Claude Agent SDK
2 articles

Harness Debt: Your AI Agent Scaffolding Is Quietly Fighting the Model (2026)
Your AI agent is probably worse than the model inside it — and the gap is your own scaffolding. An experimental harness scored over 2x Anthropic's standard one on the same model. The fix isn't a bigger framework; it's deleting the assumptions that went stale the day Claude Opus 4.6 shipped.
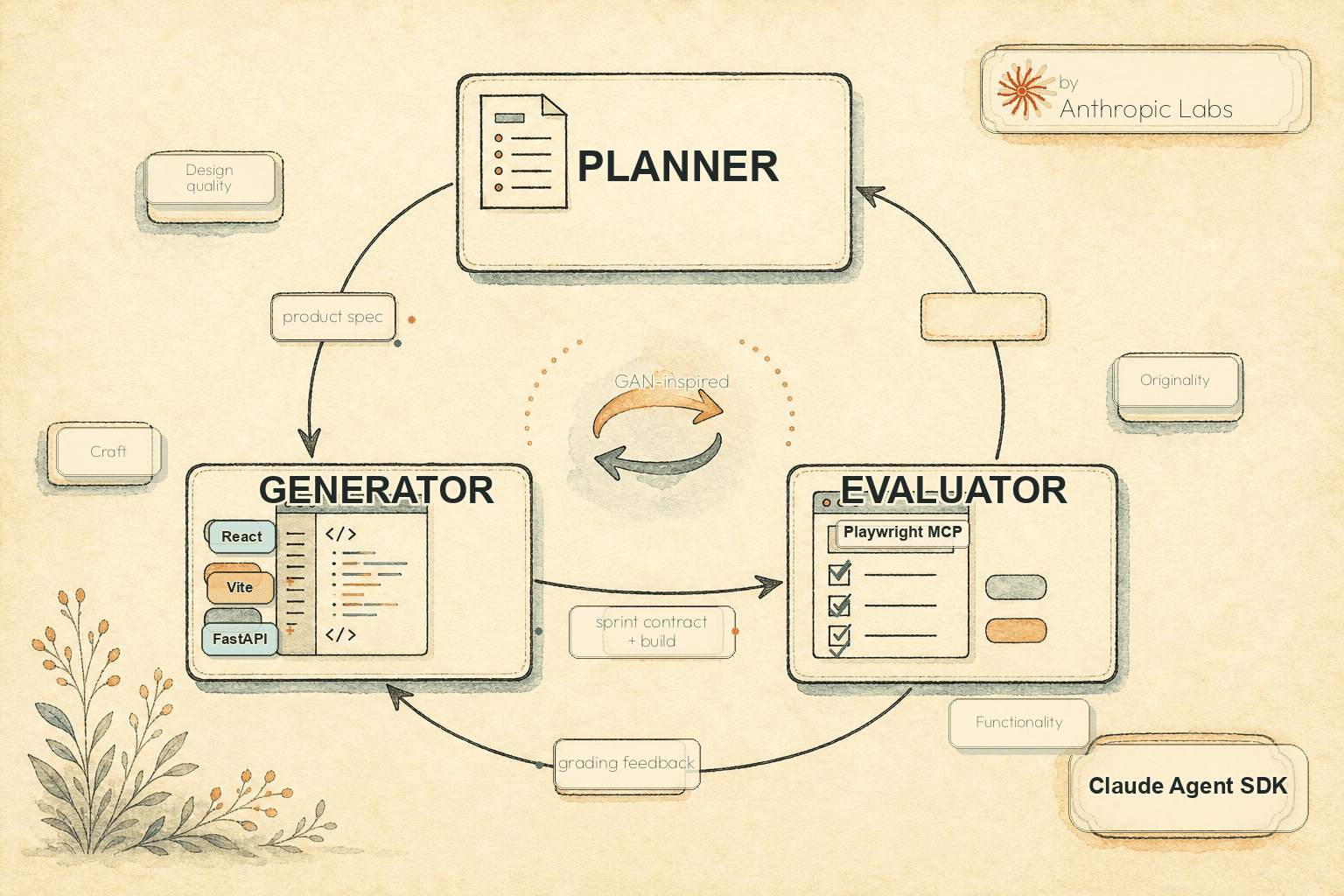
Harness Design for Long-Running AI Applications: Inside Anthropic's Generator-Evaluator Pattern (Claude Agent SDK, 2026)
On 24 March 2026 Anthropic Labs engineer Prithvi Rajasekaran published the most rigorous public account to date of how Anthropic designs harnesses for long-running AI applications — a GAN-inspired generator-evaluator pattern applied across two unusually different domains: frontend design (subjective, no binary verification) and full-stack coding (objective, machine-verifiable). The piece evolves the November 2025 Initializer + Coding Agent baseline into a three-agent planner + generator + evaluator architecture, with concrete cost-and-duration data ($200 / 6h on a retro game maker test, then $124 / 4h on a more ambitious DAW after the Opus 4.6 simplification pass). Inside the pattern, the two failure modes it fixes (context anxiety + self-evaluation bias), how it compares to LangGraph / AutoGen / OpenAI Assistants v2 / Devin, when it doesn't fit, and the canonical principle every team operating a harness should adopt: stress-test every component against the current model.