
The Queries That Broke the Pipeline
David pulled up the weekend report on a Monday at 7:40 a.m. He'd been running his Amsterdam logistics company's AI intake system for four months — a workflow that handled inbound client queries, categorized them, and routed them automatically. It had worked well. Better than well: the team of twelve had gone from spending forty percent of their week on intake triage to spending less than five percent.
The weekend report showed 47 queries processed. 40 handled without escalation. 7 flagged for human review.
He clicked through the 7.
One client was asking whether their contracted SLA still applied if the delay originated from a port strike covered under a force majeure clause they'd negotiated six months ago. Another was requesting a custom billing format that differed from their standard setup but matched a previous one-off arrangement. A third was escalating a damaged shipment query that had been misclassified twice already.
These were not unusual requests. In five years of running operations, David had handled variations of all three at least monthly. They were exactly the kinds of queries a senior coordinator handled instinctively.
His AI system had routed every single one to the queue marked "unable to determine — human required."
The Two Automation Disasters That Look Like Opposites
There is a diagram that most operations consultants draw when talking about AI adoption. On one end: rigid, deterministic automation — Zapier, Make.com, webhook pipelines. On the other: open-ended AI chat interfaces, Claude Projects, custom GPTs. The diagram implies that moving from left to right means gaining flexibility.
What the diagram doesn't show is that both ends share the same fundamental problem.
Rigid automation fails when the input doesn't fit the rule. David's intake system was built on this architecture: if a query contains "damaged shipment" and "insurance," route to claims. If it contains "customs" and "delay," route to compliance. When a query arrived that contained both sets of terms — a damaged shipment held at customs — the system froze. The query ended up in the human queue, which was supposed to be the fallback for genuinely novel situations, not for the fifteen percent of queries that required the agent to make a reasonable judgment call.
Open AI chat interfaces fail differently. They fail at the edges of consistency. A customer success lead at a Dublin SaaS company that helped recruitment agencies automate candidate processing ran into exactly this. Her team used a shared Claude Project to draft client-facing updates. The outputs were often excellent. They were also never quite the same twice. Different team members would get different formats, different tones, different levels of detail — because each session started from scratch, and the quality of the prompt varied with whoever was typing. The institutional knowledge — the firm's voice, the client relationship history, the acceptable format for different account tiers — existed nowhere but in the heads of the people who'd been doing the work longest.
Both failures have the same root cause: the human is still the guardrail. In rigid automation, a human has to catch what the rules missed. In open AI chat, a human has to compensate for what the model doesn't know. The agent is doing work, but it's doing work that immediately requires human correction. The efficiency gain is real but bounded.
The Layer That Sits in the Middle
What David built next was neither automation nor chat.
He worked with his lead coordinator — the person who actually handled the force majeure queries, the billing format exceptions, the multi-escalation edge cases — to map the judgment she applied. Not as a flowchart. As a skill: a skill.md file that contained the step-by-step logic her experience had encoded, combined with reference files that held the contractual frameworks she worked from, a client-tier classification document, and a file covering the known exception scenarios she'd encountered over four years.
The team used Claude Code, Anthropic's agentic system for building agent workflows, to wire together the execution logic, tool connections, and reference files into a deployed agent skill. The process took two weeks. What it produced was not a prompt and not a pipeline — it was something closer to a trained junior coordinator who had read every internal document the firm had ever written.
The skill did not automate her judgment. It made her judgment legible to the agent.
The result was not a perfect system. The 7 queries that required human review the following weekend were genuinely novel — situations even his lead coordinator hadn't encountered before. The queries that had previously been routed incorrectly now resolved without escalation. The edge cases that required human judgment now arrived at a human with the agent's preliminary analysis already attached: "This appears to be a force majeure scenario under Section 4.2 of the client's contract. Suggested response pathway attached. Requires authorization."
The coordinator's review time per escalation dropped from twenty minutes to four.
The Design That Prevents Context Overload
There is a second problem that emerges when you start building agent skills at scale, and it is more subtle than the first.
An AI implementation lead at a Brussels-based insurance broker that had been operating for twelve years had, over eight months, documented 23 distinct workflows as agent skills: policy renewal reminders, claims intake, broker-client communication, compliance documentation, provider comparison queries. Each skill was well-built. Each one performed well in isolation.
When the team loaded all 23 into a single agent environment, outputs degraded. The agent started conflating instructions from different skills. Response latency increased. Costs per query climbed.
The architectural pattern that resolved this is called progressive disclosure. Instead of loading the full content of every skill at agent startup, the agent is given only the metadata — the name of each skill and a one-sentence description of what it handles. The full skill.md and its reference files load only when the user triggers a specific task. An agent with access to 23 skills is not carrying the weight of all 23 simultaneously. It knows they exist. It loads what it needs, when it needs it.
Progressive disclosure — implemented through Claude Code's agent deployment architecture — allows a single agent to scale to hundreds of skills without the performance penalty that would otherwise make that scale prohibitive. The broker's system now handles 31 distinct workflows. Average response latency has not changed from what it was with three.
Where the Middle Layer Fails
The gap-filling architecture has a real limit.
It depends entirely on the quality of the skill's execution logic. When David's coordinator documented her judgment for the force majeure scenarios, she captured the variants she'd encountered. A variant she hadn't seen — a port strike triggered by regulatory action rather than industrial action — arrived six weeks later. The skill handled it confidently and incorrectly. The agent had been given clear rules and applied them to a situation the rules didn't cover.
Skills do not create judgment. They encode it. Any judgment that wasn't encoded during the skill-building process is judgment the agent doesn't have. This is not a flaw in the architecture — it is the architecture's honest boundary. The answer is a feedback loop: when a human overrides an agent recommendation, that override should update the reference files. The skill should improve. But that loop requires someone to own it, which most implementations do not yet have.
The Question David Stopped Asking
David no longer asks "what can the AI handle?" He asks a different question: "what judgment has been documented well enough to be portable?"
The queries his agent handles well are the ones where his team's accumulated expertise has been made legible — written down, structured, grounded in files the agent can actually read. The queries his agent escalates are the ones where the expertise is still only in someone's head.
The gap between those two categories is not a gap in model capability. It is a documentation problem. And documentation problems have always had a solution.
That's what AI Heroes builds. Not chatbots. Not pipelines. The structural layer between them — where the actual work lives, and where the actual judgment matters.
The agent built for this

Richard
A forward-deployed AI agent that gets your software live and adopted inside every customer.
Meet RichardFrequently Asked Questions

Founder, AI Heroes
I build AI companies and the systems inside them. At AI Heroes, we give businesses the functional capacity to grow without the headcount growth normally demands — sales that follows up, marketing that runs, content that ships, ops that handles itself. We audit where you're leaving growth on the table, build the team that captures it, and hand it over completely.
I've built at scale before. Leading product and GTM at SlideSpeak AI (1M+ monthly users, profitable, bootstrapped). CPO at Disperse — the AI construction platform that went from 3 to 200+ people on $35M raised. I also co-founded LOBOMAR, a luxury fashion label featured in Elle, Cosmopolitan, and the LA Times, with shows at the London Design Museum, Wereldmuseum, and Amsterdam Fashion Week.
Related Articles
How to Run an AI-Native Engineering Org in 2026
Agentic coding doesn't remove the engineering bottleneck — it moves it from writing code to verifying it. Here's the 2026 operating model for an AI-native engineering organization: the processes to rewrite, how code review changes, and the metrics that prove it's working.
Claude Code Dynamic Workflows: What Is Actually New in 2026?
Claude Code dynamic workflows are not just parallel agents. They turn a prompt into an executable orchestration script that can split work, store intermediate results, cross-check findings and return one synthesised answer.
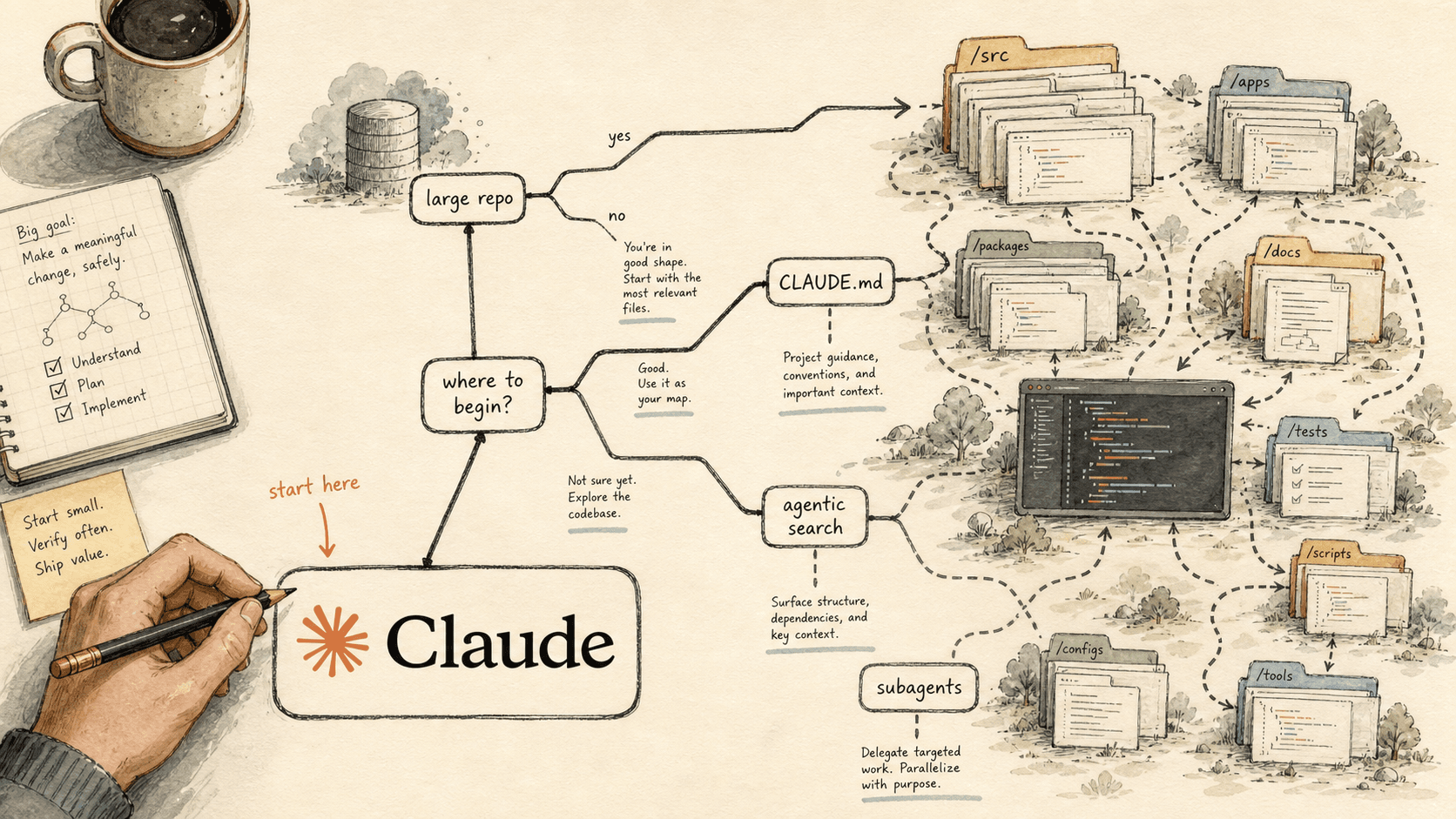
Where to Start With Claude Code in a Large Repo: A Decision Tree (2026)
You do not start a large Claude Code rollout by configuring everything. You start with the one mechanic your repo shape and your actual pain point demand — and ignore the rest until you hit them. This is the decision layer that runs before the build.