
The Nine-Month Rebuild That Took a Week
Rachel had spent nine months building something she was genuinely proud of.
She was the head of marketing at a London management consultancy — the kind of firm that advises mid-market companies on operational transformation, publishes thought leadership quarterly, and has a very specific way of talking about itself. Not generic. Not jargon-heavy. Direct, precise, occasionally dry. Over nine months, Rachel had fed their Claude Cowork environment everything: 40 back issues of the firm's newsletter, the brand voice guidelines, a living document of approved analogies and forbidden phrases, the bios of the three partners whose expertise the content needed to reflect.
The assistant knew them. It produced newsletters that sounded like the firm. It drafted client summaries in the correct register. New team members used it to calibrate their own writing. The training wheels had come off.
Then the platform changed its pricing.
The consultancy moved to a different provider. Rachel migrated the system in a weekend — or tried to. She imported what she could, re-entered the voice guidelines, attached the brand document. The first newsletter draft the new system produced was technically correct. It was also recognizably generic. The particular dryness was gone. The firm's habit of opening paragraphs with a specific kind of qualified assertion — "The evidence suggests, though rarely conclusively" — had vanished. Nine months of calibration had not survived the migration.
"It was like hiring someone new," Rachel said. "Except the new hire had all our documents and still didn't know us."
What You Think You're Building and What You're Actually Building
When marketing and ops leaders describe building an AI system inside Claude Cowork, they use the language of training. They say the model learned their voice. They say it knows their clients. They describe the process of feeding it documents and examples as a kind of education.
This is a useful metaphor and a misleading one.
What they are actually building is session context. The model does not learn from the documents in any persistent sense. It reads them, incorporates them for the duration of the session, and starts fresh when the session closes. The appearance of continuity — the sense that the AI knows you — is real within a session. Across sessions, it is an illusion maintained only by the consistency of the context you re-inject each time.
This distinction matters because the illusion is expensive to maintain and fragile when circumstances change. Rachel's nine months of calibration was nine months of curating the context she fed into a Claude Cowork project. The moment that context became inaccessible — because the platform changed, because the chat history was archived, because someone forgot to load the documents — the knowledge evaporated.
AI institutional knowledge doesn't live in the model. It lives in the files. The model is the engine. The files are the memory.
The Librarian Doesn't Memorize the Books
There is a reason the largest libraries in the world are not staffed by people who have memorized their collections. A librarian who has memorized every text in a single building is less useful than a librarian who knows exactly how any collection is organized and can retrieve any document in three minutes. The first approach doesn't scale. The second one does.
Agent reference files work on the librarian principle. The model doesn't need to memorize your brand voice. It needs to be able to retrieve your brand voice document, reliably, every time it writes copy. It doesn't need to hold your client taxonomy in training data. It needs a client_tiers.md file it can load when it's classifying a query.
A marketing manager at a B2B SaaS company in Stockholm that sold procurement software to manufacturing clients had exactly this problem. His team used a shared Claude Cowork assistant to draft weekly client updates. Each session, whoever was on rotation would open the tool, paste in the style guide, attach the relevant account notes, and begin. It worked. It also took eleven minutes before any useful output appeared, because those eleven minutes were spent re-establishing context that should have been persistent.
When he rebuilt the workflow using a Claude Cowork skill architecture — with a voice_guide.md, a client_profiles/ directory, and an escalation_flags.md that noted which account sensitivities to handle carefully — the setup time dropped to zero. The skill loaded the relevant client reference automatically based on which account name appeared in the task. The eleven-minute overhead disappeared. So did the variation that came from whoever happened to be on rotation forgetting to attach the account notes.
The Migration That Proved It
Rachel's experience after the platform migration was, at first, demoralizing. Then it became diagnostic.
The firm's new Claude Cowork setup used a skill architecture rather than a chat project. Rachel migrated the brand voice guidelines into a voice_and_tone.md reference file. The 40 newsletter back-issues were summarized into a newsletter_patterns.md document that captured recurring structural choices and the linguistic fingerprints that had made the original content recognizable. The partner bios became a partner_perspectives.md file that the skill referenced when drafting bylines.
The first newsletter produced by the rebuilt system was not as good as the best newsletter from the old one. But it was immediately recognizable as the firm's voice — something the cold start on the new platform had failed to achieve even after three attempts.
More importantly: when the firm upgraded to a new model eight months later, nothing broke. The reference files traveled. The skill.md was unchanged. The model was swapped; the institutional knowledge remained intact.
"We stopped thinking about it as training the AI," Rachel said. "We started thinking about it as maintaining the documents. That's a completely different job, and it's a job we already knew how to do."
The Loop That Compounds
An operations administrator at a small property management company in Edinburgh — 22 employees, several hundred residential units across Scotland — had, over two years, built something significant inside Claude Cowork.
The firm had a skill for tenancy communications, one for maintenance request triage, and one for regulatory compliance tracking. Each skill had reference files. The communications skill had a tone_guide.md, a common_scenarios.md covering the sixty most frequent query types, and a local_legislation.md that was updated quarterly.
What made the system durable was the feedback loop. When a human override occurred — when a staff member edited an AI-drafted communication significantly before sending — the administrator logged the override, identified which reference file should have prevented the error, and updated the document. Within six months, the quality of output had improved measurably. Within twelve, the override rate had dropped by half.
This is the self-improving loop that static Claude Cowork projects cannot replicate. The reference files are not frozen knowledge. They are living documents that compound with use. Each human correction becomes new institutional knowledge. The agent gets better not because the model improves but because the library grows.
The librarian doesn't need to know more. The library does.
Where This Architecture Has a Limit
The compounding loop requires active maintenance. Reference files that are not updated become stale. A voice_and_tone.md document written for a firm's 2023 positioning still governs output in 2025, even if the positioning has shifted. A common_scenarios.md that covers sixty situations from eighteen months ago does not automatically update when the sixty-first appears.
The most common failure mode in mature skill deployments is not technical degradation. It is reference drift — the slow divergence between what the files say and what the organization actually does. The skills keep working. They just keep working on a slightly outdated version of the company.
The fix is not complicated. It is a named owner, a quarterly review, and the discipline to treat the reference files as living documents rather than artifacts. Most organizations have people who do this for their employee handbook and their brand guidelines. They have not yet connected that job to their AI infrastructure.
The File Is the Memory
When Rachel started thinking of the brand voice document as infrastructure rather than content, something shifted.
The document stopped being something she updated before writing projects and became something she updated after them — a log of what the firm's best writing had revealed about how they thought. The AI didn't own the firm's voice. The document did. The AI just used it.
Nine months of recalibration after a platform change had felt like a failure. What it had actually been was a demonstration of where the institutional knowledge was not stored. Now it was stored in the right place.
The model is an engine. Engines are interchangeable. The knowledge in your files is not.
That's what AI Heroes builds. Not platform-dependent setups. Institutional knowledge architecture — the files, the skills, and the feedback loops that make your expertise portable, durable, and compounding. The kind of system where the AI is the least important component, and the knowledge is the asset that actually matters.
The agent built for this

AI Company Brain
The shared memory every AI system and agent you use runs on.
Meet AI Company BrainFrequently Asked Questions

Founder, AI Heroes
I build AI companies and the systems inside them. At AI Heroes, we give businesses the functional capacity to grow without the headcount growth normally demands — sales that follows up, marketing that runs, content that ships, ops that handles itself. We audit where you're leaving growth on the table, build the team that captures it, and hand it over completely.
I've built at scale before. Leading product and GTM at SlideSpeak AI (1M+ monthly users, profitable, bootstrapped). CPO at Disperse — the AI construction platform that went from 3 to 200+ people on $35M raised. I also co-founded LOBOMAR, a luxury fashion label featured in Elle, Cosmopolitan, and the LA Times, with shows at the London Design Museum, Wereldmuseum, and Amsterdam Fashion Week.
Related Articles
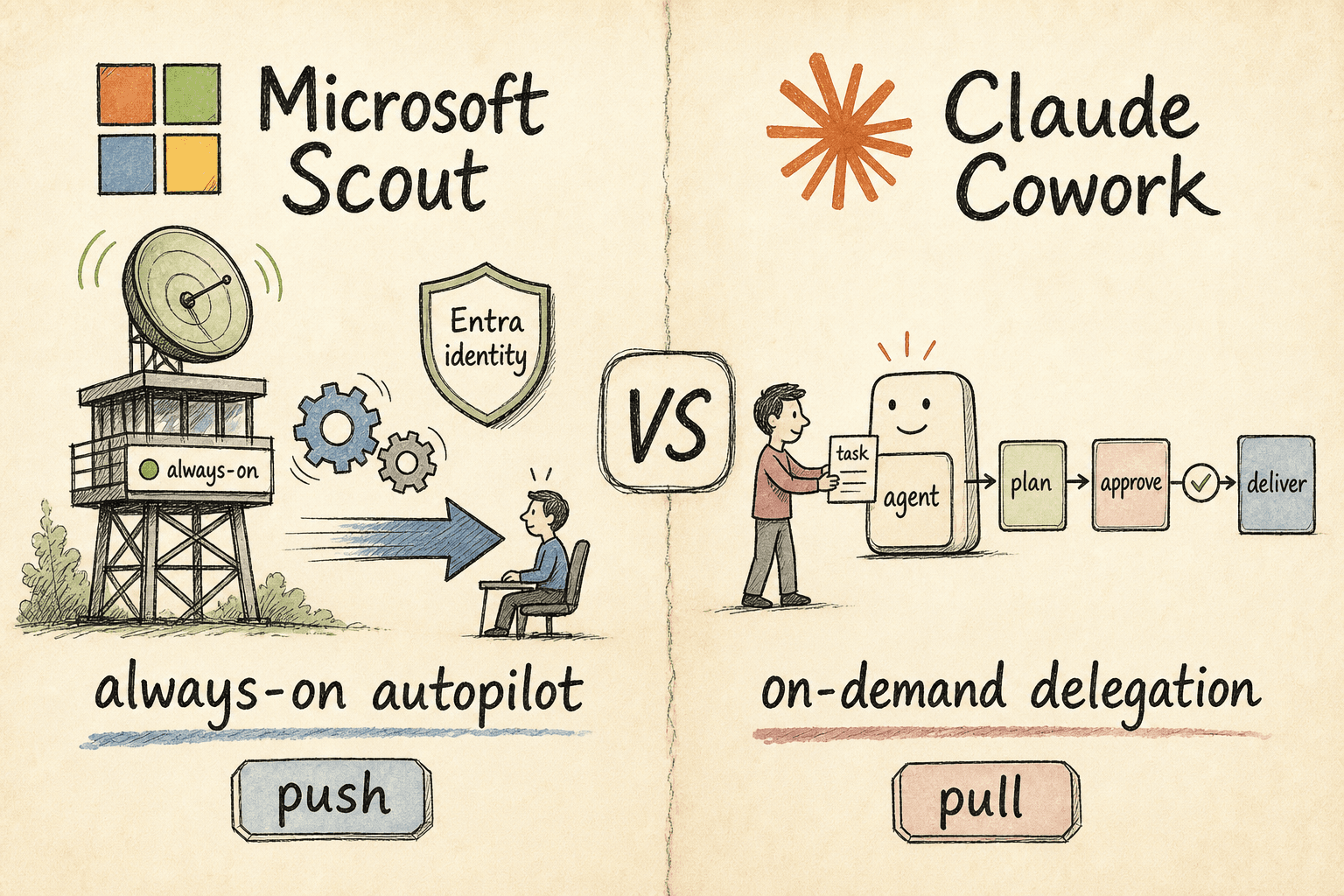
Microsoft Scout vs Claude Cowork: Autopilot or Delegation?
Two of 2026's biggest agent launches make opposite bets. Microsoft Scout is a desktop autopilot that runs in the background and acts on your behalf; Claude Cowork waits for you to hand it a task, then delivers. One is push, the other pull — here's which fits your team.

How to Get Started with Claude Cowork: A Decision Framework for Knowledge Workers (2026)
Claude Cowork is where you delegate a whole task instead of asking a question — point it at your files and apps, describe the outcome, get finished work. The hard part isn't the prompt, it's knowing which tasks to hand it. Here's a 5-signal fit test, the three shapes a Cowork task can take, and how to get your first deliverable in ten minutes.

Anthropic's Sales Team on Claude Cowork: An AI-Augmented Sales Operations Layer in Practice
Travis Bryant, Head of US Mid-Market GTM at Anthropic, runs a 4,000-account book using Claude Cowork as the AI-augmented sales operations layer on top of Salesforce and BigQuery. Daily call prep, Friday forecast rollup in leadership's expected format, and overnight territory scoring that used to take hundreds of hours. The lesson is the architecture, not the chat — what an AI-augmented sales operations layer actually looks like when the CRM stays the system of record.