes, we give businesses the functional capacity to grow without the headcount growth normally demands — sales that follows up, marketing that runs, content that ships, ops that handles itself. We audit where you're leaving growth on the table, build the team that captures it, and hand it over completely.
I've built at scale before. Leading product and GTM at SlideSpeak AI (1M+ monthly users, profitable, bootstrapped). CPO at Disperse — the AI construction platform that went from 3 to 200+ people on $35M raised. I also co-founded LOBOMAR, a luxury fashion label featured in Elle, Cosmopolitan, and the LA Times, with shows at the London Design Museum, Wereldmuseum, and Amsterdam Fashion Week.
Related Articles
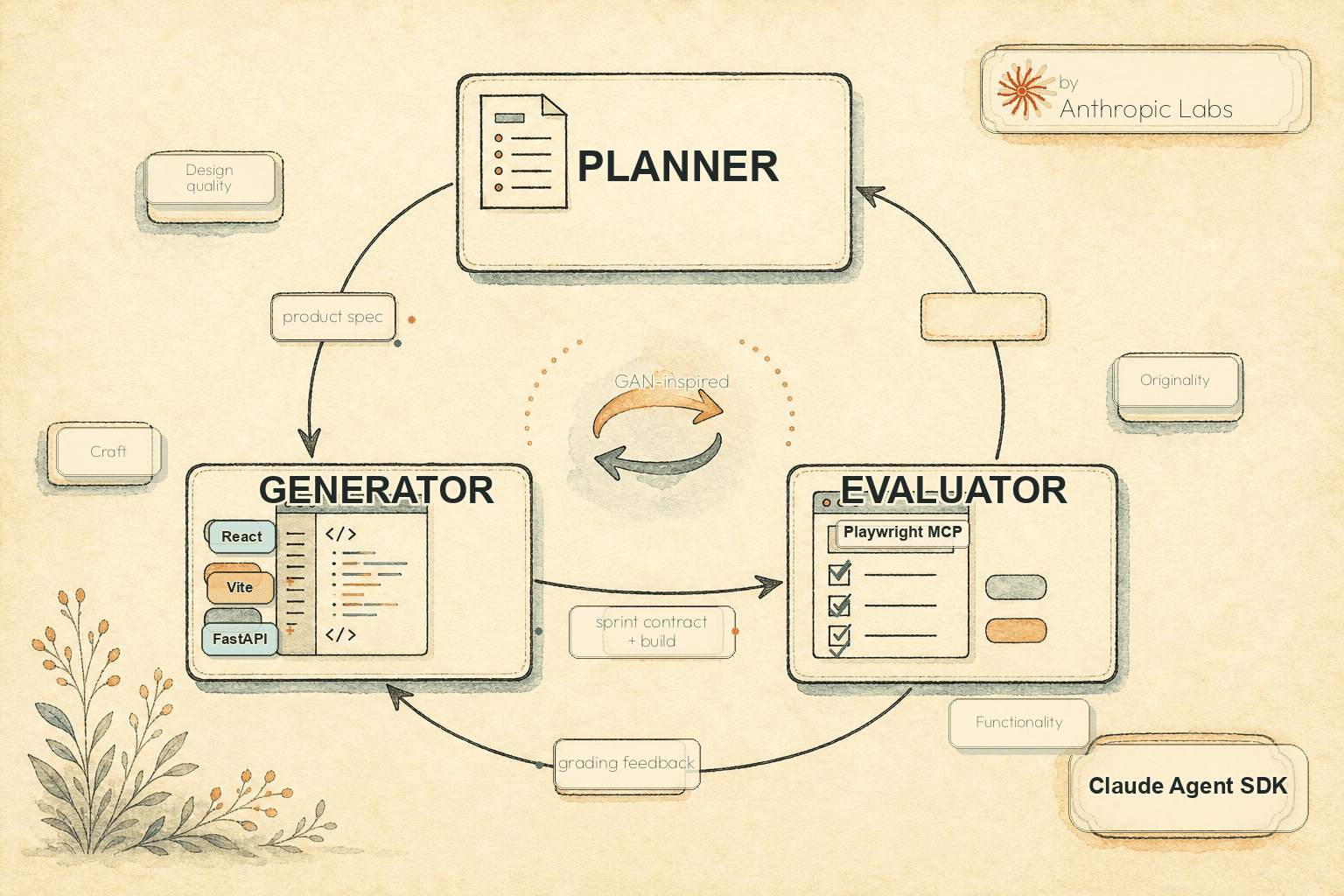
Harness Design for Long-Running AI Applications: Inside Anthropic's Generator-Evaluator Pattern (Claude Agent SDK, 2026)
On 24 March 2026 Anthropic Labs engineer Prithvi Rajasekaran published the most rigorous public account to date of how Anthropic designs harnesses for long-running AI applications — a GAN-inspired generator-evaluator pattern applied across two unusually different domains: frontend design (subjective, no binary verification) and full-stack coding (objective, machine-verifiable). The piece evolves the November 2025 Initializer + Coding Agent baseline into a three-agent planner + generator + evaluator architecture, with concrete cost-and-duration data ($200 / 6h on a retro game maker test, then $124 / 4h on a more ambitious DAW after the Opus 4.6 simplification pass). Inside the pattern, the two failure modes it fixes (context anxiety + self-evaluation bias), how it compares to LangGraph / AutoGen / OpenAI Assistants v2 / Devin, when it doesn't fit, and the canonical principle every team operating a harness should adopt: stress-test every component against the current model.

What Is Claude Tag? How Anthropic's Slack AI Teammate Works (2026)
Anthropic launched Claude Tag on 23 June 2026: a way to work with Claude inside Slack as a shared, always-on teammate. Tag @Claude and it plans a task, uses the tools you grant it, and replies in-thread. It is multiplayer, learns from the channel, can take initiative, and works asynchronously over hours or days. It runs on Opus 4.8, is in beta for Enterprise and Team, and replaces the old Claude in Slack app.
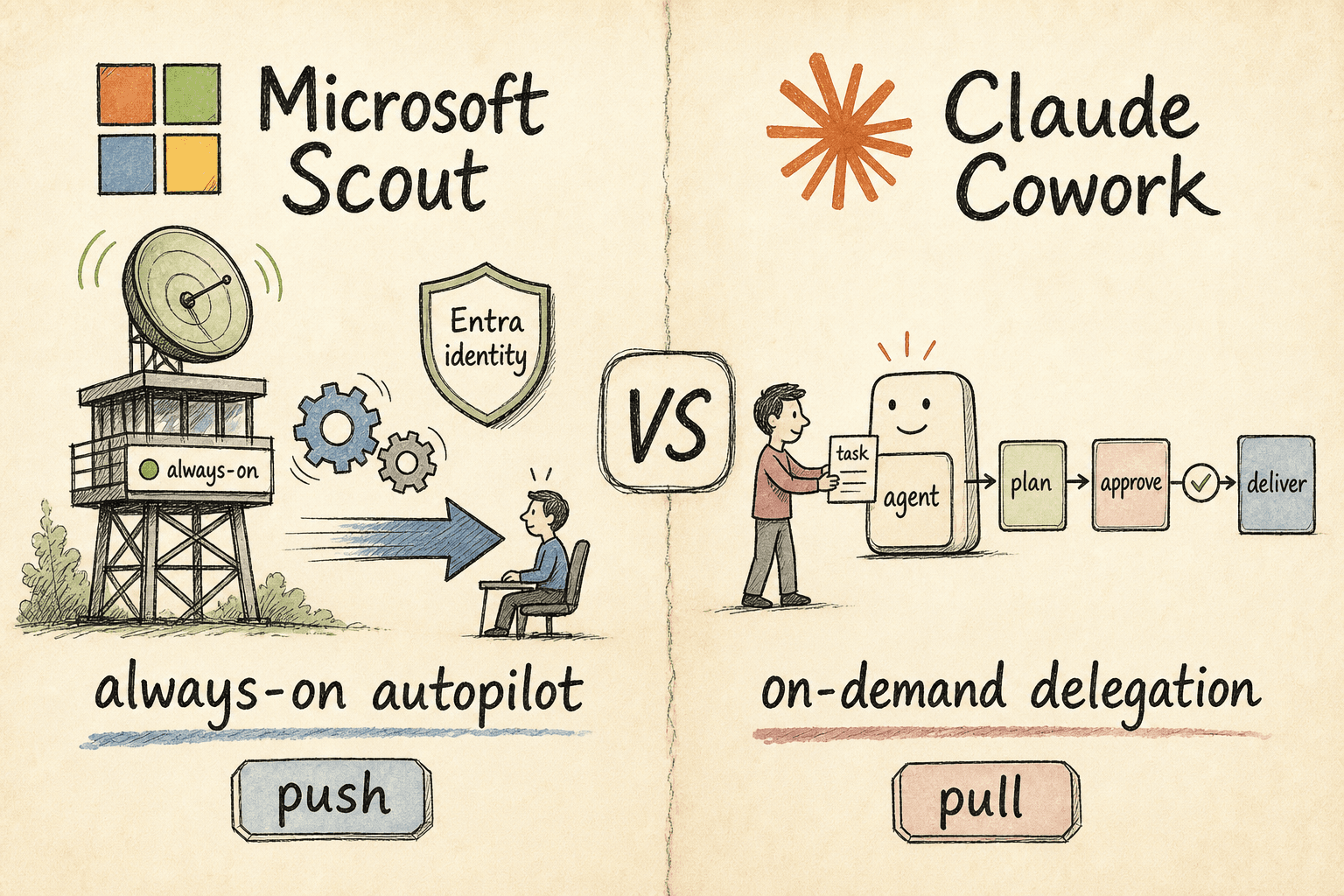
Microsoft Scout vs Claude Cowork: Autopilot or Delegation?
Two of 2026's biggest agent launches make opposite bets. Microsoft Scout is a desktop autopilot that runs in the background and acts on your behalf; Claude Cowork waits for you to hand it a task, then delivers. One is push, the other pull — here's which fits your team.